
DNA Consensus String
題目(中英對照):
DNA (Deoxyribonucleic Acid) is the molecule which contains the genetic instructions. It consists of four different nucleotides, namely Adenine, Thymine, Guanine, and Cytosine as shown in Figure 1. If we represent a nucleotide by its initial character, a DNA strand can be regarded as a long string (sequence of characters) consisting of the four characters A, T, G, and C. For example, assume we are given some part of a DNA strand which is composed of the following sequence of nucleotides:
DNA(脫氧核糖核酸)是含有遺傳指令的分子。 它由四種不同組成核苷酸,即腺嘌呤,胸腺嘧啶,鳥嘌呤和胞嘧啶,如圖1所示。如果我們代表核苷酸在它的初始特徵中,DNA鏈可以被視為由四個字元A,T,G和C組成的長字串(字元序列)。例如,假設我們給出了由DNA組成的一部分DNA鏈。 以下核苷酸序列:
“Thymine-Adenine-Adenine-Cytosine-Thymine-Guanine-Cytosine0-Cytosine-Guanine-Adenine-Thymine”
T-A-A-C-T-G-C-C-G-A-T
Then we can represent the above DNA strand with the string “TAACTGCCGAT.”
然後我們可以用字串“TAACTGCCGAT”表示上面的DNA鏈。
The biologist Prof. Ahn found that a gene X commonly exists in the DNA strands of five different kinds of animals, namely dogs, cats, horses, cows, and monkeys. He also discovered that the DNA sequences of the gene X from each animal were very alike. See Figure 2.
生物學家Ahn教授發現,基因X通常存在於五種不同動物的DNA鏈中,即狗,貓,馬,牛和猴。 他還發現每隻動物的基因X的DNA序列非常相似。 見圖2。
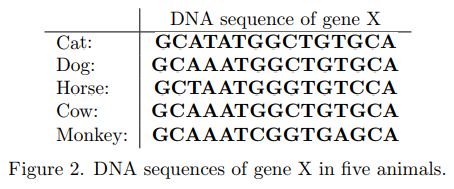
The Hamming distance is the number of different characters at each position from two strings of equal length. For example, assume we are given the two strings “AGCAT” and “GGAAT.” The Hamming distance of these two strings is 2 because the 1st and the 3rd characters of the two strings are different. Using the Hamming distance, we can define a representative string for a set of multiple strings of equal length. Given a set of strings S = {s1, . . . , sm} of length n, the consensus error between a string y of length n and the set S is the sum of the Hamming distances between y and each si in S. If the consensus error between y and S is the minimum among all possible strings y of length n, y is called a consensus string of S. For example, given the three strings “AGCAT” “AGACT” and “GGAAT” the consensus string of the given strings is “AGAAT” because the sum of the Hamming distances between “AGAAT” and the three strings is 3 which is minimal. (In this case, the consensus string is unique, but in general, there can be more than one consensus string.) We use the consensus string as a representative of the DNA sequence. For the example of Figure 2 above, a consensus string of gene X is “GCAAATGGCTGTGCA” and the consensus error is 7.
漢明距離是兩個相等長度的弦在每個位置的不同字元的數量。例如,假設我們給出兩個字串“AGCAT”和“GGAAT”。這兩個字串的漢明距離是2,因為兩個字串的第1個和第3個字元是不同的。使用漢明距離,我們可以為一組長度相等的多個字串定義代表性字串。給定一組字串S = {s1, . . . , sm}長度為n的字串y,長度為n的字串y和集合S之間的共識誤差是y與S中每個si之間的漢明距離之和。如果y和S之間的共識誤差是所有可能的最小值長度為n的字串y,y稱為S的共識字串。例如,給定三個字串“AGCAT”“AGACT”和“GGAAT”,給定字串的一致字符串是“AGAAT”,因為漢明距離的總和在“AGAAT”和三個字串之間是3,這是最小的。 (在這種情況下,共識字串是唯一的,但一般來說,可能存在多個共有字串。)我們使用共識字串作為DNA序列的代表。對於上面圖2的例子,基因X的共有字元是“GCAAATGGCTGTGCA”,共識錯誤是7。
輸入格式:
Your program is to read from standard input. The input consists of T test cases. The number of test cases T is given in the first line of the input. Each test case starts with a line containing two integers m and n which are separated by a single space. The integer m (4 ≤ m ≤ 50) represents the number of DNA sequences and n (4 ≤ n ≤ 1000) represents the length of the DNA sequences, respectively. In each of the next m lines, each DNA sequence is given.
您的程式是從標準輸入讀取。 輸入由T個測試用例組成。 測試用例T的數量在輸入的第一行給出。 每個測試用例以包含兩個整數m和n的行開始,這兩個整數由一個空格分隔。 整數m(4 ≤ m ≤ 50)表示DNA序列的數目,n(4≤n≤1000)分別表示DNA序列的長度。 在接下來的m行中的每一行中,給出每個DNA序列。
輸出格式:
Your program is to write to standard output. Print the consensus string in the first line of each case and the consensus error in the second line of each case. If there exists more than one consensus string, print the lexicographically smallest consensus string
你的程式是寫入標準輸出。 在每個案例的第一行列印共識字串,在每個案例的第二行列印共識錯誤。 如果存在多個共識字串,則列印按字典順序排列的最小共識字串
輸入樣例:
3
5 8
TATGATAC
TAAGCTAC
AAAGATCC
TGAGATAC
TAAGATGT
4 10
ACGTACGTAC
CCGTACGTAG
GCGTACGTAT
TCGTACGTAA
6 10
ATGTTACCAT
AAGTTACGAT
AACAAAGCAA
AAGTTACCTT
AAGTTACCAA
TACTTACCAA輸出樣例:
TAAGATAC
7
ACGTACGTAA
6
AAGTTACCAA
12