
常用字符集編碼詳解 ASCII GB2312 GBK GB18030 UTF-8 unicode
ASCII ASCII碼是7位編碼,編碼範圍是0x00-0x7F。ASCII字符集包括英文字母、阿拉伯數字和標點符號等字元。其中0x00-0x20和0x7F共33個控制字元。只支援ASCII碼的系統會忽略每個位元組的最高位,只認為低7位是有效位。HZ字元編碼就是早期為了在只支援7位ASCII系統中傳輸中文而設計的編碼。早期很多郵件系統也只支援ASCII編碼,為了傳輸中文郵件必須使用BASE64或者其他編碼方式。GB2312 GB2312是基於區位碼設計的,區位碼把編碼表分為94個區,每個區對應94個位,每個字元的區號和位號組合起來就是該漢字的區位碼。區位碼一般 用10進位制數來表示,如1601就表示16區1位,對應的字元是“啊”。在區位碼的區號和位號上分別加上0xA0就得到了GB2312編碼。區位碼中01-09區是符號、數字區,16-87區是漢字區,10-15和88-94是未定義的空白區。它將收錄的漢字分成兩級:第一級是常用漢字計3755個,置於16-55區,按漢語拼音字母/筆形順序排列;第二級漢字是次常用漢字計3008個,置於56-87區,按部首/筆畫順序排列。一級漢字是按照拼音排序的,這個就可以得到某個拼音在一級漢字區位中的範圍,很多根據漢字可以得到拼音的程式就是根據這個原理編寫的。GB2312字符集中除常用簡體漢字字元外還包括希臘字母、日文平假名及片假名字母、俄語西裡爾字母等字元,未收錄繁體中文漢字和一些生僻字。可以用繁體漢字測試某些系統是不是隻支援GB2312編碼。GB2312的編碼範圍是0xA1A1-0x7E7E,去掉未定義的區域之後可以理解為實際編碼範圍是0xA1A1-0xF7FE。 EUC-CN可以理解為GB2312的別名,和GB2312完全相同。 區位碼更應該認為是字符集的定義,定義了所收錄的字元和字元位置,而GB2312及EUC-CN是實際計算機環境中支援這種字符集的編碼。HZ和ISO-2022-CN是對應區位碼字符集的另外兩種編碼,都是用7位編碼空間來支援漢字。區位碼和GB2312編碼的關係有點像 Unicode和UTF-8。GBK
 Windows中CP936內碼表使用0x80來表示歐元符號,而在GB18030編碼中沒有使用0x80編碼位,用其他位置來表示歐元符號。這可以理解為是GB18030向下相容性上的一點小問題;也可以理解為0x80是CP936對GBK的擴充套件,而GB18030只是和GBK相容良好。
Windows中CP936內碼表使用0x80來表示歐元符號,而在GB18030編碼中沒有使用0x80編碼位,用其他位置來表示歐元符號。這可以理解為是GB18030向下相容性上的一點小問題;也可以理解為0x80是CP936對GBK的擴充套件,而GB18030只是和GBK相容良好。GB18032版本
GB18030目前的最新版本是GB18030-2005。GB18030-2005與GB18030-2000的編碼體系結構是完全相同的。那麼,GB18030的2000版和2005版有什麼區別和聯絡呢?
2000年釋出的GB18030-2000,全名是《資訊科技 漢字編碼字符集 基本集的擴充》。GB18030-2000僅規定了常用非漢字元號和27533個漢字(包括部首、部件等)的編碼。 GB18030-2000是全文強制性標準,市場上銷售的產品必須符合。2005年釋出的GB18030-2005在GB18030-2000的基礎上增加了42711個漢字和多種我國少數民族文字的編碼,增加的這些內容是推薦性的。原GB18030-2000中的內容是強制性的,市場上銷售的產品必須符合。故GB18030-2005為部分強制性標準,自發布之日起代替GB18030-2000。如下表所示,GB18030-2000收錄了27533個漢字:
| 類別 | 碼位範圍 | 碼位數 | 字元數 | 字元型別 |
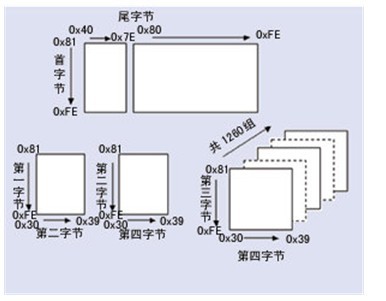
| 雙位元組部分 | 第一位元組 0xB0-0xF7 第二位元組 0xA1-0xFE | 6768 | 6763 | 漢字 |
| 第一位元組0x81-0xA0 第二位元組0x40-0xFE | 6080 | 6080 | 漢字 | |
| 第一位元組0xAA-0xFE 第二位元組0x40-0xA0 | 8160 | 8160 | 漢字 | |
| 四位元組部分 | 第一位元組0x81-0x82 第二位元組0x30-0x39 第三位元組0x81-0xFE 第四位元組0x30-0x39 | 6530 | 6530 | CJK統一漢字擴充A |
如下表所示,GB18030-2005收錄了70244個漢字:
| 類別 | 碼位範圍 | 碼位數 | 字元數 | 字元型別 |
| 雙位元組部分 | 第一位元組 0xB0-0xF7 第二位元組 0xA1-0xFE | 6768 | 6763 | 漢字 |
| 第一位元組0x81-0xA0 第二位元組0x40-0xFE | 6080 | 6080 | 漢字 | |
| 第一位元組0xAA-0xFE 第二位元組0x40-0xA0 | 8160 | 8160 | 漢字 | |
| 四位元組部分 | 第一位元組0x81-0x82 第二位元組0x30-0x39 第三位元組0x81-0xFE 第四位元組0x30-0x39 | 6530 | 6530 | CJK統一漢字擴充A |
| 第一位元組0x95-0x98 第二位元組0x30-0x39 第三位元組0x81-0xFE 第四位元組0x30-0x39 | 42711 | 42711 | CJK統一漢字擴充B |
GB18030-2005相對於GB18030-2000主要有以下變化:
1、在四位元組字元表中增加CJK統一漢字擴充B和已經在GB13000中編碼的我國少數民族文字字元的字形。其實GB18030-2000已經映射了這些碼位,但GB18030-2000沒有給出這些字元的字形。 2、調整字元?的編碼。 3、去掉了單位元組編碼的歐元符號(0x80)。 (糾正:在GB18030-2000中已經去掉了單位元組編碼的歐元符號,證據見GB18030-2000的標準文字)unicode 每一種語言的不同的編碼頁,增加了那些需要支援不同語言的軟體的複雜度。因而人們制定了一個世界標準,叫做unicode。unicode為每個字元提供了唯一的特定數值,不論在什麼平臺上、不論在什麼軟體中,也不論什麼語言。也就是說,它世界上使用的所有字元都列出來,並給每一個字元一個唯一特定數值。 Unicode的最初目標,是用1個16位的編碼來為超過65000字元提供對映。但這還不夠,它不能覆蓋全部歷史上的文字,也不能解決傳輸的問題 (implantation head-ache's),尤其在那些基於網路的應用中。已有的軟體必須做大量的工作來程式16位的資料。 因此,Unicode用一些基本的保留字元制定了三套編碼方式。它們分別是UTF-8,UTF-16和UTF-32。正如名字所示,在UTF-8中,字元是以8位序列來編碼的,用一個或幾個位元組來表示一個字元。這種方式的最大好處,是UTF-8保留了ASCII字元的編碼做為它的一部分,例如,在UTF-8和ASCII中,“A”的編碼都是0x41. UTF-16和UTF-32分別是Unicode的16位和32位編碼方式。考慮到最初的目的,通常說的Unicode就是指UTF-16。在討論Unicode時,搞清楚哪種編碼方式非常重要。UTF-8 Unicode Transformation Format-8bit,允許含BOM,但通常不含BOM。是用以解決國際上字元的一種多位元組編碼,它對英文使用8位(即一個位元組),中文使用24為(三個位元組)來編碼。UTF-8包含全世界所有國家需要用到的字元,是國際編碼,通用性強。UTF-8編碼的文字可以在各國支援UTF8字符集的瀏覽器上顯示。如,如果是UTF8編碼,則在外國人的英文IE上也能顯示中文,他們無需下載IE的中文語言支援包。