
pyspark 自定義聚合函式 UDAF
阿新 • • 發佈:2018-12-21
自定義聚合函式 UDAF 目前有點麻煩,PandasUDFType.GROUPED_AGG 在2.3.2的版本中不知怎麼回事,不能使用!
這樣的話只能曲線救國了!
PySpark有一組很好的聚合函式(例如,count,countDistinct,min,max,avg,sum),但這些並不適用於所有情況(特別是如果你試圖避免代價高昂的Shuffle操作)。
PySpark目前有pandas_udfs,它可以建立自定義聚合器,但是你一次只能“應用”一個pandas_udf。如果你想使用多個,你必須預先形成多個groupBys ......並且避免那些改組。
在這篇文章中,我描述了一個小黑客,它使您能夠建立簡單的python UDF,它們對聚合資料起作用(此功能只應存在於Scala中!)。
1
2
3
4
5
6 7 8 |
|
| ID | 值 |
|---|---|
| 1 | '一個' |
| 1 |
'B' |
| 1 | 'B' |
| 2 | 'C' |
我使用collect_list將給定組中的所有資料放入一行。我列印下面這個操作的輸出。
1
|
|
| ID | VALUE_LIST |
|---|---|
| 1 | ['a','b','b'] |
| 2 | ['C'] |
然後我建立一個UDF,它將計算這些列表中字母'a'的所有出現(這可以很容易地在沒有UDF的情況下完成,但是你明白了)。此UDF包含collect_list,因此它作用於collect_list的輸出。
1
2
3
4
5
6 7 8 9 10 11 |
|
| ID | A_COUNT |
|---|---|
| 1 | 1 |
| 2 | 0 |
我們去!作用於聚合資料的UDF!接下來,我展示了這種方法的強大功能,結合何時讓我們控制哪些資料進入F.collect_list。
首先,讓我們建立一個帶有額外列的資料框。
1
2
3
4
5
6 7 8 9 |
|
| ID | 值1 | 值2 |
|---|---|---|
| 1 | 1 | '一個' |
| 1 | 2 | '一個' |
| 1 | 1 | 'B' |
| 1 | 2 | 'B' |
| 2 | 1 | 'C' |
請注意,我如何在collect_list中包含一個when。請注意,UDF仍然包含collect_list。
1
|
|
| ID | A_COUNT |
|---|---|
| 1 | 1 |
| 2 | 0 |
https://danvatterott.com/blog/2018/09/06/python-aggregate-udfs-in-pyspark/
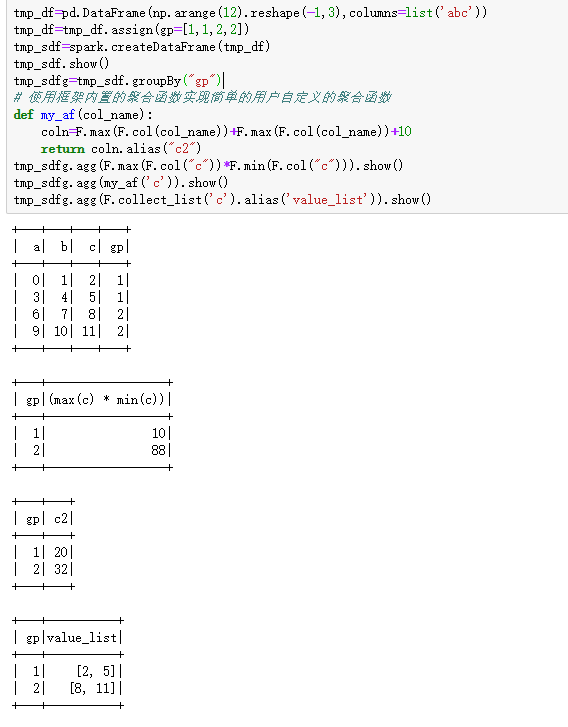
還有一種做法就是用pandas_udf, 然後按照聚合的得到的列去重