
SparkRDMA:使用RDMA技術提升Spark的Shuffle效能
Spark Shuffle 基礎
在 MapReduce 框架中,Shuffle 是連線 Map 和 Reduce 之間的橋樑,Reduce 要讀取到 Map 的輸出必須要經過 Shuffle 這個環節;而 Reduce 和 Map 過程通常不在一臺節點,這意味著 Shuffle 階段通常需要跨網路以及一些磁碟的讀寫操作,因此 Shuffle 的效能高低直接影響了整個程式的效能和吞吐量。
與 MapReduce 計算框架一樣,Spark 作業也有 Shuffle 階段,通常以 Shuffle 來劃分 Stage;而 Stage 之間的資料互動是需要 Shuffle 來完成的。整個過程圖如下所示:
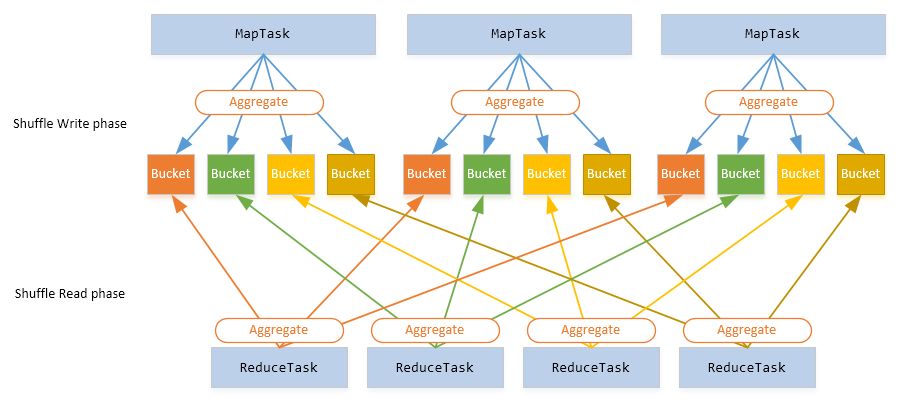
- 不管是 MapReduce 還是 Spark 作業,Shuffle 操作是很消耗資源的,這裡的資源包括:CPU、RAM、磁碟還有網路;
- 我們需要儘可能地避免 Shuffle 操作
而目前最新的 Spark(2.2.0) 內建只支援一種 Shuffle 實現:org.apache.spark.shuffle.sort.SortShuffleManager,通過引數 spark.shuffle.manager 來配置。這是標準的 Spark Shuffle 實現,其內部實現依賴了 Netty 框架。本文並不打算詳細介紹 Spark 內部 Shuffle 是如何實現的,這裡我要介紹社群對 Shuffle 的改進。
RDMA 技術
在進行下面的介紹之前,我們先來了解一些基礎知識。
傳統的 TCP Socket 資料傳輸需要經過很多步驟:資料先從源端應用程式拷貝到當前主機的 Sockets 快取區,然後再拷貝到 TransportProtocol Driver,然後到 NIC Driver,最後 NIC 通過網路將資料傳送到目標主機的 NIC,目標主機又經過上面步驟將資料傳輸到應用程式,整個過程如下:
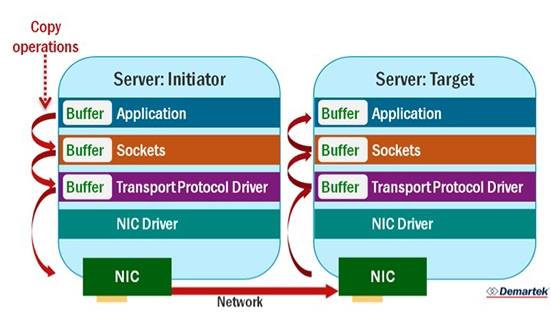 從上圖可以看出,網路資料的傳輸很大一部分時間用於資料的拷貝!如果需要傳輸的資料很大,那麼這個階段用的時間很可能佔整個作業執行時間的很大一部分!那麼有沒有一種方法直接省掉不同層的資料拷貝,使得目標主機直接從源端主機記憶體獲取資料?還真有,這就是 RDMA 技術!
從上圖可以看出,網路資料的傳輸很大一部分時間用於資料的拷貝!如果需要傳輸的資料很大,那麼這個階段用的時間很可能佔整個作業執行時間的很大一部分!那麼有沒有一種方法直接省掉不同層的資料拷貝,使得目標主機直接從源端主機記憶體獲取資料?還真有,這就是 RDMA 技術!
RDMA(Remote Direct Memory Access)技術全稱遠端直接記憶體訪問,是一種直接記憶體訪問技術,它將資料直接從一臺計算機的記憶體傳輸到另一臺計算機,無需雙方作業系統的介入。這允許高通量、低延遲的網路通訊,尤其適合在大規模平行計算機叢集中使用(本段摘抄自 維基百科 - 遠端直接記憶體訪問)。RDMA 有以下幾個特點:
- Zero-copy
- 直接硬體介面(Direct hardware interface),繞過核心和 TCP / IP 的 IO
- 亞微秒延遲
- Flow control and reliability is offloaded in hardware
所以利用 RDMA 技術進行資料傳輸看起來像下面一樣:
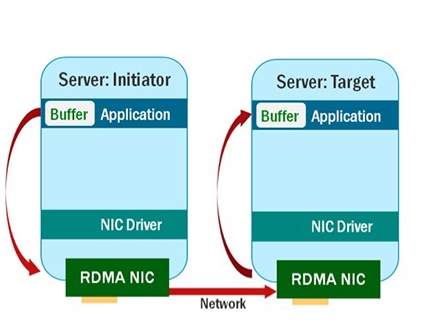 從上面看出,使用了 RDMA 技術之後,雖然源端主機和目標主機是跨網路的,但是他們之間的資料互動是直接從對方記憶體獲取的,這明顯會加快整個計算過程。
SparkRDMA
好,現在基礎的知識咱們已經獲取到了,我們正式進入本文主題。由 Mellanox Technologies 公司開發並開源的 SparkRDMA ShuffleManager (GitHub 地址:https://github.com/Mellanox/SparkRDMA)就是採用 RDMA 技術,使得 Spark 作業在 Shuffle 資料的時候使用 RDMA 方式,而非標準的 TCP 方式。在 SparkRDMA 的官方 Wiki 裡面有如下介紹:
從上面看出,使用了 RDMA 技術之後,雖然源端主機和目標主機是跨網路的,但是他們之間的資料互動是直接從對方記憶體獲取的,這明顯會加快整個計算過程。
SparkRDMA
好,現在基礎的知識咱們已經獲取到了,我們正式進入本文主題。由 Mellanox Technologies 公司開發並開源的 SparkRDMA ShuffleManager (GitHub 地址:https://github.com/Mellanox/SparkRDMA)就是採用 RDMA 技術,使得 Spark 作業在 Shuffle 資料的時候使用 RDMA 方式,而非標準的 TCP 方式。在 SparkRDMA 的官方 Wiki 裡面有如下介紹:
SparkRDMA is a high-performance, scalable and efficient ShuffleManager plugin for Apache Spark. It utilizes RDMA (Remote Direct Memory Access) technology to reduce CPU cycles needed for Shuffle data transfers. It reduces memory usage by reusing memory for transfers instead of copying data multiple times down the traditional TCP-stack.
可以看出,SparkRDMA 就是擴充套件了 Spark 的 ShuffleManager 介面,並且採用了 RDMA 技術。在測試的結果顯示,採用 RDMA 進行 Shuffle 資料比標準的方式快 2.18 倍!
 SparkRDMA 開發者們給 Spark 社群提交了一個 Issue:[SPARK-22229] SPIP: RDMA Accelerated Shuffle Engine,詳細的設計文件:這裡。不過從社群的回覆來看,最少目前不會整合到 Spark 程式碼中去。
SparkRDMA 開發者們給 Spark 社群提交了一個 Issue:[SPARK-22229] SPIP: RDMA Accelerated Shuffle Engine,詳細的設計文件:這裡。不過從社群的回覆來看,最少目前不會整合到 Spark 程式碼中去。
安裝使用
如果你想使用 SparkRDMA,我們需要 Apache Spark 2.0.0/2.1.0/2.2.0、Java 8 以及支援 RDMA 技術的網路(比如:RoCE 和 Infiniband)。
SparkRDMA 官方為不同版本的 Spark 預先編譯好相應的 jar 包,我們可以訪問 這裡 下載。解壓之後會得到以下四個檔案:
- spark-rdma-1.0-for-spark-2.0.0-jar-with-dependencies.jar
- spark-rdma-1.0-for-spark-2.1.0-jar-with-dependencies.jar
- spark-rdma-1.0-for-spark-2.2.0-jar-with-dependencies.jar
除了 libdisni.so 檔案一定要安裝到 Spark 叢集的所有節點上,其他的 jar 包只需要根據我們的 Spark 版本進行選擇。相關的檔案部署好之後,我們需要將這個 SparkRDMA 模組加入到 Spark 的執行環境中去,如下設定:
spark.driver.extraClassPath /path/to/SparkRDMA/spark-rdma-1.0-for-spark-2.0.0-jar-with-dependencies.jar spark.executor.extraClassPath /path/to/SparkRDMA/spark-rdma-1.0-for-spark-2.0.0-jar-with-dependencies.jar
為了啟用 SparkRDMA Shuffle Manager 外掛,我們還需要修改 spark.shuffle.manager 的值,只需要在 $SPARK_HOME/conf/spark-defaults.conf 裡面加入以下的配合即可:
spark.shuffle.manager org.apache.spark.shuffle.rdma.RdmaShuffleManager
其他的就和正常使用 Spark 一樣。
我們需要將 libdisni.so 檔案分發到叢集的所有節點的同一目錄下,然後配置下面的環境:
export JAVA_LIBRARY_PATH=$JAVA_LIBRARY_PATH:/home/iteblog/spark-2.1.0-bin/rdma/
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/iteblog/spark-2.1.0-bin/rdma/
export SPARK_YARN_USER_ENV="JAVA_LIBRARY_PATH=$JAVA_LIBRARY_PATH,LD_LIBRARY_PATH=$LD_LIBRARY_PATH"
其中 /home/iteblog/spark-2.1.0-bin/rdma/ 存放了libdisni.so 檔案。執行的過程中可能還需要 libibverbs.so.1 和 librdmacm.so.1 檔案,可以通過下面命令解決
yum -y install libibverbs librdmacm
然後可以通過下面命令啟動 Spark:
bin/spark-shell --master yarn-client --driver-memory 18g --executor-memory 15g \
--queue iteblog --executor-cores 1 --num-executors 8 \
--conf "spark.yarn.dist.archives=/home/iteblog/spark-2.1.0-bin/rdma/rdma.tgz" \
--conf "spark.executor.extraLibraryPath=/home/iteblog/spark-2.1.0-bin/rdma/libdisni.so" \
--conf "spark.driver.extraLibraryPath=/home/iteblog/spark-2.1.0-bin/rdma/libdisni.so" \
--conf "spark.executor.extraClassPath=rdma.tgz/rdma/*" \
--conf "spark.driver.extraClassPath=/home/iteblog/spark-2.1.0-bin/rdma/*" \
--conf "spark.shuffle.manager=org.apache.spark.shuffle.rdma.RdmaShuffleManager"
不過如果你網路不支援 RDMA 技術,那麼就像我一樣會遇到下面的問題:
17/11/15 22:01:48 ERROR rdma.RdmaNode: Failed in RdmaNode constructor
17/11/15 22:01:48 ERROR spark.SparkContext: Error initializing SparkContext.
java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.spark.SparkEnv$.instantiateClass$1(SparkEnv.scala:265)
at org.apache.spark.SparkEnv$.create(SparkEnv.scala:323)
at org.apache.spark.SparkEnv$.createDriverEnv(SparkEnv.scala:174)
at org.apache.spark.SparkContext.createSparkEnv(SparkContext.scala:257)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:432)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2313)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:868)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:860)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:860)
at org.apache.spark.repl.Main$.createSparkSession(Main.scala:95)
at $line3.$read$$iw$$iw.<init>(<console>:15)
at $line3.$read$$iw.<init>(<console>:42)
at $line3.$read.<init>(<console>:44)
at $line3.$read$.<init>(<console>:48)
at $line3.$read$.<clinit>(<console>)
at $line3.$eval$.$print$lzycompute(<console>:7)
at $line3.$eval$.$print(<console>:6)
at $line3.$eval.$print(<console>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at scala.tools.nsc.interpreter.IMain$ReadEvalPrint.call(IMain.scala:786)
at scala.tools.nsc.interpreter.IMain$Request.loadAndRun(IMain.scala:1047)
at scala.tools.nsc.interpreter.IMain$WrappedRequest$$anonfun$loadAndRunReq$1.apply(IMain.scala:638)
at scala.tools.nsc.interpreter.IMain$WrappedRequest$$anonfun$loadAndRunReq$1.apply(IMain.scala:637)
at scala.reflect.internal.util.ScalaClassLoader$class.asContext(ScalaClassLoader.scala:31)
at scala.reflect.internal.util.AbstractFileClassLoader.asContext(AbstractFileClassLoader.scala:19)
at scala.tools.nsc.interpreter.IMain$WrappedRequest.loadAndRunReq(IMain.scala:637)
at scala.tools.nsc.interpreter.IMain.interpret(IMain.scala:569)
at scala.tools.nsc.interpreter.IMain.interpret(IMain.scala:565)
at scala.tools.nsc.interpreter.ILoop.interpretStartingWith(ILoop.scala:807)
at scala.tools.nsc.interpreter.ILoop.command(ILoop.scala:681)
at scala.tools.nsc.interpreter.ILoop.processLine(ILoop.scala:395)
at org.apache.spark.repl.SparkILoop$$anonfun$initializeSpark$1.apply$mcV$sp(SparkILoop.scala:38)
at org.apache.spark.repl.SparkILoop$$anonfun$initializeSpark$1.apply(SparkILoop.scala:37)
at org.apache.spark.repl.SparkILoop$$anonfun$initializeSpark$1.apply(SparkILoop.scala:37)
at scala.tools.nsc.interpreter.IMain.beQuietDuring(IMain.scala:214)
at org.apache.spark.repl.SparkILoop.initializeSpark(SparkILoop.scala:37)
at org.apache.spark.repl.SparkILoop.loadFiles(SparkILoop.scala:105)
at scala.tools.nsc.interpreter.ILoop$$anonfun$process$1.apply$mcZ$sp(ILoop.scala:920)
at scala.tools.nsc.interpreter.ILoop$$anonfun$process$1.apply(ILoop.scala:909)
at scala.tools.nsc.interpreter.ILoop$$anonfun$process$1.apply(ILoop.scala:909)
at scala.reflect.internal.util.ScalaClassLoader$.savingContextLoader(ScalaClassLoader.scala:97)
at scala.tools.nsc.interpreter.ILoop.process(ILoop.scala:909)
at org.apache.spark.repl.Main$.doMain(Main.scala:68)
at org.apache.spark.repl.Main$.main(Main.scala:51)
at org.apache.spark.repl.Main.main(Main.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:738)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:187)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:212)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:126)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.io.IOException: Unable to allocate RDMA Event Channel
at org.apache.spark.shuffle.rdma.RdmaNode.<init>(RdmaNode.java:67)
at org.apache.spark.shuffle.rdma.RdmaShuffleManager.<init>(RdmaShuffleManager.scala:181)
... 62 more
java.io.IOException: Unable to allocate RDMA Event Channel
at org.apache.spark.shuffle.rdma.RdmaNode.<init>(RdmaNode.java:67)
at org.apache.spark.shuffle.rdma.RdmaShuffleManager.<init>(RdmaShuffleManager.scala:181)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.spark.SparkEnv$.instantiateClass$1(SparkEnv.scala:265)
at org.apache.spark.SparkEnv$.create(SparkEnv.scala:323)
at org.apache.spark.SparkEnv$.createDriverEnv(SparkEnv.scala:174)
at org.apache.spark.SparkContext.createSparkEnv(SparkContext.scala:257)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:432)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2313)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:868)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:860)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:860)
at org.apache.spark.repl.Main$.createSparkSession(Main.scala:95)
... 47 elided
這樣的話那就沒法測試了,哈哈。。如果真要使用 RDMA ,諮詢你公司的 OPS 如何配置這個吧。