
細說MySQL資料庫操作
目錄
基本語法:
CREATE DATABASE [IF NOT EXISTS] db_name [DEFAULT] CHARACTER SET charset_name [DEFAULT] COLLATE collation_name;最簡便的設定(字符集和校驗規則都採用預設設定):

建立一個名為itbsl的資料庫,並設定字符集和校驗規則

說明:
- MySQL語句以分號結尾;
- MySQL語句關鍵字不區分大小寫。例如,不管寫成CREATE還是create,效果是一樣的,不過為了便於區分還是建議MySQL關鍵字大寫,欄位名和表名小寫。
- CHARACTER SET 字符集,表示資料庫的文字編碼方式,上圖中設定的是utf8,如果沒有設定則採用預設值,這個預設值可以通過my.ini配置檔案來修改,(MySQL8預設字符集是utf8mb4)
- COLLATE 校驗規則,校驗規則影響如下: 1.查詢結果的影響:如果是utf8_general_ci表示不區分大小寫,如果是utf8_bin則表示區分大小寫 2.對order by子查詢的結果有影響
- 如果在資料庫下建立表,那麼在預設情況下,表將會使用對應的資料庫的字符集和校驗規則,如果在建立表的時候指定了新的字符集和校驗規則,則以當前表的設定為準。
- 在建立資料庫指定字符集時,可以用character set utf8,也可以用charset=utf8,兩種均可。
字符集和校驗規則
字符集是一套符號和編碼。校驗規則是在字符集內用於比較字元的一套規則。
字符集
- MySQL5.5.3之後增加了utf8mb4字元編碼,最多使用四個位元組儲存字元
- utf8mb4是utf8的超集並完全相容utf8,能夠用四個位元組儲存更多的字元。
有了utf8,為什麼要用utf8mb4?
標準的UTF-8字符集編碼是可以使用1-4個位元組去編碼21位字元,這幾乎包含了世界上所有能看見的語言。
而mysql支援的 utf8 編碼最大字元長度為 3 位元組,如果遇到 4 位元組的寬字元就會插入異常了。三個位元組的 UTF-8 最大能編碼的 Unicode 字元是 0xffff,也就是 Unicode 中的基本多文種平面(BMP)。也就是說,任何不在基本多文字平面的 Unicode字元,都無法使用 Mysql 的 utf8 字符集儲存。包括 Emoji 表情(Emoji 是一種特殊的 Unicode 編碼,常見於 ios 和 android 手機上),和很多不常用的漢字,以及任何新增的 Unicode 字元等等。
MySQL在5.5.3版本之後增加了這個utf8mb4的編碼,mb4就是most bytes 4的意思,專門用來相容四位元組的unicode。好在utf8mb4是utf8的超集,除了將編碼改為utf8mb4外不需要做其他轉換。
當然了,如果我們能夠確定資料庫中不會儲存四位元組字元,完全可以使用utf8編碼,因為這樣更加節省空間。
我們可以通過select version()檢視資料庫的版本,以確定是否支援utf8mb4。
select version();
校驗規則
是在字符集內用於比較字元的一套規則,比如定義'A'<'B'這樣的關係的規則。不同collation可以實現不同的比較規則,如'A'='a'在有的規則中成立,而有的不成立;進而說,就是有的規則區分大小寫,而有的無視。
utf8mb4對應的校驗規則有utf8mb4_unicode_ci、utf8mb4_general_ci
utf8mb4_unicode_ci和utf8mb4_general_ci的對比:
- 準確性
- utf8mb4_unicode_ci是基於標準的Unicode來排序和比較,能夠在各種語言之間精確排序
- utf8mb4_general_ci沒有實現Unicode排序規則,在遇到某些特殊語言或者字符集,排序結果可能不一致。
- 但是,在絕大多數情況下,這些特殊字元的順序並不需要那麼精確。
- 效能
- utf8mb4_general_ci在比較和排序的時候更快
- utf8mb4_unicode_ci在特殊情況下,Unicode排序規則為了能夠處理特殊字元的情況,實現了略微複雜的排序演算法。
- 但是在絕大多數情況下發,不會發生此類複雜比較。相比選擇哪一種collation,使用者更應該關心字符集與排序規則在db裡需要統一。
校驗規則的影響
實際操作來看看校驗規則的影響
(1) 校驗規則對查詢的影響:
在資料庫itbsl下建立一個校驗規則為utf8_general_ci的test表;
use itbsl;
create table `test`(
`id` int auto_increment primary key comment "主鍵",
`name` char(20) not null default '' comment '姓名'
)charset=utf8 collate utf8_general_ci;
insert into `test` value(default, 'a');
insert into `test` value(default, 'A');
insert into `test` value(default, 'b');
insert into `test` value(default, 'B');在校驗規則為utf8_general_ci的情況下,查詢name等於a的結果有兩條,因為不區分大小寫,如圖所示:

在資料庫itbsl下建立一個校驗規則為utf8_bin的test2表;
use itbsl;
create table `test2`(
`id` int auto_increment primary key comment "主鍵",
`name` char(20) not null default '' comment '姓名'
)charset=utf8 collate utf8_bin;
insert into `test2` value(default, 'a');
insert into `test2` value(default, 'A');
insert into `test2` value(default, 'b');
insert into `test2` value(default, 'B');在校驗規則為utf8_bin的情況下,查詢name等於a的結果只有一條,因為區分大小寫了,如圖所示:

(2) 校驗規則對排序的影響
utf8_general_ci:
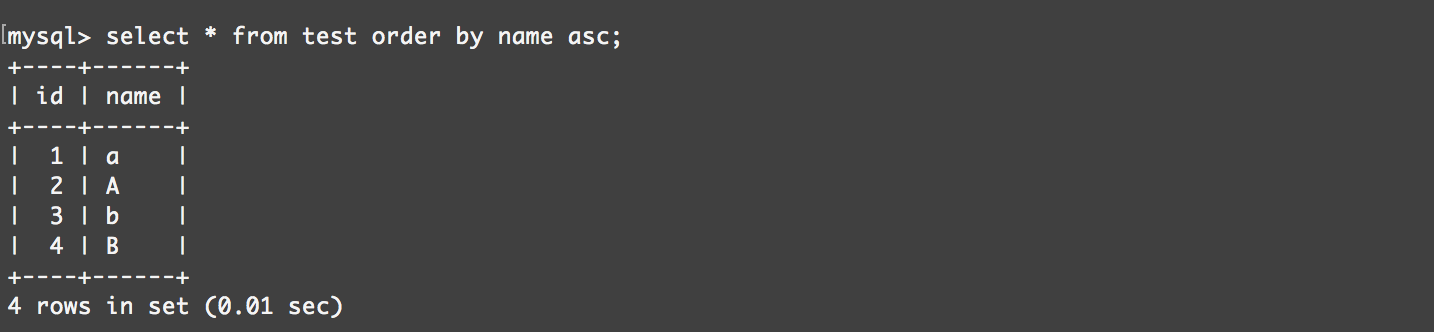
utf8_bin: 排序時按照字母對應的ascii碼值排序

資料庫操作相關指令
查詢資料庫版本:
SELECT VERSION();
顯示資料庫語句:
SHOW DATABASES;
顯示資料庫建立語句:
SHOW CREATE DATABASE db_name;
itbsl被反引號``包裹,如果使用``包裹資料庫名或表名,這樣資料庫名或者表名使用了關鍵字,也不會報錯,會正常執行,所以建議在建立資料庫或者表時都加上反引號,但是同時建議資料庫名和表明不要和關鍵字一樣。
/!40100 DEFAULT CHARACTER SET utf8 /
上面這句話不是註釋,而是表示:當MySQL資料庫版本大於4.01時,就執行DEFAULT CHARACTER SET utf8mb4,反之就不執行這句話。
資料庫刪除語句:
DROP DATABASE [IF EXISTS] db_name;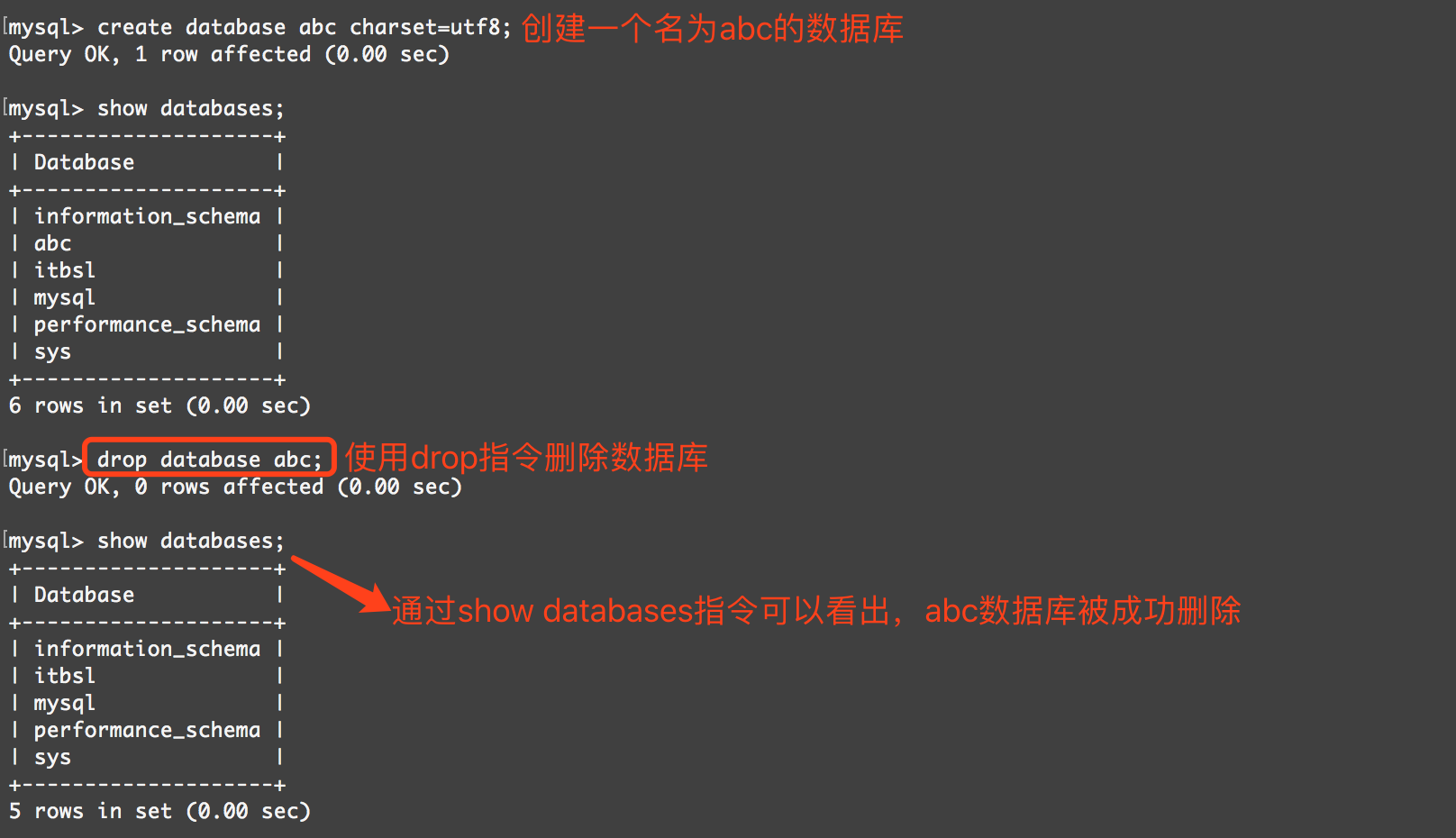
檢視當前資料庫有多少個使用者在操作:
SHOW PROCESSLIST;
通過這個命令可以檢視當前有哪些使用者在連線MySQL,如果看到非法(異常)使用者,可以及時發現並對其進行處理。