
【SQL】SQL基本操作
SQL基本操作
庫操作(DDL)
對資料庫的增刪改查
基本語法
1. 建立資料庫
Create database 資料庫名[庫選項];
庫選項:用來約束資料庫,分為兩個選項
字符集設定:charset/character set 具體字符集.常用:GBK, UTF8
校對集設定:collate 具體校對集(資料比較的規則)(不用設定,與你設定的字符集自動匹配)
2. 檢視資料庫
檢視所有資料庫:show databases;
檢視指定部分的資料庫:模糊查詢:show databases like ‘pattern’;
Pattern:匹配模式
%:匹配所有字元
_:匹配單個字元
如果資料庫名中含‘_’,那麼只用匹配時需要使用\_對下劃線進行轉義
檢視資料庫的建立語句:Show create database 資料庫名字;
3. 更新資料庫
資料庫名字不可以修改
資料庫的修改僅限庫選項:字符集和校對集(校對集依賴字符集)
Alter database 資料庫名字 charset/character set [=] 字符集;
4. 刪除資料庫
Drop database 資料庫名;
注意:刪除不可逆,謹慎操作!
表操作(DDL)
1. 新增表
普通方式:
create table [if not exists] 表名(
欄位1 資料型別 [欄位屬性|約束] [索引] [註釋],
……
欄位n 資料型別 [欄位屬性|約束] [索引] [註釋]
)[表型別] [字符集] [註釋];
高階方式:
Create table 表名 like 資料庫.表名;
-從已有表中複製,只複製結構,不復制資料
2.查看錶
檢視全部表:show tables;
模糊查詢:show tables like ‘pattern’;
查看錶建立語句:show create table 表名:
查看錶結構:desc/describe/show columns from 表名;
3.修改表
3.1 修改表本身
修改表名
A: rename table 舊錶名to 新表名;
B: alter table 舊錶名rename [to] 新表名;
修改表選項:
Alter table 表名錶選項 [=] 值;
3.2 修改欄位
新增欄位:alter table 表名 add [column] 欄位名 資料型別 [列屬性][位置];
位置:欄位名可以存放表中的任意位置
First:第一個位置
After:在哪個欄位之後:after 欄位名;
修改欄位:修改通常是修改屬性或者資料型別
Alter table 表名 modify 欄位名 資料型別 [型別][位置];
重新命名欄位:alter table 表名 change 舊欄位 新欄位名 資料型別[屬性][位置];
刪除欄位:alter table 表名 drop 欄位名;
4. 刪除表
Drop table 表名1,表名2,…,表名n;
資料操作(DML)
1. 新增資料
全部欄位插入資料
Insert into 表名values (值列表);
Insert into 表名 values (值列表1),(值列表2),…(值列表n);
CREATE TABLE 新表(SELECT 欄位1,欄位2....FROM 原表);
如果新表已存在,不能重複建立
非數值型別的值建議使用單引號包裹
部分欄位插入資料
Insert into 表名(欄位列表) values (),(),();
主鍵衝突:當主鍵存在衝突的時候(duplicate key),可以選擇性的進行處理:更新和替換
Insert into 表名(欄位列表) values (值列表) on duplicate key update 欄位=新值;
Replace into 表名[(欄位列表)] values (值列表);
蠕蟲複製
定義:從已有的資料中去獲取資料,然後將資料又進行新增操作:資料成倍的增加
語法:
Insert into 表名 select (欄位列表) from 表名;
意義:
從已有表拷貝資料到新表
可以迅速的讓表中的資料膨脹到一定的資料量級,測試表的壓力及效率
2. 檢視資料(DQL)
檢視所有資料
基本語法
Select */欄位列表 from 表名 [where 條件];
完整語法
select[select 選項] 欄位列表[欄位別名]/* from 資料來源 [where條件子句] [group by子句] [having 子句] [order by子句][limit 子句];
select選項:select 對查出來的結果的處理方式
all:預設的,保留所有的結果
distinct:去重,將查出結果的重複項去除(所有欄位都相同)
![]()
欄位別名:
當資料進行查詢出來的時候,有時候名字不一定就滿足需求(多表查詢的時候,會有同名欄位),需要對欄位名進行重新命名:別名
語法:欄位名 [as] 別名;

資料來源:
資料的來源,關係型資料庫的來源都是資料表:本質上只要保證資料類似二維表最終都可以作為資料來源
資料來源的分類:多表資料來源,查詢語句
單表資料來源:select * from 表名;
多表資料來源:select * from 表名1,表名2...;
從一張表中取出一條記錄,去另一張表總匹配所有記錄,而且全部保留:(記錄數和欄位數),將這種結果稱為:笛卡爾積(交叉連線),其並沒有什麼用處,所以避免使用
查詢語句(子查詢):select * from (select語句) as 別名;
因為資料應該是一張表,所以給別名
where子句:
用來判斷資料,篩選資料(在磁碟讀取時就進行篩選了)
where子句的返回結果:0或者1,0代表false,1代表true
判斷條件:
比較運算子:>,<,>=,<=,!=,<>,=,like ,between and ,in/not in ,is null/is not null
邏輯運算子:&&(and),||(or),!(not)
where原理:where是唯一一個直接從磁盤獲取資料的時候就開始判斷的條件:從磁碟取出一條記錄,開始進行where判斷,判斷的結果如果處理,就儲存到記憶體,如果失敗就直接放棄
group by:分組
根據某個欄位進行分組(相同的放一組,不同的分到不同的組)
基本語法:group by欄位名 [asc||desc];
asc:欄位升序排列;desc:欄位降序排列

分組的意義是為了統計資料(按組統計:按分組欄位進行資料統計)
SQL提供了一系列統計函式
Count():統計分組後的記錄數,每一組有多少條記錄
括號裡面如果放欄位的話(null不被統計)
Max():統計每組中的最大值
Min():統計最小值
Avg():統計平均值
Sum():統計和
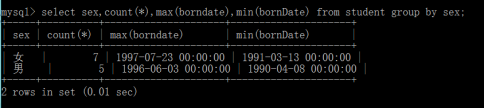
多欄位分組排序group by 欄位1,欄位2…;
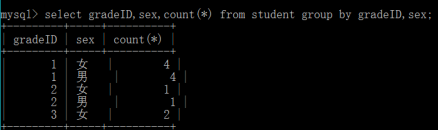
對分組的結果的某個欄位進行字串連結的函式:group_concat(欄位)
回溯統計:with rollup:任何一個分組後都會有一個小組,最後根據當前分組的欄位向上級分組進行彙報統計,這就是回溯統計,回溯統計的時候會將分組欄位置空

Having子句
與where子句一樣,進行條件判斷
區別:where是針對磁碟資料進行判斷:進入到記憶體之後,會進行分組操作,分組結果需要使用having來處理
Having能做where能做的幾乎所有事情,但是where卻不能做having能做的很多事情
- 分組統計的結果或者說統計函式都只有having能夠使用

- Having能夠使用欄位別名,where不能,別名是在記憶體中才有的

Orderby子句
排序,根據某個欄位進行升序或者降序排序,依賴校對集
基本語法:
Order by 欄位名 [asc|desc]; -- asc:預設,升序;desc:降序
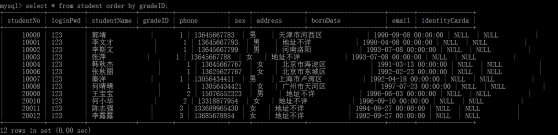
多欄位排序
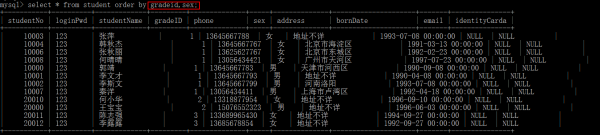
Limit子句
2種使用方式
- 只用來限定長度(資料量):limit 資料量;
- 限制起始位置,限制資料量:limit 起始位置,資料量;
連線查詢
定義:將多張表進行記錄的連線(按照某個制定的條件進行資料拼接);
最終結果是:記錄數有可能變化,欄位數一定會增加
連線查詢的意義:在使用者檢視資料的時候,需要顯示的資料來自多張表
連線查詢:join,使用方式:左表 join 右表
左表:在join關鍵字左邊的表
右表:在join關鍵字右表的表
連線查詢分類
交叉連線
Cross join,從一張表中迴圈取出每條記錄,每條記錄都去另外一張表進行匹配,匹配一定保留,而連線本身欄位會增加,最終形成的結果叫:笛卡爾積
基本語法:左表 cross join 右表; ===========from 左表,右表;
笛卡爾積沒有意義,應該儘量避免
內連線
[inner] join:從左表中取出每一條記錄,去右表中與所有的記錄進行匹配,匹配必須是某個新增在左表中與右表中相同最終才會保留結果,否則不保留
基本語法:
左表 [inner] join 右表 on 左表.欄位=右表.欄位;
On表示連線條件:條件欄位就是代表相同的業務含義
內連線還可以使用where代替on關鍵字(where沒有on效率高)
注意:由於不同表的欄位名可能相同,所以可以使用別名
欄位別名以及表別名的使用:在查詢資料的時候,不同表有同名欄位,這個時候需要加上表名才能區分,而表名太長,通常可以使用別名
語法: 欄位名/表名 [as] 別名
外連線
Outer join,以某張表為主,取出裡面的所有記錄,然後每條與另外一張表進行連線:不管能不能匹配上條件,最終都會保留
能匹配,正確保留,不能匹配,其他表的欄位都置空NULL
外連線的分類,以哪張表為主,有主表
Left join:左外連線(左連線),以左表為主表
Right join:右外連線(右連線),以右表為主表
基本語法:左表 left/right join 右表 on 左表.欄位 = 右表.欄位;
自然連線
Natural join,就是自動匹配連線條件:系統以欄位名作為匹配條件(同欄位名就作為條件,如果多個欄位同名,那麼就都作為匹配條件)
語法:
自然內連線:左表 natural join 右表;
自然外連線: 左表 natural left/right join 右表;
聯合查詢
將多次查詢(多條select語句),在記錄上進行拼接(欄位不會增加)
基本語法:
多條select語句構成,每一條select語句獲取的欄位數必須嚴格一致(但是欄位型別無關)
Select語句:
Select語句1 union [union 選項] select 語句2 union ….union 語句n;
Union 選項:與select選項一樣有兩個
All:保留所有(不管重複)
Distinct(預設使用):去重(整個重複),

聯合查詢的意義
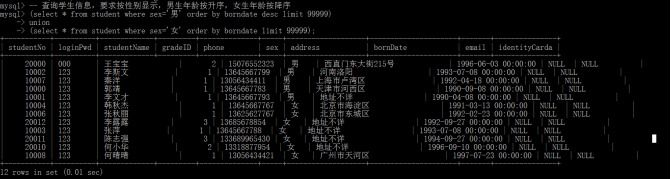
- 查詢同一張表,但是需求不同,如查詢學生資訊,男生身高升序,女生身高降序
- 多表查詢:多張表的結構是完全一樣的,儲存的資料(結構)也是一樣的
Order by 的使用
- 聯合查詢中,order by不能直接使用,需要對查詢語句使用括號
- 搭配limit 使用,limit使用限定的最大數即可
子查詢
分類:
按位置分類:子查詢在外部查詢中出現的位置
From子查詢:子查詢跟在from之後
Where子查詢:子查詢跟在where之後
詢:子查詢出現在exists裡面
按結果分:根據子查詢得到的資料進行分類
標量子查詢:子查詢得到的結果是一行一列
列子查詢:子查詢得到的結果是一列多行
行子查詢:子查詢得到的結果是多列一行(多行多列)
Select * from 表名 where (欄位列表)=(select語句);

上面幾個出現的位置都是在where之後
表子查詢:子查詢得到的結果是多行多列(出現的位置是在from之後)
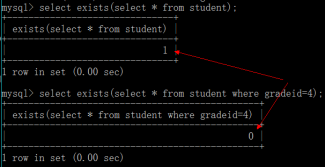
Exists/notexists查詢
此查詢用於判斷某些條件是否滿足(跨表),exists是接在where之後,exists返回結果只有0和1
語法:select … from 表名 where exists(子查詢);
1. 更新資料
Update 表名 set 欄位 = 值 [where 條件]; -- 建議都有where:不然就是更新全部
2. 刪除資料
刪除是不可逆的,謹慎操作
Delete from 表名 [where 條件]
字符集問題
顯示當前所有字符集:show character set;
查詢當前使用的字符集:show variables like 'character_set%';
設定字符集:set names gbk;
修改資料庫字符集 :alter database 資料庫名 default character set 'utf8';
– character_set_server:預設的內部操作字符集
– character_set_client:客戶端來源資料使用的字符集
– character_set_connection:連線層字符集
– character_set_results:查詢結果字符集
– character_set_database:當前選中資料庫的預設字符集
– character_set_system:系統元資料(欄位名等)字符集