
Ffume不同模式下的程式碼示例
阿新 • • 發佈:2018-12-21
Flume
一切盡在官網
flume的配置
flume程式碼示例

flume主要組成是agent,agent的組成分為Source(資料進入埠),Channel(資料管道),Sink(資料輸出端)
# example.conf: A single-node Flume configuration #對agent的元件其名稱 # Name the components on this agent //定義agent的名稱,對agent中的三個元件進行命名 //sources,sinks,channels 後加S所以可以同時定義多個,來適應不同的業務場景 a1.sources = r1 a1.sinks = k1 a1.channels = c1 //設定source端 source的資料來源是什麼? 根據不同的資料來源,設定source的內容 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 //設定sinks端 sink端輸出的資料型別,根據不同的業務場景,來設定 # Describe the sink a1.sinks.k1.type = logger //設定channels channels存在的型別,大小為1000,每次傳輸的大小為100 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 //規定source、channel對應關係和channnel、sink對應的關係 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
模型簡介
不同的模型對應不同的業務邏輯
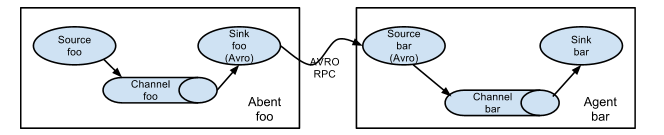
flume與flume之間連線使用的資料型別是AVRO 為了將資料通過多個代理或跳資料流,前一代理和當前跳轉源的接收器需要是 avro 型別,該接收器指向主機名(或 IP 地址)和源的埠。 多個flume連線
程式碼示例:在兩臺機器上
//從第一臺webService上獲取資料,傳輸送到第二臺機器上,寫入到第二臺機器的磁碟上 //第一臺上的配置檔案 //對agent元件進行命名 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source //source端的配置 a1.sources.r1.type = exec a1.sources.r1.command = tail -f /home/bigdata/webapp.log # Describe the sink //sink短的配置 a1.sinks.k1.type = avro a1.sinks.k1.hostname = bigdata a1.sinks.k1.port = 8888 # Use a channel which buffers events in memory a1.channels.c1.type = memory # Bind the source and sink to the channel //channel的配置 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 //第二臺的配置檔案 # Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = avro a2.sources.r1.bind = bigdata a2.sources.r1.port = 8888 # Describe the sink a2.sinks.k1.type = hdfs a2.sinks.k1.hdfs.path = hdfs://bigdata:9000/logDir # Use a channel which buffers events in memory a2.channels.c1.type = memory # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1
多個flume匯聚到一個flume在輸出
A very common scenario in log collection is a large number of log producing clients sending data to a few consumer agents that are attached to the storage subsystem. For example, logs collected from hundreds of web servers sent to a dozen of agents that write to HDFS cluster. 日誌集合中一個非常常見的場景是大量的日誌生成客戶端將資料傳送給附屬於儲存子系統的一些消費者代理。 例如,從數百個網路伺服器收集的日誌傳送給十幾個寫給 HDFS 叢集的代理 This can be achieved in Flume by configuring a number of first tier agents with an avro sink, all pointing to an avro source of single agent (Again you could use the thrift sources/sinks/clients in such a scenario). This source on the second tier agent consolidates the received events into a single channel which is consumed by a sink to its final destination 通過使用 avro 接收器配置一些一級代理可以在 Flume 中實現,這些代理都指向單個代理的 avro 源(在這種情況下,你可以使用節約源 / 匯 / 客戶端)。 第二層代理的這個源將接收到的事件合併到一個通道中,這個通道被一個接收器消耗到它的最終目的地
Flume supports multiplexing the event flow to one or more destinations. This is achieved by defining a flow multiplexer that can replicate or selectively route an event to one or more channels. A fan-out flow using a (multiplexing) channel selector The above example shows a source from agent “foo” fanning out the flow to three different channels. This fan out can be replicating or multiplexing. In case of replicating flow, each event is sent to all three channels. For the multiplexing case, an event is delivered to a subset of available channels when an event’s attribute matches a preconfigured value. For example, if an event attribute called “txnType” is set to “customer”, then it should go to channel1 and channel3, if it’s “vendor” then it should go to channel2, otherwise channel3. The mapping can be set in the agent’s configuration file. 支援將事件流向一個或多個目的地。 這是通過定義一個可以複製或選擇性地將事件路由到一個或多個通道的流多路器來實現的。 一種使用(多路複用)通道選擇器的扇形流 上面的例子顯示了來自"foo"的原始碼,將流程分散到三個不同的通道。 這個風扇可以複製或複用。 在複製流程的情況下,每個事件被髮送到所有三個通道。 對於多路複用情況,當事件的屬性與預配置值匹配時,將事件傳遞給可用的子集通道。 例如,如果一個被稱為"txnType"的事件屬性設定為"customer",那麼它應該被引導到通道1和通道3,如果它是"供應商",那麼它應該被引導到通道2,否則是通道3。 對映可以設定在代理的配置檔案。
flume中有多個sink輸出到不同的位置
第一臺機器收集flume日誌資訊
第二臺機器實時顯示第一臺的日誌資訊
第三臺機器將日誌資訊儲存到hdfs上
Flume通過檔案來讀取資料 # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source #source端的根據資料型別來確定type a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/app/hive-0.13.1-cdh5.3.6/logs/hive.log a1.sources.r1.shell = /bin/bash -c # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname =hh4 a1.sinks.k1.port = 4141 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 # Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = netcat a2.sources.r1.bind = hh4 a2.sources.r1.port = 44444 # Describe the sink a2.sinks.k1.type = avro a2.sinks.k1.hostname = hh4 a2.sinks.k1.port = 4141 # Use a channel which buffers events in memory a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1 # Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c1 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hh4 a3.sources.r1.port = 4141 # Describe the sink a3.sinks.k1.type = hdfs a3.sinks.k1.hdfs.path = hdfs://hh4:8020/flume3/%Y%m%d/%H #上傳檔案的字首 a3.sinks.k1.hdfs.filePrefix = flume3- #是否按照時間滾動資料夾 a3.sinks.k1.hdfs.round = true #多少時間單位建立一個新的資料夾 a3.sinks.k1.hdfs.roundValue = 1 #重新定義時間單位 a3.sinks.k1.hdfs.roundUnit = hour #是否使用本地時間戳 a3.sinks.k1.hdfs.useLocalTimeStamp = true #積攢多少個 Event 才 flush 到 HDFS 一次 a3.sinks.k1.hdfs.batchSize = 100 #設定檔案型別,可支援壓縮 a3.sinks.k1.hdfs.fileType = DataStream #多久生成一個新的檔案 a3.sinks.k1.hdfs.rollInterval = 600 #設定每個檔案的滾動大小大概是 128M a3.sinks.k1.hdfs.rollSize = 134217700 #檔案的滾動與 Event 數量無關 a3.sinks.k1.hdfs.rollCount = 0 #最小冗餘數 a3.sinks.k1.hdfs.minBlockReplicas = 1 # Describe the channel a3.channels.c1.type = memory a3.channels.c1.capacity = 1000 a3.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1