
python爬蟲-lxml匹配
一、lxml匹配
lxml 是python三方的結構匹配模組, lxml是python的一個解析庫,支援HTML和XML的解析,支援XPath解析方式,而且解析效率非常高
1.lxml匹配步驟
(1)匯入模組:
from lxml import etree(2)lxml在爬蟲匹配當中具有相當固定的套路
① 將爬蟲獲取到的HTML字串轉換為HTML結構圖
② xpath匹配獲取資料
2.lxml匹配結果處理
text 返回匹配標籤的文字
tag 返回匹配標籤的名字
attrib 返回匹配標籤的屬性
(1)html程式碼部分
# coding:utf-8 import requests from lxml import etree html = ''' <div> <ul> <li name="suner" class="one">suner</li> <li name="wjk" class="two">wjk</li> <li name="wang" class="three">wang</li> <li name="karry" class="four">karry</li> </ul> </div> '''
# lxml在爬蟲匹配當中具有相當固定的套路
# 1.將爬蟲獲取到的HTML字串轉換為HTML結構圖
HTML = etree.HTML(html)# 2.xpath匹配獲取資料
|
 |
3.lxml常用語法
(1) //
// :遞迴層整個HTML裡面所有的
(2) /
/ :代表HTML結構的下一層,一定是直屬的下一層,必須一層一層寫,比較繁瑣,但是是程式生成xpath的首選,我們在瀏覽器的除錯模式下可以複製到類似的xpath
瀏覽器拷貝的xpath://*[@id="qiushi_tag_121089034"]/div[2]/a/img
(3) 索引
[]索引(從1開始)主要用於短期快速匹配
# 匹配li標籤的第四個索引
result = HTML.xpath('//div/ul/li[4]')

(4) @屬性
[@]屬性
上述匹配方式,如果頁面載入慢,或者非同步載入,或者開發者添加了一個li那匹配就失效了那麼我們用屬性精確匹配,我們在爬蟲當中首選
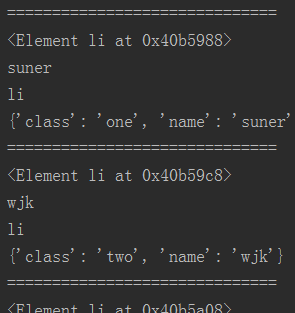
① result = HTML.xpath('//li[@name="suner"]') 匹配name=suner的值
|
<Element li at 0x40b5988> suner li {'name': 'suner', 'class': 'one'} |
② result = HTML.xpath('//li/@name') 匹配所有name屬性的值
|
suner |