
機器學習中的幾種距離度量方法比較
1. 歐氏距離(Euclidean Distance) /ju:'klidiən/
歐式距離是最容易直觀理解的距離度量方法,我們小學,中學,高中所接觸的兩個空間中的距離一般都是指的是歐式距離。
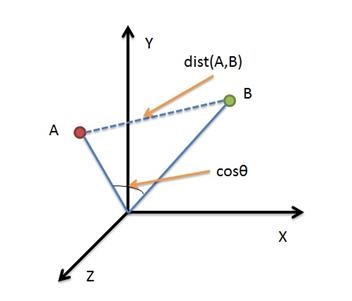
二維平面上點a(x1,y1)與b(x2,y2)間的歐氏距離:
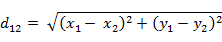
三維空間點a(x1,y1,z1)與b(x2,y2,z2)間的歐氏距離:
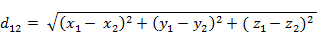
n維空間點a(x11,x12,…,x1n)與b(x21,x22,…,x2n)間的歐氏距離(兩個n維向量):
Matlab計算歐氏距離:
Matlab計算距離使用pdist函式。若X是一個m×n的矩陣,則pdist(X)將X矩陣每一行作為一個n維行向量
X=[1,1;2,2;3,3;4,4];
d=pdist(X,'euclidean')
d =
1.4142 2.8284 4.2426 1.4142 2.8284 1.41422. 曼哈頓距離(Manhattan Distance) /mæn'hæt(ə)n/
顧名思義,在曼哈頓街區要從一個十字路口開車到另一個十字路口,駕駛距離顯然不是兩點間的直線距離。這個實際駕駛距離就是“曼哈頓距離”。曼哈頓距離也稱為“城市街區距離”(City Block distance)。
兩個點在標準座標系上的絕對軸距總和
二維平面兩點a(x1,y1)與b(x2,y2)間的曼哈頓距離:
![]()
n維空間點a(x11,x12,…,x1n)與b(x21,x22,…,x2n)的曼哈頓距離:
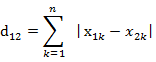
Matlab計算曼哈頓距離:
X=[1,1;2,2;3,3;4,4];
d=pdist(X,'cityblock')
d =
2 4 6 2 4 2
3. 切比雪夫距離 (Chebyshev Distance)
國際象棋中,國王可以直行、橫行、斜行,所以國王走一步可以移動到相鄰8個方格中的任意一個。國王從格子(x1,y1)走到格子(x2,y2)最少需要多少步?(自己走走試試。你會發現最少步數總是max(| x2-x1 | , | y2-y1 | ) 步。)
各座標數值差的最大值,

二維平面兩點a(x1,y1)與b(x2,y2)間的切比雪夫距離:
![]()
n維空間點a(x11,x12,…,x1n)與b(x21,x22,…,x2n)的切比雪夫距離
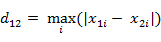
Matlab計算切比雪夫距離:
X=[1 1;2 2;3 3;4 4];
d=pdist(X,'chebychev')
d =
1 2 3 1 2 14. 閔可夫斯基距離(Minkowski Distance
閔氏距離不是一種距離,而是一組距離的定義,是對多個距離度量公式的概括性的表述。
閔氏距離定義:
兩個n維變數a(x11,x12,…,x1n)與b(x21,x22,…,x2n)間的閔可夫斯基距離定義為:
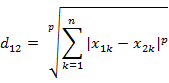
其中p是一個變引數:
當p=1時,就是曼哈頓距離;
當p=2時,就是歐氏距離;
當p→∞時,就是切比雪夫距離。
因此,根據變引數的不同,閔氏距離可以表示某一類/種的距離。
閔氏距離,包括曼哈頓距離、歐氏距離和切比雪夫距離都存在明顯的缺點。
e.g. 二維樣本(身高[單位:cm],體重[單位:kg]),現有三個樣本:a(180,50),b(190,50),c(180,60)。那麼a與b的閔氏距離 (無論是曼哈頓距離、歐氏距離或切比雪夫距離)等於a與c的閔氏距離。但實際上身高的10cm並不能和體重的 10kg劃等號。
閔氏距離的缺點:
(1)將各個分量的量綱(scale),也就是“單位”相同的看待了;
(2)未考慮各個分量的分佈(期望,方差等)可能是不同的。
Matlab計算閔氏距離(以p=2的歐氏距離為例):
X=[1 1;2 2;3 3;4 4];
d=pdist(X,'minkowski',2)
d=
1.4142 2.8284 4.2426 1.4142 2.8284 1.41425. 標準化歐氏距離 (Standardized Euclidean Distance)
定義: 標準化歐氏距離是針對歐氏距離的缺點而作的一種改進。標準歐氏距離的思路:既然資料各維分量的分佈不一樣,那先將各個分量都“標準化”到均值、方差相等。
假設樣本集X的均值(mean)為m,標準差(standard deviation)為s,X的“標準化變數”表示為:
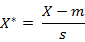
標準化歐氏距離公式:
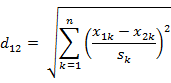
如果將方差的倒數看成一個權重,也可稱之為加權歐氏距離(Weighted Euclidean distance)。
Matlab計算標準化歐氏距離(假設兩個分量的標準差分別為0.5和1):
X=[1 1;2 2;3 3;4 4];
d=pdist(X,'seuclidean',[0.5,1])
d=
2.2361 4.4721 6.7082 2.2361 4.4721 2.23616. 馬氏距離(Mahalanobis Distance)
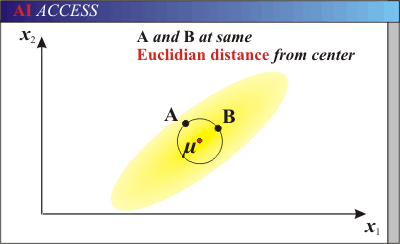
馬氏距離的引出:
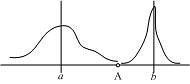
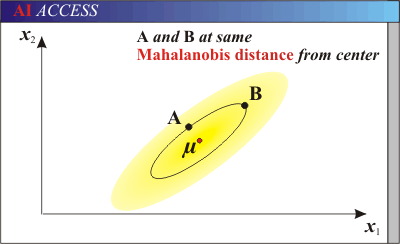
上圖有兩個正態分佈的總體,它們的均值分別為a和b,但方差不一樣,則圖中的A點離哪個總體更近?或者說A有更大的概率屬於誰?顯然,A離左邊的更近,A屬於左邊總體的概率更大,儘管A與a的歐式距離遠一些。這就是馬氏距離的直觀解釋。
概念:馬氏距離是基於樣本分佈的一種距離。物理意義就是在規範化的主成分空間中的歐氏距離。所謂規範化的主成分空間就是利用主成分分析對一些資料進行主成分分解。再對所有主成分分解軸做歸一化,形成新的座標軸。由這些座標軸張成的空間就是規範化的主成分空間。
定義:有M個樣本向量X1~Xm,協方差矩陣記為S,均值記為向量μ,則其中樣本向量X到μ的馬氏距離表示為:
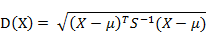
向量Xi與Xj之間的馬氏距離定義為:
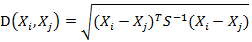
若協方差矩陣是單位矩陣(各個樣本向量之間獨立同分布),則Xi與Xj之間的馬氏距離等於他們的歐氏距離:
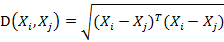
若協方差矩陣是對角矩陣,則就是標準化歐氏距離。
歐式距離&馬氏距離:
馬氏距離的特點:
量綱無關,排除變數之間的相關性的干擾;
馬氏距離的計算是建立在總體樣本的基礎上的,如果拿同樣的兩個樣本,放入兩個不同的總體中,最後計算得出的兩個樣 本間的馬氏距離通常是不相同的,除非這兩個總體的協方差矩陣碰巧相同;
計算馬氏距離過程中,要求總體樣本數大於樣本的維數,否則得到的總體樣本協方差矩陣逆矩陣不存在,這種情況下,用歐 式距離計算即可。
Matlab計算馬氏距離:
X=[1 2;1 3;2 2;3 1];
d=pdist(X,'mahal')
d=
2.3452 2.0000 2.3452 1.2247 2.4495 1.22477. 餘弦距離(Cosine Distance)
幾何中,夾角餘弦可用來衡量兩個向量方向的差異;機器學習中,借用這一概念來衡量樣本向量之間的差異。
二維空間中向量A(x1,y1)與向量B(x2,y2)的夾角餘弦公式:
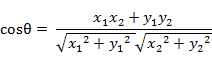
兩個n維樣本點a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夾角餘弦為:
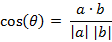
即:
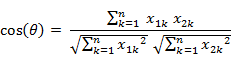
夾角餘弦取值範圍為[-1,1]。餘弦越大表示兩個向量的夾角越小,餘弦越小表示兩向量的夾角越大。當兩個向量的方向重合時餘弦取最大值1,當兩個向量的方向完全相反餘弦取最小值-1。
Matlab計算夾角餘弦(Matlab中的pdist(X, ‘cosine’)得到的是1減夾角餘弦的值):
X=[1 1;1 2;2 5;1 -4];
d=1-pdist(X,'cosine')
d=
0.9487 0.9191 -0.5145 0.9965 -0.7593 -0.81078. 漢明距離(Hamming Distance)
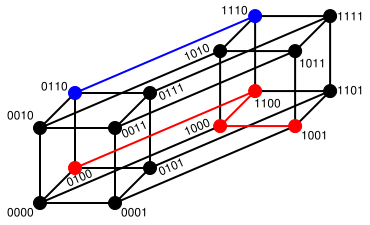
定義:兩個等長字串s1與s2的漢明距離為:將其中一個變為另外一個所需要作的最小字元替換次數。例如:
The Hamming distance between "1011101" and "1001001" is 2.
The Hamming distance between "2143896" and "2233796" is 3.
The Hamming distance between "toned" and "roses" is 3.漢明重量:是字串相對於同樣長度的零字串的漢明距離,也就是說,它是字串中非零的元素個數:對於二進位制字串來說,就是 1 的個數,所以 11101 的漢明重量是 4。因此,如果向量空間中的元素a和b之間的漢明距離等於它們漢明重量的差a-b。
應用:漢明重量分析在包括資訊理論、編碼理論、密碼學等領域都有應用。比如在資訊編碼過程中,為了增強容錯性,應使得編碼間的最小漢明距離儘可能大。但是,如果要比較兩個不同長度的字串,不僅要進行替換,而且要進行插入與刪除的運算,在這種場合下,通常使用更加複雜的編輯距離等演算法。
Matlab計算漢明距離(Matlab中2個向量之間的漢明距離的定義為2個向量不同的分量所佔的百分比):
X=[0 1 1;1 1 2;1 5 2];
d=pdist(X,'hamming')
d=
0.6667 1.0000 0.3333
9. 傑卡德距離(Jaccard Distance)
傑卡德相似係數(Jaccard similarity coefficient):兩個集合A和B的交集元素在A,B的並集中所佔的比例,稱為兩個集合的傑卡德相似係數,用符號J(A,B)表示:
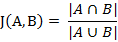
傑卡德距離(Jaccard Distance):與傑卡德相似係數相反,用兩個集合中不同元素佔所有元素的比例來衡量兩個集合的區分度:
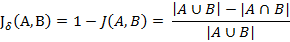
Matlab計算傑卡德距離(Matlab中將傑卡德距離定義為不同的維度的個數佔“非全零維度”的比例):
X=[1 1 0;1 -1 0;-1 1 0];
d=pdist(X,'jaccard')
d=
0.5000 0.5000 1.000010. 相關距離(Correlation distance)
相關係數:是衡量隨機變數X與Y相關程度的一種方法,相關係數的取值範圍是[-1,1]。相關係數的絕對值越大,則表明X與Y相關度越高。當X與Y線性相關時,相關係數取值為1(正線性相關)或-1(負線性相關):
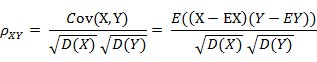
相關距離:
![]()
Matlab計算相關係數與相關距離:
X=[1 2 3 4;3 8 7 6];
c=corrcoef(X') %返回相關係數矩陣
d=pdist(X,'correlation') %返回相關距離
c=
1.0000 0.4781
0.4781 1.0000
d=
0.521911. 資訊熵(Information Entropy)
以上的距離度量方法度量的皆為兩個樣本(向量)之間的距離,而資訊熵描述的是整個系統內部樣本之間的一個距離,或者稱之為系統內樣本分佈的集中程度(一致程度)、分散程度、混亂程度(不一致程度)。系統內樣本分佈越分散(或者說分佈越平均),資訊熵就越大。分佈越有序(或者說分佈越集中),資訊熵就越小。
計算給定的樣本集X的資訊熵的公式:
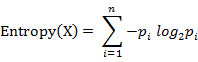
引數的含義:
n:樣本集X的分類數
pi:X中第 i 類元素出現的概率
資訊熵越大表明樣本集S的分佈越分散(分佈均衡),資訊熵越小則表明樣本集X的分佈越集中(分佈不均衡)。當S中n個分類出現的概率一樣大時(都是1/n),資訊熵取最大值log2(n)。當X只有一個分類時,資訊熵取最小值0。