
Caffe實現多標籤影象分類(1)——基於Python介面實現多標籤影象分類(VOC2012)
1.前言
Caffe可以通過LMDB或LevelDB資料格式實現影象資料及標籤的輸入,不過這隻限於單標籤影象資料的輸入。由於研究生期間所從事的研究是影象標註領域,在進行影象標註時,每幅影象都是多標籤的,因此在使用Caffe進行遷移學習時需要實現多標籤影象資料的輸入。走過許多彎路,要畢業了,現在將這種比較實用的方法做一下總結方便後面學弟學妹的學習。
經過百度查詢,發現目前的主流做法有兩種:1、修改Caffe的C++原始碼實現多標籤資料的輸入,如果不是C++大神建議不要輕易嘗試,很容易最後你的Caffe也被你改崩了;2、使用HDF5資料實現多標籤資料的輸入(標籤資料是一組0和1組成的向量),利用Caffe的Slice層實現標籤資料的提取,依次為每個類別構建一個num_out=2的全連線層,也就是為每個類別構建一個二分類器,判別這幅影象是否包含這個標註詞,這種方法小類別影象資料時可以試試,當影象類別過高時就很難受了,當時我寫這些二分類器都要哭了。
後來偷了個懶,採用了簡單複製的策略,即一幅影象包含幾個標籤就將這張影象複製幾次,每次讓它對應不同的標籤,這種方法賊簡單,其實不需複製影象,就是在生成LMDB檔案的txt檔案上略作修改即可。
2.VOC2012資料集
3.基於Python介面的Caffe多標籤的實現
這些程式碼時一體的,這裡將其分成幾部分,建議讀者也是分成這幾部分一步一步的執行,這樣方便理解程式碼的用意,這些段組起來就是完整的流程。執行時強烈建議實用CMD視窗執行,CMD視窗執行時如果是網路檔案有誤會顯示網路檔案的錯誤,同時也可以看見網路執行時的Loss值以及迭代次數。用python的IDE執行只能看見每迭代100次的準確率,而且如果網路檔案有問題它不會報錯,只會提示程序死了,無從下手去修改。
3.1匯入程式碼要用的包
import sys import os import numpy as np import os.path as osp import matplotlib.pyplot as plt from copy import copy # 用於顯示影象 plt.rcParams['figure.figsize'] = (6, 6) # 匯入Caffe import caffe from caffe import layers as L, params as P # 新增路徑這裡面有網路和程式碼執行的檔案(python的data層以及下面匯入的tools) sys.path.append(r"D:\caffe-master\examples\pycaffe") sys.path.append(r"D:\caffe-master\examples\pycaffe\layers") import tools transformer = tools.SimpleTransformer() # 資料集路徑 pascal_root = r"E:\VOC2012" # 資料集內影象標籤的類別 classes = np.asarray(['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']) # 指定權重檔案的路徑 if not os.path.isfile(r'D:\caffe-master\models\bvlc_reference_caffenet\bvlc_reference_caffenet.caffemodel'): print("Please downloading pre-trained CaffeNet model...") # 設定網路訓練的方式為GPU訓練 caffe.set_mode_gpu()
sys.path.append(r"D:\caffe-master\examples\pycaffe")
要用到這個資料夾下的tools.py,實現影象資料的預處理。建議看一下這個檔案,方便後面為自己的資料集定製影象資料處理的檔案。
sys.path.append(r"D:\caffe-master\examples\pycaffe\layers")
要呼叫這個資料夾下的pascal_multilabel_datalayers.py實現網路資料的輸入。建議看一下這個檔案,方便後面為自己的資料集定製影象資料輸入的檔案。
3.2生成網路執行所用的網路檔案和Solver檔案
# 定義用於生成卷積層的函式
def conv_relu(bottom, ks, nout, stride=1, pad=0, group=1):
conv = L.Convolution(bottom, kernel_size=ks, stride=stride,
num_output=nout, pad=pad, group=group)
return conv, L.ReLU(conv, in_place=True)
# 定義用於生成全連線層的函式
def fc_relu(bottom, nout):
fc = L.InnerProduct(bottom, num_output=nout)
return fc, L.ReLU(fc, in_place=True)
# 定義用於生成池化層的函式
def max_pool(bottom, ks, stride=1):
return L.Pooling(bottom, pool=P.Pooling.MAX, kernel_size=ks, stride=stride)
# 定義生成CaffeNet網路結構的函式
def caffenet_multilabel(data_layer_params, datalayer):
# 生成Python的data layer
n = caffe.NetSpec()
n.data, n.label = L.Python(module = 'pascal_multilabel_datalayers', layer = datalayer,
ntop = 2, param_str=str(data_layer_params))
# CaffeNet所包含的各層
n.conv1, n.relu1 = conv_relu(n.data, 11, 96, stride=4)
n.pool1 = max_pool(n.relu1, 3, stride=2)
n.norm1 = L.LRN(n.pool1, local_size=5, alpha=1e-4, beta=0.75)
n.conv2, n.relu2 = conv_relu(n.norm1, 5, 256, pad=2, group=2)
n.pool2 = max_pool(n.relu2, 3, stride=2)
n.norm2 = L.LRN(n.pool2, local_size=5, alpha=1e-4, beta=0.75)
n.conv3, n.relu3 = conv_relu(n.norm2, 3, 384, pad=1)
n.conv4, n.relu4 = conv_relu(n.relu3, 3, 384, pad=1, group=2)
n.conv5, n.relu5 = conv_relu(n.relu4, 3, 256, pad=1, group=2)
n.pool5 = max_pool(n.relu5, 3, stride=2)
n.fc6, n.relu6 = fc_relu(n.pool5, 4096)
n.drop6 = L.Dropout(n.relu6, in_place=True)
n.fc7, n.relu7 = fc_relu(n.drop6, 4096)
n.drop7 = L.Dropout(n.relu7, in_place=True)
n.score = L.InnerProduct(n.drop7, num_output=20)
n.loss = L.SigmoidCrossEntropyLoss(n.score, n.label)
return str(n.to_proto())
# 定義用於儲存網路檔案與solver檔案的路徑
workdir = r"D:\caffe-master\data\VOC2012"
if not os.path.isdir(workdir):
os.makedirs(workdir)
# 生成Solver檔案
solverprototxt = tools.CaffeSolver(trainnet_prototxt_path = r"D:/caffe-master/data/VOC2012/trainnet.prototxt", testnet_prototxt_path = r"D:/caffe-master/data/VOC2012/valnet.prototxt")
solverprototxt.sp['display'] = "1"
solverprototxt.sp['base_lr'] = "0.0001"
solverprototxt.write(osp.join(workdir, 'solver.prototxt'))
# 生成用於訓練的網路檔案.
with open(osp.join(workdir, 'trainnet.prototxt'), 'w') as f:
# 設定data層的引數
data_layer_params = dict(batch_size = 128, im_shape = [227, 227], split = 'train', pascal_root = pascal_root)
f.write(caffenet_multilabel(data_layer_params, 'PascalMultilabelDataLayerSync'))
# 生成用於驗證的網路檔案.
with open(osp.join(workdir, 'valnet.prototxt'), 'w') as f:
data_layer_params = dict(batch_size = 128, im_shape = [227, 227], split = 'val', pascal_root = pascal_root)
f.write(caffenet_multilabel(data_layer_params, 'PascalMultilabelDataLayerSync'))
執行這段程式碼,會在指定的資料夾下生成trainnet.prototxt、valnet.prototxt和solver.prototxt檔案

生成網路的data層如下所示:

生成網路的Loss層如下所示:

網路檔案除data層與loss層與CaffeNet的網路結構不同外,其它層與經典的CaffeNet的結構一模一樣,Caffe沒有多標籤的accuracy層,因此網路中沒有accuracy層。
3.3測試輸入的資料是否正確
# 匯入網路執行的solver檔案
solver = caffe.SGDSolver(osp.join(workdir, 'solver.prototxt'))
# 匯入權重檔案
solver.net.copy_from(r'D:\caffe-master\models\bvlc_reference_caffenet\bvlc_reference_caffenet.caffemodel')
solver.test_nets[0].share_with(solver.net)
# 網路執行1次
solver.step(1)
#用於檢測匯入的資料是否正確
#提取batch中的第一幅影象,並顯示影象與其對應的標籤
image_index = 0
plt.figure()
plt.imshow(transformer.deprocess(copy(solver.net.blobs['data'].data[image_index, ...])))
gtlist = solver.net.blobs['label'].data[image_index, ...].astype(np.int)
plt.title('GT: {}'.format(classes[np.where(gtlist)]))
plt.axis('off');
gtlist = solver.net.blobs['label'].data[image_index, ...].astype(np.int)
這句程式碼的意思是提取網路data層所輸出一個batch中的第一幅影象的label資料。
這段程式碼執行結果如下所示:

3.3訓練網路
由於Caffe不提供多標籤的accuracy層,因此需要自己寫一個判斷準確率的函式。這裡不對這個準去率判別函式進行推導了,個人覺得,沒有準確率的話,可以看Loos值啊,只要Loss值一直在下降就可以了。感興趣的可以自己推一下這個國外老哥寫的準確率函式的原理。
#測試準確率
#計算預測資料與真實資料相同的個數,佔總個數的比例
def hamming_distance(gt, est):
return sum([1 for (g, e) in zip(gt, est) if g == e]) / float(len(gt))
#這裡的batch_size就是設定驗證網路的batch_size
def check_accuracy(net, num_batches, batch_size = 128):
acc = 0.0
for t in range(num_batches):
net.forward()
gts = net.blobs['label'].data
ests = net.blobs['score'].data > 0
for gt, est in zip(gts, ests):
acc += hamming_distance(gt, est)
return acc / (num_batches * batch_size)
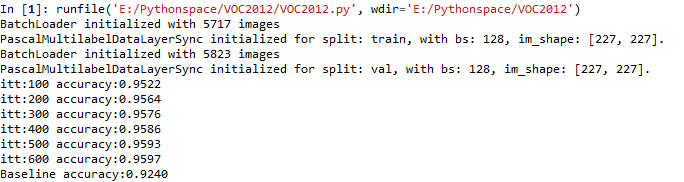
for itt in range(6):
solver.step(100)
# 這裡計算50個batch的平均準確率
print 'itt:{:3d}'.format((itt + 1) * 100), 'accuracy:{0:.4f}'.format(check_accuracy(solver.test_nets[0], 50))
#檢測基本準確率
#這裡的batch_size就是設定驗證網路的batch_size
def check_baseline_accuracy(net, num_batches, batch_size = 128):
acc = 0.0
for t in range(num_batches):
net.forward()
gts = net.blobs['label'].data
ests = np.zeros((batch_size, len(gts)))
for gt, est in zip(gts, ests):
acc += hamming_distance(gt, est)
return acc / (num_batches * batch_size)
#個人認為這裡的5823是指驗證集內所包含的影象數
print 'Baseline accuracy:{0:.4f}'.format(check_baseline_accuracy(solver.test_nets[0], 5823/128))
#測試訓練的網路
#取5幅影象測試一下訓練網路的結果
test_net = solver.test_nets[0]
for image_index in range(5):
plt.figure()
plt.imshow(transformer.deprocess(copy(test_net.blobs['data'].data[image_index, ...])))
gtlist = test_net.blobs['label'].data[image_index, ...].astype(np.int)
#將最後一層輸出數值大於0的標籤定義為影象的標籤
estlist = test_net.blobs['score'].data[image_index, ...] > 0
plt.title('GT: {} \n EST: {}'.format(classes[np.where(gtlist)], classes[np.where(estlist)]))
plt.axis('off')
plt.show()程式碼執行結果如下所示下(GT:標準答案,EST:模型預測答案):





使用python的data層與SigmoidCrossEntropyLoss損失函式可以實現影象多標籤分類,主要是這種方法十分簡單。網路模型只迭代訓練了600次,因此有可能網路精調的還不充分。大部分影象還是可以預測出所包含的標籤的,還是有少數影象無法預測出標籤,因為程式碼最後顯示5幅影象的預測標籤是選取分類分數大於0的位置作為預測標籤,這裡的score層輸出沒有經過Softmax處理,所以才會有的影象未顯示出標籤。通常情況下多分類標籤結果都是取經過Softmax處理後的最後一層(本文是score層)輸出結果的Top-N作為影象的類別。
這是在學習過程中的一點個人見解,如果理解有誤,懇請批評指正。
下一篇部落格裡,會介紹如何實現自己的一個多標籤影象資料集的多分類訓練,看過tools.py與pascal_multilabel_datalayers.py的讀者,只需為目標資料集仿製tools.py與xxxx_multilabel_datalayers.py即可實現基於Caffe的多標籤影象分類。