
大資料之ElasticSearch
寫在前面
1. 著力於本質,才能通萬物——重點在於分析其內在原理,對於普通的操作不做太詳細的學習。
目錄
-
一、定義
1. 基於Apache Lucene的分散式多使用者能力的全文搜尋引擎
2. 採用RESTful風格來命名自己的API
4. 常用動詞:GET/PUT/POST/DELETE
5. 分而治之,一切為了更高的查詢效能
-
二、 基本概念
1. 索引(Index):Elastic 資料管理的頂層單位即 Index(索引),是單個數據庫的同義詞。每個 Index (即資料庫)的名字必須是小寫。
2. 文件(Document)
欄位(Field):文件的一個Key/Value對;
詞(Term):表示文字中的一個單詞;
標記(Token):表示在欄位中出現的詞,由該詞的文字、偏移量(開始和結束)以及型別組成;
3. 文件型別(Type):Document 的分組即Type,不同的Type應該有相似的結構(schema)。
4. 節點(Node):單獨一個ElasticSearch伺服器例項稱為一個節點。
5. 叢集(Cluster)
6. 分片索引(Shard):叢集能夠儲存超出單機容量的資訊。為了實現這種需求,ElasticSearch把資料分發到多個儲存Lucene索引的物理機上。這些Lucene索引稱為分片索引,這個分發的過程稱為索引分片(Sharding)。
7. 索引副本(Replica):當叢集負載增長,使用者搜尋請求可能會阻塞在單個節點上時,通過索引副本(Replica)機制就可以解決這個問題。在提供基礎查詢效能的同時,也保證了資料的安全性。即如果主分片資料丟失,ElasticSearch通過索引副本使得資料不丟失。索引副本可以隨時新增或者刪除,所以使用者可以在需要的時候動態調整其數量。
8. 網管(Gateway):ES執行過程中需要的所有資料(文件,狀態、索引引數等)都被儲存在Gateway中。
-
三、技術架構
查詢分為兩個階段:分散階段(scatter phase)和合並階段(gather phase)。在分散階段將查詢分發到包含相關文件的多個分片中去執行查詢,而在合併階段則從眾多分片中收集返回結果,然後對它們進行合併、排序,進行後續處理,然後返回給客戶端。
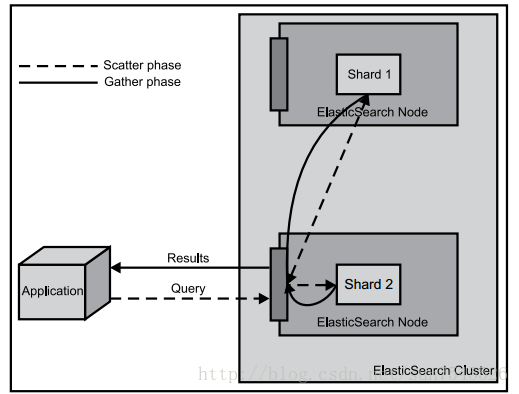
(一) 分片/副本策略
1. 為支援大量資料,索引會按某個維度分成多個部分,每個部分就是一個分片(Shard)。一個節點(Node)一般會管理多個分片。
2. 同一個索引分片通常會分佈到不同節點(Node)上。分片有兩種,分別是主分片(Primary)和副本分片(Replica)。注意,建索引操作只會發生在主分片上,而不是副本上。
(二)MasterNode、DataNode、TransportNode
混合部署
1. DataNode 和 TransportNode 混合,每一個節點既存分片又存全域性路由表。
2. 優勢: 簡單、易上手;
3. 缺點:多種請求會相互影響,大叢集中如果某一個節點出現問題,就會影響途徑這個DataNode的所有其他跨Node請求;沒辦法熱更新。
分層部署
1. 部分節點專門做請求轉發和結果合併(TransportNode);部分節點專門做資料處理(DataNode);
2. 好處就是角色相互獨立,不會相互影響,一般Transport Node的流量是平均分配的,很少出現單臺機器的CPU或流量被打滿的情況,而DataNode由於處理資料,很容易出現單機資源被佔滿,比如CPU,網路,磁碟等。獨立開後,DataNode如果出了故障只是影響單節點的資料處理,不會影響其他節點的請求,影響限制在最小的範圍內。
(三)路由策略
路由分層,共四層:RountingTable、IndexRoutingTable、IndexShardRountingTable、ShardRountingTable。
-
四、資料儲存結構
(一) ElasticSearch可以儲存結構和非結構的資料。
(二) 倒排索引(敲黑板,劃重點)
1. 普通關係型資料庫通常採用BTree索引,而ES採用的是倒排索引。思路:
將磁盤裡的東西儘量搬進記憶體,減少磁碟隨機讀取次數(同時也利用磁碟順序讀特性),結合各種奇技淫巧的壓縮演算法,用及其苛刻的態度使用記憶體。
2. ES將Document直接進行儲存?
No~首先將Doc進行分詞,然後儲存詞條以及詞條和文件之間的對映關係(Postings List)。
3. 這麼簡單的詞條(Term)儲存可以造就ES檢索的高效率嗎?
No~把記憶體用到極致才是優秀的檢索。
ES建立了Term Index-->Term Dictionary-->Term Position的儲存/檢索方式。
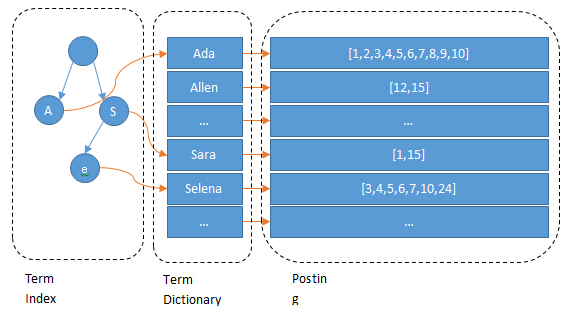
Term Index:採用FST (Finite State Transducer)結構,像一棵樹,這棵樹不會包含所有的term,它包含的是term的一些字首。通過term index可以快速地定位到term dictionary的某個offset,然後從這個位置再往後順序查詢。同時,可以使term index快取到記憶體中。
Term Dictionary:Term詞典,用於定位到Postinglist。
Posting List:會其進行壓縮——順序儲存,增量編碼壓縮,將大數變小數,按位元組儲存。
(三) 那麼是不是所有的索引都需要被分詞儲存的呢?——顯然不是。
1. 當index為analyzed時,該欄位是分析欄位,ElasticSearch引擎對該欄位執行分析操作,把文字分割成分詞流,儲存在倒排索引中,使其支援全文搜尋; 2. 當index為not_analyzed時,該欄位不會被分析,ElasticSearch引擎把原始文字作為單個分詞儲存在倒排索引中,不支援全文搜尋,但是支援詞條級別的搜尋;也就是說,欄位的原始文字不經過分析而儲存在倒排索引中,把原始文字編入索引,在搜尋的過程中,查詢條件必須全部匹配整個原始文字; 3. 當index為no時,該欄位不會被儲存到倒排索引中,不會被搜尋到;
-
五、搜尋
- 啊啊