
linux文字處理常用命令
linux文字處理命令:grep、sed、printf、awk
1.grep
grep的作用是按行查詢字元,輸出包含字元的行。
#從檔案查詢
grep 'hello' filename.txt#從管道的輸入查詢
cat filename.txt|grep 'hello'grep使用示例:
grep的查詢主要就是基於基本正則表示式的匹配,下面只是簡單的給一些常用例子供參考。
grep 't[ae]st' //查詢tast或test
grep '[0-9]' //查詢數字
grep '[^a-z]oo' //查詢Xoo,其中X是一個非a到z的字元
grep '^the' //查詢以the開頭的字元,這裡注意區分^出現在[]裡時代表“非某字元”,如上個例子,出現在[]外時代表"以某字元開頭",如這個例子。
grep '^$' //查詢空行
grep 'o\{2\}' //查詢兩個o,這裡需要注意,{}在shell裡有特殊意義,因此需要轉義,這裡與一般的正則使用不同,需要注意。
egrep:
我們知道正則表示式分為基本正則表示式和擴充套件正則表示式,但是grep只支援基本正則表示式,如果要是用擴充套件正則表示式,需要使用egrep命令。
幾個例子:
egrep 'gd|good' //查詢gd或good
egrep 'g(la|oo)d' //查詢glad或good
egrep 'A(xyz)+C' //查詢AXC,其中X是一個或一個以上的'xyz'字串。
2.sed
sed是一個很強大的命令,可以用來做行刪除
sed是一個管道命令,可以處理管道輸入。
2.1行刪除
nl /etc/passwd | sed '2d' //刪除第2行
下面將省略輸入管道
sed '2,5d' //刪除第2~5行
sed '3,$d' //刪除第3到最後一行,$代表最後一行
sed '/^$/d' //刪除空行
2.2行新增
sed '2a drink tea' //在第二行下面追加一行"drink tea",a代表append
sed '2i drink tea' //在第二行上面插入一行"drink tea",i代表insert
sed '2a a\
b\
c' //在第二行下面追加三行 "a"、"b"、"c",只需要每行結尾加"\"即可。
2.3行選取
sed -n '5,7p' //選取第5到7行輸出,必須加-n引數,不然效果就是所有行都被輸出,而5到7行輸出兩次。
2.4行替換
sed '2,5c No 2~5 lines' //將第2到5行替換為一行字串"No 2~5 lines"
2.5字串替換
sed 's/要被替換的字串/新的字串/g' //固定的格式,開頭是s結尾是g,中間三個/分隔開要被替換的字串和新的字串,注意這裡要被替換的字串可以是正則表示式。
sed -i 's/hello/halo/g' filename.txt
將操作結果直接寫入檔案
預設用sed對檔案做修改之後,只是輸出修改後的檔案,可以用>寫入到新的檔案。但是如果想修改原始檔案,千萬不能>到原始檔案,這樣執行的結果就是原檔案直接被清空了。想要修改原始檔案可以用 -i 引數,如:
sed -i '2d' file.txt //直接將原檔案中的第二行刪除。
直接修改原檔案是很危險的,一旦修改錯誤無法還原。可以先不加 -i 引數執行命令把修改結果打印出來,確認無誤後再加上 -i 引數。
3.printf
printf這個命令用語言不太好描述,但是一動手就明白了。
把下面的內容儲存為printf.txt:
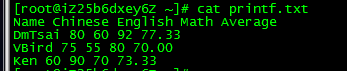
Name Chinese English Math Average
DmTsai 80 60 92 77.33
VBird 75 55 80 70.00
Ken 60 90 70 73.33先cat看一下,是下面這個效果:
現在用printf指令加一些引數來看一下,執行
printf '%10s %10s %10s %10s %10s \n' `cat printf.txt`輸出結果:

是不是比cat輸出的結果漂亮多了。
%10s代表這一列的寬度固定為10個字元。更多的格式就不介紹了,這篇文章我們掌握一個%10s就夠了。
printf不是管道命令,要想用它處理檔案必須像上面的命令那樣使用`cat printf.txt`把檔案內容給提出來。
printf的使用相當廣泛,後面的awk命令中也會應用到printf命令。
4.awk
awk命令主要是將檔案通過分隔符拆成列來處理,還能通過條件判斷對不同的行進行不同的處理,甚至還可以進行數值計算~
我們也是通過例子來學習。
我們先用last命令看一下最後登入的5個使用者資訊:

圖中的第一列是使用者名稱,第三列是使用者ip,現在我們想摘出這兩列,用awk就可以做到:
last -5|awk '{print $1 "\t" $3}'輸出:

命令看起來挺複雜,不要著急,其實很簡單。
首先awk使用時有固定的格式:awk '{命令}',單引號和大括號就是固定的格式而已。
然後上面的命令就是
print $1 "\t" $3 //awk預設會用空格和tab將每行分隔為N列,$1代表第一列,$3代表第三列。這樣一看是不是簡單多了。
剛剛的last命令產生的資料預設就是用tab分隔的,現在我們看另一個例子,執行 cat /etc/passwd:
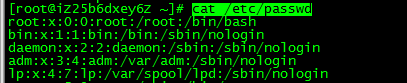
這次產生的資料每行是用 : 分隔的,那麼想使用awk輸出第一列和第三列就需要執行分隔符:
cat /etc/passwd|awk -F ':' '{print $1 "\t" $3}' // -F ':' 代表指定使用 : 作為分隔符執行結果:

除了$1,$3這樣的特殊符號,
awk的命令中還可以使用下面的特殊符號:
NF :每一行分隔後的列數
NR :行號
下面用一個綜合的例子來說明awk的條件判斷和數值計算,有這樣一組資料儲存為pay.txt:
Name 1st 2nd 3rd
VBird 23000 24000 25000
DMTsai 21000 20000 23000
Bird2 43000 42000 41000現在想加一列"Total",計算每一行的數值總和。
用awk可以完成這個需求:
cat pay.txt |awk 'NR==1 {printf "%10s %10s %10s %10s %10s \n",$1,$2,$3,$4,"Total"};NR>1 {printf "%10s %10s %10s %10s %10s \n",$1,$2,$3,$4,$2+$3+$4}'執行結果:

這裡有幾個要點:
- 加入條件判斷後,awk的格式為: awk '條件1 {命令1};條件2{命令2}'
- 條件判斷有以下邏輯運算:
- >
- <
- >=
- <=
- == //注意判斷相等要用兩個等號
- !=
- 可以直接運算行內列的值($1、$2、$3)。