
Question Retrieval with Distributed Representations and Participant Reputation in Community QA論文筆記
摘要
- 社群問題的難點在於:重複性問題
- 解決上述問題要採用Query retrieval(QR),QR的難點在於:同義詞匯
- 本文演算法:1)採用continuous bag-of-words(CBoW)模型對詞(word)進行 Distributed Representations(分散式表達,詞嵌入);2)對given query和存檔的query計算tile域和description域的相似度;3)將使用者信譽(user reputation)也用於排序模型
- 測試資料集為 Asus's Republic of Gamers (ROG) 論壇
引言
QR的難點在於同於詞彙,處理同義詞的方法有四種:
- Language model information retrieval (LMIR):思想為計算給定問題和候選問題間詞序列的概率
- language model with category smoothing (LMC):將問題類別表示為向量空間的一個維度(上述兩種方法的缺點為:忽略了詞與詞之間的相似度)
- translation-based language modeling (TBLM):使用QA對來學習語義相關的單詞以改進傳統的IR模型,缺點是學習一個翻譯表太耗時
- distributed-representation-based language modeling (DRLM) :使用資料的分散式表示來替換TBLM中的詞到詞間的翻譯概率,其使用word2vector計算概率
本文演算法
本文演算法包含三部分:1)詞嵌入學習:給定論壇資料集,問題被視為基本單位, 問題中的每個單詞都會轉換為一個單詞向量。
2)得分生成:學習到單詞向量後,就可以通過計算查詢問題和候選問題之間的相似性來進行問題檢索。
3)使用信譽資訊:通過引入每個存檔問題參與者的信譽值來加強排序函式。
1.Word2vec
word2vec的理解可以參看部落格
2.問題標題和描述的排序函式
利用word2vec學習到詞向量後,每個問題q的向量表示式如下:

其中w為q中的每個詞,e是向量中每個維度的值。查詢問題q和候選答案Q間的相似度得分為:
論壇問題包含兩部分:title和description,不同於之前的研究,本文分別計算這兩部分的相似度得分:
α和β都是超引數,α+β=1
3.使用論壇中的使用者信譽
查詢問題q和候選問題Q間的相似度得分表達為:
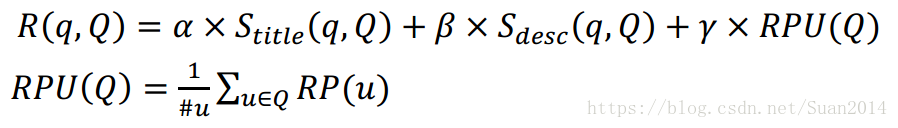
為超引數,
,RPU(Q)是參與Q討論的使用者信譽值總和,為避免來自同一論壇使用者的過多信譽值,只新增一次每個參與者的信譽值,為確保新帖的公平性,求信譽值的均值。
實驗
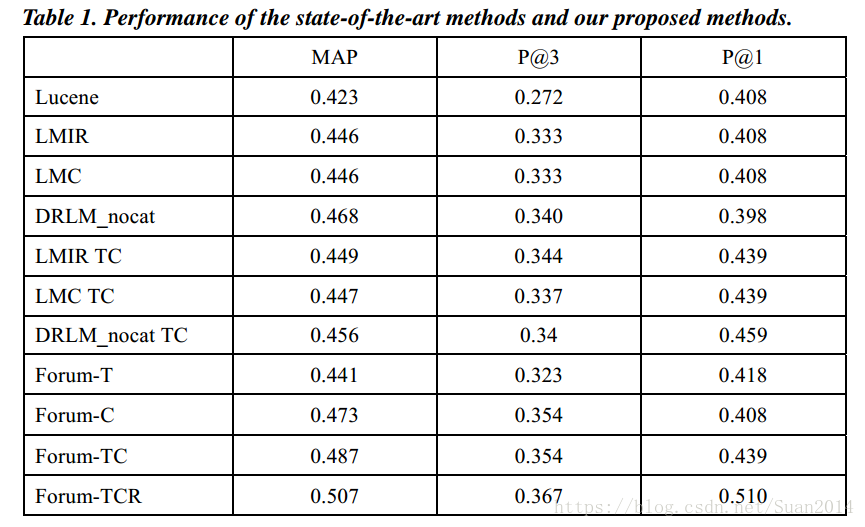
Forum為本文演算法,-T考慮問題title的相似度,-C考慮問題description的相似度,-R考慮使用者信譽值的相似度,上表可以看出本文演算法優於其他演算法。
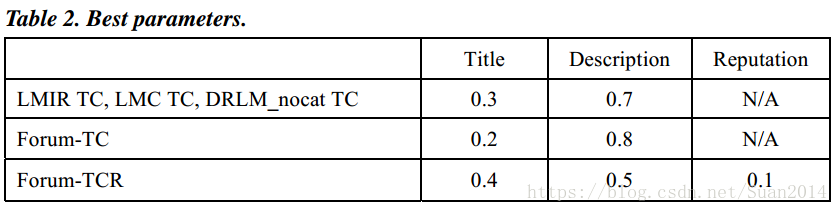
下表為超引數的最優值:
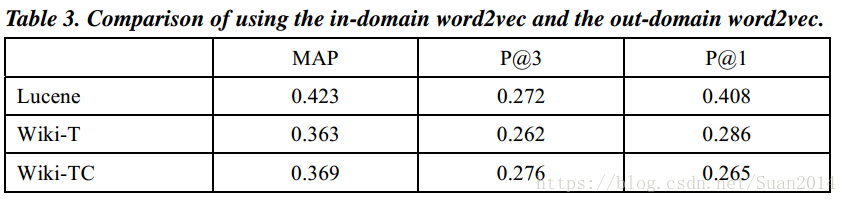
Wiki表示採用Wiki訓練資料,Table3表明Wiki表現最差,這表明對於word2vec的訓練,域內資料比域外培訓資料更有效。