
大資料(十一)--Scala程式語言-提高
Scala字串
Scala中字串也是分為兩種: 可變長度的StringBuilder和不可變長度的String, 其操作用法與Java幾乎一致.
接下來, 通過程式碼來檢視常用方法
//定義字串
val str1 = "Hello Scala"
var str2 = "Hello Scala"
var str2_1 = "hello scala"
//字串比較
println(str1 == str2)
println(str1.equals(str2))
println(str1.equalsIgnoreCase(str2_1))
//上述三個比較全部返回true
//按字典順序比較兩個字串
println //從0開始返回指定位置的字元
println(str1.charAt(6))
//追加
println(str2.concat(" Language"))
//是否以指定的字尾結束
println(str1.endsWith("la"))
//使用預設字符集將String編碼為 byte 序列
println(str1.getBytes)
//雜湊碼
println(str1.hashCode)
//指定子字串在此字串中第一次出現處的索引
println //使用StringBuilder
val strBuilder = new StringBuilder
//拼接字串
strBuilder.append("Hello ")
strBuilder.append("Scala")
println(strBuilder)
//反轉
println(strBuilder.reverse)
//返回容量
println(strBuilder.capacity)
//指定位置插入
println(strBuilder.insert(6,"Spark "))
Scala 集合
1. 陣列
Java中使用 new String[10]的形式可以建立陣列, 但Scala中建立陣列需要用到Array關鍵詞, 用[ ]指定陣列中元素的泛型, 取值使用小括號(index).
//建立Int型別的陣列, 預設值為0
val nums = new Array[Int](10)
//建立String型別的陣列, 預設值為null
val strs = new Array[String](10)
//建立Boolean型別的陣列, 預設值為false
val bools = new Array[Boolean](10)
//通過索引遍歷陣列,給元素賦值
for (index <- 0 until nums.length) nums(index) = index + 1
//陣列遍歷,編碼的逐步簡化
nums.foreach ( (x: Int) => print(x + " ") )
println()
nums.foreach ( (x => print(x + " ")) )
println()
nums.foreach(print(_))
println()
nums.foreach(print)
foreach函式傳入一個函式引數, 由於Scala支援型別推測, 可以將引數函式的引數型別省略; 在引數函式中, 該函式的引數只出現一次, 因為可以使用下劃線_代替(如果有多個可以使用_.1/_.2); 最後由於Scala語言的靈活性, 只需傳入print這個函式也會遍歷列印整個集合.
建立二維陣列分兩步: 建立一個泛型為陣列的陣列, 然後對這個陣列遍歷,
val secArray = new Array[Array[String]](5)
for (index <- 0 until secArray.length){
secArray(index) = new Array[String](5)
}
//填充資料
for (i <- 0 until secArray.length;j <- 0 until secArray(i).length) {
secArray(i)(j) = i * j + ""
}
secArray.foreach(array => array.foreach(println))
2. list
Scala中列表的定義使用List關鍵詞. List集合是一個不可變的集合. 下面來看建立List已經list呼叫的方法.
//建立列表
val list = List(1,2,3,4,5)
//對列表遍歷
list.foreach(println)
//contains判斷是否包含某個元素
println(list.contains(6))
//反序,返回一個新的List
list.reverse.foreach(println)
//去前n個元素,返回一個新的List
list.take(3).foreach(println)
//刪除前n個元素,返回一個新的List
list.drop(2).foreach(println)
//判斷集合中是否有元素滿足判斷條件
println(list.exists(_ > 4))
//把List中的元素用設定的字元(串)進行拼接
list.mkString("==").foreach(print)
/*map是一個高階函式,需要一個函式引數
返回值是That,意思是誰呼叫的map返回的型別跟呼叫map方法的物件的型別一致
這裡map返回的仍然是list,因此在map中可對每一個元素進行相同操作
map返回的list的泛型由編碼傳入的函式返回型別決定,如下(_ * 100)返回的list的泛型就是Int
*/
list.map(println)
list.map(_ * 100).foreach(println)
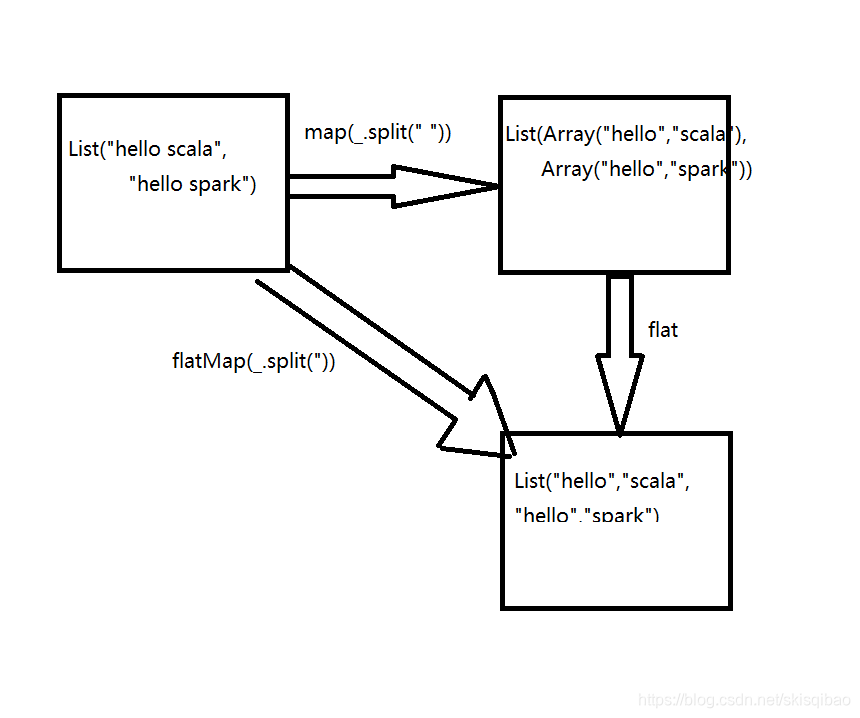
val logList = List("Hello Scala" , "Hello Spark")
/*由上述介紹可知,split()返回一個數組,因此map返回的型別是泛型為陣列型別的list
需要對返回的list進行兩次遍歷,第一次遍歷得到Array,第二次遍歷拿到String
*/
logList.map(_.split(" ")).foreach(_.foreach(println))
/*
如果想直接拿到String,需要:
扁平操作
用到的函式是flatMap,flatMap返回的型別也是呼叫該方法的型別,但它可以直接得到String型別的單詞
*/
logList.flatMap(_.split(" ")).foreach(println)
對map和flatMap的理解可參考下圖:
Nil建立一個空List
Nil.foreach(println)
//::操作可用來新增元素
val list1 = 1::2::Nil
list1.foreach(println)
需要注意的是, 上述建立的list均為不可變長度的list, 即list中的元素只有在建立時才能新增. 建立可變長度的list, 需要用到ListBuffer, 看程式碼:
//建立一個ListBuffer,需要導包scala.collection.mutable.ListBuffer
val listBuffer = new ListBuffer[String]
//使用+=新增元素
listBuffer.+=("hello")
listBuffer.+=("Scala")
listBuffer.foreach(println)
//使用-=去除元素
listBuffer.-=("hello")
3. set
Scala中使用Set關鍵詞定義無重複項的集合.
Set常用方法展示:
//建立Set集合,Scala中會自動去除重複的元素
val set1 = Set(1,1,1,2,2,3)
//遍歷Set即可使用foreach也可使用for迴圈
set1.foreach(x => print( x + "\t"))
val set2 = Set(1,2,3,5,7)
//求兩個集合的交集
set1.intersect(set2).foreach(println)
set1.&(set2).foreach(println)
//求差集
set2.diff(set1).foreach(println)
set2.&~(set1).foreach(println)
//求子集,如果set1中包含set2,則返回true.注意是set1包含set2返回true
println(set2.subsetOf(set1))
//求最大值
println(set1.max)
//求最小值
println(set1.min)
//轉成List型別
set1.toList.map(println)
//轉成字串型別
set1.mkString("-").foreach(print)
4. Map
Scala中使用Map關鍵字建立KV鍵值對格式的資料型別.
4.1 建立map集合
val map = Map(
"1" -> "Hello",
2 -> "Scala",
3 -> "Spark"
)
建立Map時, 使用->來分隔key和value, KV型別可不相同, 中間使用逗號進行分隔.
4.2 map遍歷
遍歷map有三種方式, 即可使用foreach, 也可使用與Java中相同用法的迭代器, 還可使用for迴圈.
- 方式一: foreach
map.foreach(println)
此時, 列印的是一個個二元組型別的資料, 關於元組我們後文中會詳細介紹, 此處只展示一下二元組的樣子: (1,Hello); (2,Scala); (3,Spark).
- 方式二: 迭代器
val keyIterator = map.keys.iterator
while (keyIterator.hasNext){
val key = keyIterator.next()
println(key + "--" + map.get(key).get)
}
此時需注意:
map.get(key)返回值, 返回提示:
an option value containing the value associated with key in this map, or None if none exists.
即返回的是一個Option型別的物件, 如果能夠獲取到值, 則返回的是一個Some(Option的子類)型別的資料, 例如列印會輸出Some(Hello), 再通過get方法就可以獲取到其值;
如果沒有值會返回一個None(Option的子類)型別的資料, 該型別不能使用get方法獲取值(本來就無值, 強行取值當然要出異常)
看get方法的提示(如下), 元素必須存在, 否則丟擲NoSuchElementException的異常.
Returns the option's value. Note: The option must be nonEmpty.
Throws:
Predef.NoSuchElementException - if the option is empty.
既然這樣, 對於None型別的資料就不能使用get了, 而是使用getOrElse(“default”)方法, 該方法會先去map集合中查詢資料, 如果找不到會返回引數中設定的預設值. 例如,
//在上述map定義的情況下執行下述程式碼,會在終端列印default
println(map.get(4).getOrElse("default"))
- 方式三: for迴圈
for(k <- map) println(k._1 + "--" + k._2)
此處, 將map中的每一對KV以二元組(1, Hello)的形式賦給k這一迴圈變數. 可通過k._1來獲取第一個位置的值, k._2獲取第二個位置的值.
4.3 Map合併
//合併map
val map1 = Map(
(1,"a"),
(2,"b"),
(3,"c")
)
val map2 = Map(
(1,"aa"),
(2,"bb"),
(2,90),
(4,22),
(4,"dd")
)
map1.++:(map2).foreach(println)
++和++:的區別
| 函式 | 呼叫 | 含義 |
|---|---|---|
| ++ | map1.++(map2) | map1中加入map2 |
| ++: | map1.++:(map2) | map2中加入map1 |
注意:map在合併時會將相同key的value替換
4.4 Map其他常見方法
//filter過濾,慮去不符合條件的記錄
map.filter(x => {
Integer.parseInt(x._1 + "") >= 2
}).foreach(println)
//count對符合條件的記錄計數
val count = map.count(x => {
Integer.parseInt(x._1 + "") >= 2
})
println(count);
/* 對於filter和count中條件設定使用Integer.parseInt(x._1 + "")是因為:
* 定義map時,第一個key使用的是String型別,但在傳入函式時每一個KV轉化為一個二元組(Any,String)型別,x._1獲取Any型別的值,+""將Any轉化為String,最後再獲取Int值進行判斷.
*/
//contains判斷是否包含某個key
println(map.contains(2))
//exist判斷是否包含符合條件的記錄
println(map.exists(x =>{
x._2.equals("Scala")
}))
5. 元組
元組是Scala中很特殊的一種集合, 可以建立二元組, 三元組, 四元組等等, 所有元組都是由一對小括號包裹, 元素之間使用逗號分隔.
元組與List的區別: list建立時如果指定好泛型, 那麼list中的元素必須是這個泛型的元素; 元組建立後, 可以包含任意型別的元素.
建立元組即可使用關鍵字Tuple, 也可直接用小括號建立, 可以加 “new” 關鍵字, 也可不加. 取值時使用 "tuple._XX"獲取元組中的值.
- 元組的建立和使用
//建立元組
val tuple = new Tuple1(1)
val tuple2 = Tuple2("zhangsan",2)
val tuple3 = Tuple3(1,2.0,true)
val tuple4 = (1,2,3,4)
val tuple18 = (1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18)
//注意:使用Tuple關鍵字最多支援22個元素
val tuple22 = Tuple22(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22)
//使用
println(tuple2._1 + "\t" + tuple2._2)
//元組中巢狀元組
val t = Tuple2((1,2),("zhangsan","lisi"))
println(t._1._2)
- 元組的遍歷
//tuple.productIterator可以得到迭代器, 然後用來遍歷
val tupleIterator = tuple22.productIterator
while(tupleIterator.hasNext){
println(tupleIterator.next())
}
- toString, swap方法
//toString, 將元組中的所有元素拼接成一個字串
println(tuple3.toString())
//swap翻轉,只對二元組有效
println(tuple2.swap)
trait特性
Scala中的trait特性相對於Java而言就是介面. 雖然從功能上兩者極其相似, 但trait比介面還要強大許多: trait中可以定義屬性和方法的實現, 這點又有點像抽象類; Scala的類可以支援繼承多個trait, 從結果來看即實現多繼承.
Scala中定義trait特性與類相似, 不同在於需要使用"trait"關鍵字. 其他注意點在程式碼註釋中做出說明:
trait Read {
val readType = "Read"
val gender = "m"
//實現trait中方法
def read(name:String){
println(name+" is reading")
}
}
trait Listen {
val listenType = "Listen"
val gender = "m"
//實現trait中方法
def listen(name:String){
println(name + " is listenning")
}
}
//繼承trait使用extends關鍵字,多個trait之間使用with連線
class Person extends Read with Listen{
//繼承多個trait時,如果有同名方法或屬性,必須使用“override”重新定義
override val gender = "f"
}
object test {
def main(args: Array[String]): Unit = {
val person = new Person()
person.read("zhangsan")
person.listen("lisi")
println(person.listenType)
println(person.readType)
println(person.gender)
}
}
object Lesson_Trait2 {
def main(args: Array[String]): Unit = {
val p1 = new Point(1,2)
val p2 = new Point(1,3)
println(p1.isEqule(p2))
println(p1.isNotEqule(p2))
}
}
trait Equle{
//不實現trait中方法
def isEqule(x:Any) :Boolean
//實現trait中方法
def isNotEqule(x : Any) = {
!isEqule(x)
}
}
class Point(x:Int, y:Int) extends Equle {
val xx = x
val yy = y
def isEqule(p:Any) = {
/*
* isInstanceOf:判斷是否為指定型別
* asInstanceOf:轉換為指定型別
*/
p.isInstanceOf[Point] && p.asInstanceOf[Point].xx==xx
}
}
模式匹配match-case
Scala中的模式匹配match-case就相當於Java中的switch-case. Scala 提供強大的模式匹配機制, 即可匹配值又可匹配型別. 一個模式匹配包含一系列備選項, 每個備選項都以case關鍵字開始. 並且每個備選項都包含了一個模式以及一到多個表示式, 箭頭符號 => 隔開了模式和表示式。
object Lesson_Match {
def main(args: Array[String]): Unit = {
val tuple = Tuple7(1,2,3f,4,"abc",55d,true)
val tupleIterator = tuple.productIterator
while(tupleIterator.hasNext){
matchTest(tupleIterator.next())
}
}
/**
* 注意
* 1.模式匹配不僅可以匹配值,還可以匹配型別
* 2.模式匹配中,如果匹配到對應的型別或值,就不再繼續往下匹配
* 3.模式匹配中,都匹配不上時,會匹配到case _ ,相當於default
*/
def matchTest(x:Any) ={
x match {
//匹配值
case 1 => println("result is 1")
case 2 => println("result is 2")
case 3 => println("result is 3")
//匹配型別
case x:Int => println("type is Int")
case x:String =