
機器學習實戰——樸素貝葉斯
1 模型介紹
1.1 樸素貝葉斯分類器
樸素貝葉斯是基於貝葉斯定理及特徵條件獨立的假設來實現分類的方法,就是在已知先驗概率的前提下,求後驗概率的最大值。
設樣本集合為 ,其屬性集合為 ,即某一樣本的特徵屬性數目為 ,對應的類標記(標籤)為 ,則特徵集合 具有類標記 的條件概率可以表示為:
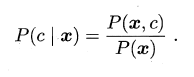 基於貝葉斯定理,等價於如下形式
基於貝葉斯定理,等價於如下形式
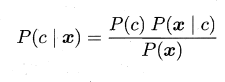
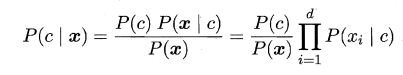 其中 為屬性數目,為 在第 個屬性上的取值。
由上式可知, 與類標記無關,要求條件概率 的最大值,只需要求分子的最大值,即:
其中 為屬性數目,為 在第 個屬性上的取值。
由上式可知, 與類標記無關,要求條件概率 的最大值,只需要求分子的最大值,即:
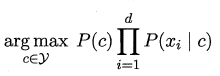
1.2 樸素貝葉斯的引數估計
一般可以使用兩種方法對其引數進行估計,即:極大似然估計與貝葉斯估計。
極大似然引數估計:依據上述求最大值的公式
利用樣本的已知先驗概率來計算最大的後驗概率。
貝葉斯引數估計:利用極大似然估計可能會出現所要估計的概率值為 0 的情況(某一屬性在樣本集中沒有出現,無論其它屬性多明顯的表明所屬的類別,但連乘計算的概率值都為 0 ),為了解決這一問題,可以引入合理的 ,其條件概率可以表示為:
2 樸素貝葉斯在Sklearn中的實現
根據處理 分佈所做的假設不同,在 scikit-learn中,一共有 3 個樸素貝葉斯的分類演算法類,分別是 GaussianNB,MultinomialNB 和 BernoulliNB 。這三個類適用的分類場景各不相同,一般來說,如果樣本特徵的分佈大部分是連續值,使用 GaussianNB 會比較好;如果如果樣本特徵的分大部分是多元離散值,使用 MultinomialNB 比較合適;而如果樣本特徵是二元離散值或者很稀疏的多元離散值,應該使用 BernoulliNB。
2.1 GaussianNB分類演算法
GaussianNB 實現了運用於分類的高斯樸素貝葉斯演算法。特徵的可能性(即概率)假設為高斯分佈:
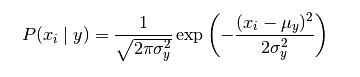
class sklearn.naive_bayes.GaussianNB(priors=None) priors:預設不給出,表示獲取各類別的先驗概率。
樸素貝葉斯在sklearn中的呼叫,與sklearn中其他機器學習方法的訓練與預測類似,但其有一個比較特殊的增量式訓練方法,另外兩個模型也有同樣的增量模型演算法:
partial_fit(X, y, classes=None, sample_weight=None):若訓練資料集資料量非常大,不能一次性全部載入記憶體時,可以將資料集劃分若干份,重複呼叫partial_fit線上學習模型引數,在第一次呼叫partial_fit函式時,必須制定classes引數(一般是訓練集的全部分類型別),在隨後的呼叫可以忽略。
import numpy as np
from sklearn.naive_bayes import GaussianNB
X = np.array([[-1, -1], [-2, -2], [-3, -3],[-4,-4],[-5,-5], [1, 1], [2,2], [3, 3]])
Y = np.array([1, 1, 1,1,1, 2, 2, 2])
# 定義樸素貝葉斯物件
clf = GaussianNB()
# 呼叫物件
clf.fit(X,Y)
# 測試資料
clf.predict([[-6,-6],[4,5]])
# 呼叫增量訓練模型
clf_pf = GaussianNB()
clf_pf.partial_fit(X, Y, np.unique(Y))
clf_pf.predict([[-0.8, -1]])
2.2 MultinomialNB分類演算法
MultinomialNB 假設特徵的先驗概率為多項式分佈,即如下式:
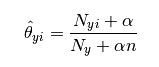
class sklearn.naive_bayes.MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None) alpha:浮點數,就是引入平滑的值 , 表示拉普拉斯平滑; fit_prior:表示先驗概率,預設True,學習先驗概率,如果是false,則所有的樣本類別輸出都有相同的類別先驗概率; class_prior:指定分類的先驗概率,預設為空;
import numpy as np
from sklearn.naive_bayes import MultinomialNB
X = np.random.randint(5, size=(6, 100))
y = np.array([1, 2, 3, 4, 5, 6])
clf = MultinomialNB()
clf.fit(X, y)
clf.predict(X[2:3])
2.3 BernoulliNB分類演算法
BernoulliNB 假設特徵的先驗概率為二元伯努利分佈,即如下式:
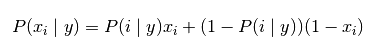
class sklearn.naive_bayes.BernoulliNB(alpha=1.0, binarize=0.0, fit_prior=True, class_prior=None) binarize:一個浮點數或者None,如果為浮點數則以該數值為界,特徵值大於它的取1,小於的為0 。如果為None,假定原始資料已經二值化 其它引數同上。
import numpy as np
from sklearn.naive_bayes import BernoulliNB
X = np.random.randint(2, size=(6, 100))
Y = np.array([1, 2, 3, 4, 4, 5])
clf = BernoulliNB()
clf.fit(X, Y)
clf.predict(X[2:3])