
tcp/ip詳解卷一(筆記3:tcp與相關協議)
相關文章:
tcp/ip詳解卷一(筆記1:概述與IP層協議)
tcp/ip詳解卷一(筆記2:UDP及相關的協議)
tcp/ip詳解卷一(筆記3:tcp與相關協議)
文章目錄
- 17 TCP:傳輸控制協議
- 18 TCP連線的建立和終止
- 19 TCP的互動資料流
- 20 TCP的成塊資料流
- 21 TCP的超時與重傳
- 22 TCP的堅持定時器
- 23 TCP的保活定時器
tcp 協議中包括如下內容:
- 如何建立連線、傳送方與接收方狀態轉化;
- 不同型別的資料傳輸:互動型與塊資料及其中相關的控制演算法;
- 資料可靠傳輸確認與定時管理
下面分章節對這裡的問題分開描述。
17 TCP:傳輸控制協議
本章主要對tcp協議做一個簡要的描述,包括協議特點,協議報文欄位描述等
17.1 tcp服務的可靠性
tcp協議的可靠性通過以下方式進行保證:
- 資料分塊,分成合適的大小傳輸,由tcp傳給ip的資訊成為報文段或是段;
- tcp傳送一個段後,啟動一個定時器,等待目的端確認收到這個報文段。如果超時前沒有收到,則重傳;
- 接收端收到資料確認無誤(通過檢驗)後,傳送確認;
- tcp會對收到的資料進行排序(IP資料包到達時可能會亂序);如果收到重複資料,則會丟失;
- 另外,tcp提供流量控制(接收方快取區);
17.2 tcp報文段

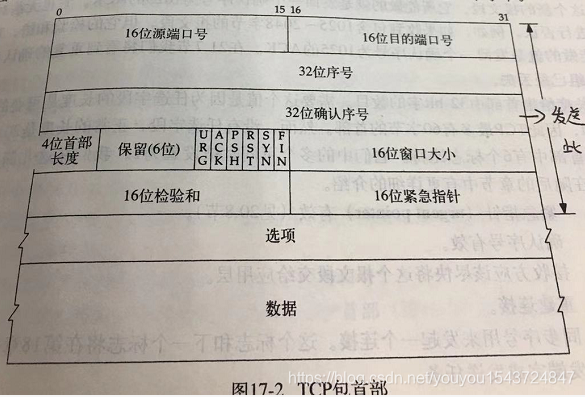
要點:
- 每個tcp段都包含源端和目的端的埠號,用於需找傳送端與接收端應用程序。TCP通過(傳送端IP:port,接收端IP:port)4元組唯一確定一個TCP連線。通常,一個IP地址和一個埠號為成為一個插口(socket)。04元組唯一確定一個TCP連線==。通常,一個IP地址和一個埠號為成為一個插口(socket)。
- 序號用於標識從TCP發端向TCP收端傳送的資料位元組流。如果將位元組流看作是在兩個應用程式間的單向流動,則TCP用序號對每個位元組進行計數;序號是一個無符號的整數。當新建一個連線時,syn標誌變1,序號欄位包含由這個主機選擇的該連線的初始序號ISN(initial sequence number)。該主機包傳送的第一個位元組序號為這個ISN加1(SYN也需要佔用一個序號)。傳送的ACK無需任何代價,32bit的確認序號欄位和ack一樣,總是tcp首部的一部分。
- tcp是全雙工的,資料能在兩個方向傳輸。因此,每一端都需要保持每個方向上的序號。
- tcp首部中的6個標誌bit分別為:urg(緊急指標)有效、ack有效、psh(對方應該經過提交這個報文到應用層,目前實現都不會延遲,所有該標註沒有實際的作用)、rst(重建連線)、syn(同步序號)、fin(傳送端完成傳送任務)。
18 TCP連線的建立和終止
本章主要描述tcp連線過程的各種狀態與注意問題
18.1 TCP連線狀態轉化圖
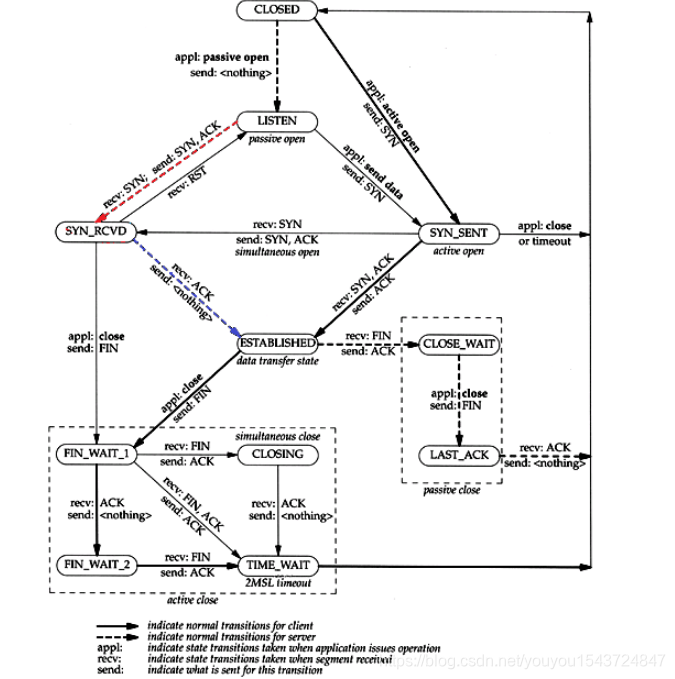
特殊情況處理如下描述
18.1.1 建立連線超時
連線超時分成兩種情況:
- 傳送端超時:如果傳送端傳送syn後,在定時器時間內沒有收到,則傳送端會重發。收到服務端的確認後,傳送syn的確認,連線就建立完成了。
- 接收端超時:server收到client的syn包,傳送syn+Ack,但是沒有收到對方的ack,則server端一直保持在syn_rcvd狀態(半開啟狀態),直到超時。(SYN_RCVD是TCP三次握手的中間狀 態,是服務埠(監聽埠,如應用伺服器的80埠)收到SYN包併發送[SYN,ACK]包後所處的狀態)另外一種情況是server收到client的syn包,傳送syn+Ack,但是沒有收到對方;
18.1.2 TCP的半關閉
tcp提供了連線的一端在結束後還能接收來自另外一端資料的能力。這就是所謂的半關閉。通過FIN報文進入半關閉狀態(設定tcp中的標誌位)。
利用tcp半關閉狀態的例子
使用unix 的rsh命令,遠端登入到另外一個系統執行一個命令,例如:
rsh nodeX sort < datafile
該命令就在nodeX上執行sort排序,排序的資料來源於本機檔案內容。rsh通過在目標節點上建立tcp連線,然後將要排序的資料傳送給目標機。那目標機什麼時候執行排序操作呢?他如何直到源節點已經發送完了資料,可以排序了呢(如果不等對端傳送完全部的資料,就執行排序是沒有意義的)。這裡就通過fin狀態。源節點發送完所有待排序資料後,就傳送Fin。等待目標節點執行完後,傳送結果給自己。
如果沒有這個特性的化,tcp還需要傳送一個特殊包,表示自己傳輸完畢。
18.1.3 time-wait與2MSL等待時間
time_wait狀態也稱為2MSL等待時間。每個具體tcp實現都必須選擇一個報文段最大生存時間MSL(maximum segment lifetime)。它是任何報文段被丟棄前在網路內的最大時間,該值是有限的(tcp資料封裝在IP中,而IP資料報存在TTL)。
當主動執行關閉連線的一方(連線雙方中第一個傳送FIN報文的一方)在收到fin ack,並收到對方fin,併發送fin ack後,進入time_wait狀態,且必須在該狀態保持2被MSL,防止對方沒有收到該fin ack而重發fin後,自己重發fin ack。
另外,在該2MSL等待時間內,這個連線相關的本地socket 埠不能再被使用。在該等待時間內,任何遲到的報文就被丟棄。
PS:如果停止伺服器,服務埠進入time_wait狀態,則該埠需要1到4分鐘才能被重新使用。因此,立馬重啟服務會丟擲端口占用的錯誤。
18.1.4 復位報文
無論何時,任何一個發往某一個連線的報文出現錯誤,TCP都會回覆一個復位報文。這裡出現錯誤的情況包括:
(1)發到對端,但是目的埠沒有程序監聽(對比udp,出現該種情況下,則會產生一個ICMP 埠不可達錯誤);
(2)連線異常終止。當建立連線後,通訊的一方(A)突然掛了,通訊的另外一方(B)是無法察覺的(如果不傳送資料)。然後A又重新啟動了,這是B還是在以前的連線上傳送資料給A,則會收到A的RST資料段;
(3)異常終止一個連線:正常終止一個連線通過傳送一個Fin訊息段。也可以主動傳送一個RST訊息段來異常終止一個連線(優點:會導致TCP丟棄任何待發資料,並立即傳送RST)
18.1.5 同時開啟和同時關閉
同時開啟連線:

同時關閉連線:
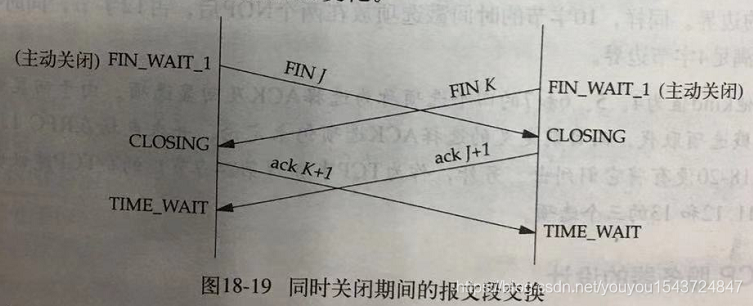
18.1.6 TCP伺服器對連線的處理
大多數TCP服務程序是併發的。當一個新的連線請求達到伺服器時,伺服器接收這個請求,並呼叫一個新的程序來處理這個新的客戶請求。那當一個伺服器程序接收一個來自客戶程序的服務請求時是如何處理埠的?
當啟動伺服器時,會啟動一個程序,監聽在服務埠上(通過netstat檢視,可看到state為LISTEN狀態的程序。)。當有client連線過來時,會重新建立一個程序,該程序使用者使用者處理該client的請求,該新的server程序依然在服務埠上和client通訊。

那在server端,處理不同client請求的程序(或執行緒)共用同一埠,那如何區分不同的Socket,收到資料後,怎麼分發呢?
由於TCP使用四元組(server ip,server port, client ip, client port)唯一標識一個連線,而client的遠端埠號不同,這不會造成衝突。
服務程式在listen某個埠並accept某個連線請求後,會生成一個新的socket來對請求進行處理,就可以區分客戶。
呼入連線請求佇列
一個併發伺服器呼叫一個新的程序來處理每個客戶請求,因此處理被動連線的伺服器應該始終準備處理下一個呼入的連線請求。但是當伺服器正常建立新的程序處理連線請求時,達到多個連線請求,TCP應該如何處理這些呼入的連線請求?
在伯克利的TCP實現中採用如下規則:
- 正等待連線請求的一端有一個固定長度的連線佇列,該佇列的連線已被TCP接收(即三次握手已經完成),但還沒有被應用層接收(TCP接收一個連線請求是將請求放入這個佇列,應用層接收是將其從佇列中移除);
- 應用層應該指明該佇列的最大值,這個值通常稱為積壓值。它的取值範圍是0 ~ 5之間;
- 當一個連線請求達到時,TCP使用一個演算法,根據當前的連線佇列數來確定是否接收這個連線。注意:積壓值說明的是TCP監聽的端點已被TCP接收而等待應用層接受處理的最大連線數。和併發伺服器最大併發處理數並沒有什麼關係;
- 如果對應新的連線,該TCP監聽端點的佇列中還有空間,則TCP模組收到的SYN進行確認並完成連線。對於應用層來說,只有在三次握手中的第三個報文收到後才會直到這個連線。另外,當客戶程序的主動開啟成功,但是伺服器的應用層還不知道這個連線(還處於佇列中),客戶程序會發送資料給伺服器(client端成功開啟,任務服務程序也完全準備好了),這時,伺服器的TCP模組僅將資料放入緩衝佇列;
- 對於新的連線,如果佇列沒有空間,則TCP不會理會收到的SYN報文,也不會發送任務的報文段。
- 處於佇列中的連線,如果應用層不能進行接受並處理,則這些連線可能會佔滿整個連線佇列,客戶最終會超時。
- 應用層接受到client連線請求後,三次握手已經完成了。應用層不能使client的主動開啟失效。這時,如果server不想服務這個client,只能傳送rst或是fin。
19 TCP的互動資料流
本章主要描述傳輸互動資料時可能會發生的經受時延的確認(資料捎帶ACK)、傳送資料時使用的Nagle演算法。
19.1 經受時延的確認(資料捎帶ACK)
在接收方收到資料包後,接收方可能不會裡面傳送ACK,而是會根據一些策略進行一定時間的推遲。資料捎帶ACK就是一種推延策略,在接收方傳送資料時,順便確認,減小網路中的資料包。
互動資料特點:資料量較小,但是資料段數量較多。以Rlogin 為例,和遠端系統通訊,需要回顯我們鍵入的字元。當發生一次按鍵後,發生的tcp通訊流如下所示(在建立好連線後)。
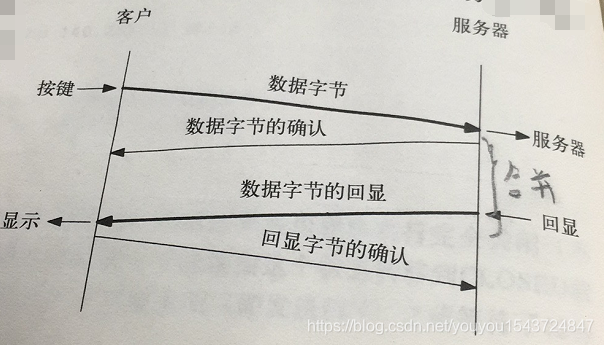
在實際中,一般會將報文2,3進行合併,即資料捎帶ACK。這種合併技術稱為經受時延的確認。
當TCP接收到一個數據段DS後,會啟動一個定時器,如果在定時器超時前,有資料要傳送,則將該資料段DS的ACK和要傳送的資料一起傳送出去。如果一直沒有資料要傳送,則定時器超時時,單獨傳送DS的ACK。
19.2 Nagle演算法
Nagle演算法要求:在一個TCP連線上最多隻能有一個未被確認的未完成的小分組,在該分組的確認達到之前不能傳送其他的小分組(即傳送一個數據段,然後等待ACK。在等待期間,快取將要傳送的資料,當收到ACK後,一次性的將資料傳送出去)。 TCP收集這些小量的資料,並在上一個分組的確認到達的時候,將收集的資料在一個分組傳送出去。 該演算法的優越之處在於 該演算法是自適應的:確認達到越快,資料也傳送的越快(ACK達到的越快,則網路情況越好,即不太可能會擁塞,則不必為了網路的整體質量,增加時延,將資料段儘快傳送出去)。
演算法使用場景:在一個rlogin連線上,客戶一般每次傳送一個位元組到伺服器,這就產生了一些41位元組的分組:20位元組的IP首部,20位元組的TCP首部和一位元組的資料。在區域網上,這些小分組通常不會引起麻煩,應為區域網一般不會擁塞。但是在廣域網中,這些小分組則會增加擁塞(廣域網資料量大)。一個簡單的就是使用RFC 896中建議的Nagle演算法。
注意:該演算法可以關閉,即不使用該策略。
另外,在某些互動應用中,如X視窗應用中,不能忍受長時延,即使只有一個字元也必須要立馬傳送,則需要關閉該演算法。在Socket API中,通過TCP_NODELAY來關閉Nagle演算法。
20 TCP的成塊資料流
本章主要描述TCP中的滑動視窗協議、慢啟動、緊急資料;
20.1 滑動視窗協議
在傳輸成塊資料時,更加在乎的是網路的吞吐量,即儘快在一段時間內多傳送資料,而不是每傳送一段資料,儘快給我反饋。那就需要傳送方儘量快的傳送資料,那是不是越快越好、僅本地網路最大頻寬,傳送呢?當然也不是,還需要考慮TCP接收方的處理速度。如果TCP都收到了資料,但是上層應用處理資料慢,資料一直放在緩衝區中,傳送方不停的發,最終肯定會耗盡接收方的緩衝區(快的傳送方與慢的接收方問題)
那接收方如何告訴傳送方自己的處理能力呢?這就是滑動視窗協議要做的事。通過TCP首部中的視窗欄位,告知傳送方自己的當前視窗情況。
視窗更新示例:通訊報文如下圖所示。
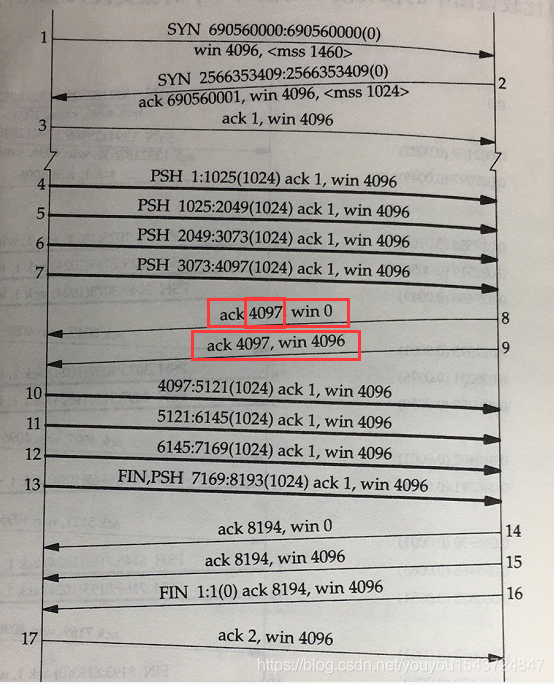
- 通過1,2,3個數據段,建立TCP連線;
- 傳送方傳送4,5,6,7四個資料段;
- 在收到4,5,6,7個數據段後,傳送ACK,同時告知自己的緩衝區滿了,接收視窗為0,傳送方停止傳送資料;
- 通過第9個重複的ACK,重新整理接收視窗(該報文看起來像個ACK,但由於並不確認任何資料,至少用於增加視窗右邊沿,也被稱為 視窗更新)
- 。。。。
20.2 慢啟動
那在建立TCP連線後(主動建立連線的client會收到Server的syn+ack包,該包會告知client的當前視窗),那client直到當前視窗後,是不是就可以裡面一直使勁的傳送,直接撐死Server的TCP接收快取視窗呢?當然也不是,傳送方不知道當前自己所處的通訊網路的擁塞情況。舉個例子,通過A和D通訊,中間經過BC路由器(A–>B–>C–>D),而BC路由器所處的網路情況不好。A在這使勁的發,把自己的電腦卡的要死,但是BC網路差,丟包嚴重,資料無法傳給D,D壓根就收不到,那麼A會在一定時間還沒有收到ACK後,又要重傳。最後效果是A不停的發,D收不到幾個,且還大大的加重了BC網路的擁塞情況。費力不討好。
那A怎麼傳送才是最優的呢?如果感知網路通訊質量呢?這就是慢啟動要做的事
TCP支援一種稱為“慢啟動”的演算法。該演算法基本思想:新分組進入網路的速率應該與另一端返回確認的速率相同。
慢啟動為傳送方的TCP增加了另一個視窗:擁塞視窗,記為cwnd。當與另一個網路的主機建立TCP連線時,擁塞視窗被初始化為1個報文段(即在收到確認前,只能有一個未被確認的資料段)。每收到一個ACK,擁塞視窗就增加一個報文段。傳送方取擁塞視窗與通告視窗中的最小值為傳送上限。擁塞視窗是傳送方使用的流量控制,而通告視窗(rwnd)是接收方使用的流量控制。
cwnd在達到閾值前呈指數級增長:假定當前cwnd=1,收到對端的ACK後變為2,若接下來發送的兩個資料包又收到ack,則cwnd=4;
慢啟動閾值ssthresh:隨著cwnd的增加,可能會導致網路過載即出現丟包,此時cwnd的大小會迅速衰減至當前的一半;一旦觸發了慢啟動閾值,cwnd趨於線性增長,以避免再次迅速引發網路阻塞,直至下次丟包(如此反覆)。
網路中實際傳輸的未經確認的資料大小 = min(rwnd, cwnd);
那擁塞視窗和通告視窗的最佳大小是多少呢?
網路中的傳輸通道容量為:
Capicity(bit)= bandwidth(b/s) * rount-trip time(s)
該值稱為寬度時延乘積。在網路中,最佳穩定狀態是每傳送一個數據包,就接收到一個ack。這樣,不管有多少個報文填充了網路傳輸通道,返回路徑上總有相同的ACK。傳送方接收方都不會有積壓的未處理的資料。一個報文的返回時間時為rount-trip time(s) 。這段時間要傳送一個包,能傳送的資料量就是傳送速度* 傳送時間。
rwnd的合理值取決 寬度時延乘積
cwnd 的合理值 計算公式:cwnd = min(4 * MSS, max(2 * MSS, 4380))
乙太網標準的MSS(maximum segment size)大小通常是1460,初始值為4380即3MSS。
20.3 緊急資料
https://blog.csdn.net/dhaiuda/article/details/79128584
20.3.1 什麼是緊急資料

當TCP中在首部設定了URG標誌後,在 16 位緊急指標的特定的位置(指向緊急資料的最後一位,也可以是緊急資料的下一位,兩者都是實現標準)的資料就是緊急資料。因為只有一個緊急指標,這也意味著它只能標識一個位元組的資料。這個指標指向了緊急資料最後一個位元組的下一個位元組。
對於16 位緊急指標配合使用,只有設定了URG標誌後,該指標才有效。
在讀取到緊急指標所指向的位置之前,TCP的接受程序都處於緊急狀態,當讀取到緊急資料後一位時,回覆到正常狀態。
從上面的特性可以看到,TCP無法告訴緊急資料從哪裡開始,只能告訴緊急資料從哪裡結束,URG位為1的TCP報文並不是帶外資料。抄襲一段百度上的解釋:
傳輸層協議使用帶外資料(out-of-band,OOB)來發送一些重要的資料,如果通訊一方有重要的資料需要通知對方時,協議能夠將這些資料快速地傳送到對方。為了傳送這些資料,協議一般不使用與普通資料相同的通道,而是使用另外的通道。但是TCP協議沒有真正意義上的帶外資料。為了傳送重要協議,TCP提供了一種稱為緊急模式(urgent mode)的機制。TCP協議在資料段中設定URG位,表示進入緊急模式。接收方可以對緊急模式採取特殊的處理。
20.3.2 關於帶外資料:
TCP協議沒有真正意義上的帶外資料,以下是我的理解,原因很簡單,從傳送主機到接收主機方向的通道只有一條,若要傳送帶外資料,不是還要建立另外一個TCP連線?TCP連線佔用的資源比較大,且連線的建立與釋放會耗費一定的時間,每次連線不一定都會頻繁的傳送緊急資料,甚至不會發送,此時佔用資源的利用率非常低,所以TCP協議不會有帶外資料。
20.3.3 緊急資料的一般位置計算方法
TCP 在傳輸資料時是有順序的,它有位元組號,URG 配合緊急指標,就可以找到緊急資料的位元組號。緊急資料的位元組號公式如下:
緊急資料位元組號(urgSeq)= TCP報文序號(seq) + 緊急指標(urgpoint)−1
例子,如果 seq = 10, urgpoint = 5, 那麼位元組序號 urgSeq = 10 + 5 -1 = 14.
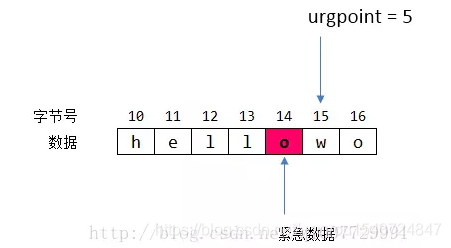
知道了位元組號後,就可以計算緊急資料字位於所有傳輸資料中的第幾個位元組了,如果從第 0 個位元組開始算起,那麼緊急資料就是第 urgSeq - ISN - 1 個位元組(還記得 ISN 嗎,它表示初始序列號),減 1 表示不包括第一個 SYN 段,因為一個 SYN 段會消耗一個位元組號。
20.3.4 TCP協議棧進入到緊急模式後做些什麼呢
(1)傳送端
傳送端也可以進入緊急模式,TCP協議棧會為每個套接字維護一個傳送端緊急模式標誌和一個傳送端緊急指標,當傳送端TCP協議棧得知有緊急資料要傳送時(即某個程序呼叫了send(MSG_OOB)函式),將傳送端緊急模式置為1,同時將緊急指標的值記錄在傳送端緊急指標處,隨後進入緊急狀態,(傳送緩衝區中)含有未傳送位元組到緊急位元組之間資料的報文都會將URG位置為1,設定緊急指標的值,進入緊急模式後,無論資料位元組是否發出,URG緊急通知都會發送( 資料流會因為TCP流量控制而停止,緊急通知總是無障礙的傳送到對端TCP),但緊急資料因為滑動視窗滿而不隨同傳送。當含有緊急位元組的報文傳送並確認接收後,傳送端會解除緊急狀態。

可以看到,第十一個欄位返回時指出了視窗大小為0,但sun還是傳送了含緊急通知的報文(第十二個欄位)。接著第十四個欄位中真正包含緊急資料。
(2)接收端
接收端TCP協議棧也會給每個套接字配上緊急模式標誌和緊急指標接收端在接收到TCP報文後,若發現TCP頭部的URG位為1,則將緊急模式標誌置為1,儲存緊急指標的值,隨後進入接收端緊急模式,通知接收程序。此後,TCP監聽每一個收到的資料欄位,若其中含有緊急位元組,則將該位元組放在單獨的帶外緩衝區中(獨立於接收緩衝區),如果接收端對套接字呼叫setsockopt開啟了SO_OOBINLINE,此位元組將混在普通資料中,稱為線上接收。在接收程序讀取資料時,只有在下一個待讀位元組越過緊急位元組之後,接收端緊急模式才被解除。
20.3.5 緊急資料的特點
- 緊急資料在傳送和接受時沒有特權,緊急資料時插入到普通的資料中進行流式傳送的。在TCP層面(非應用層),傳送端緩衝區中,只有先把緊急資料之前的普通資料傳送後才能傳送緊急資料。
- URG標誌緊急狀態,緊急資料是否正式到達需要依據緊急指標來判定(該指標指向的位置的資料如果還未到來,說明這個緊急資料還未被接收)。
21 TCP的超時與重傳
TCP 提供可靠的運輸層。它使用的方式之一就是確認從一另一端收到的資料。但資料和確認可能會丟失。TCP通過在傳送時設定一個定時器來解決這種問題。如果當定時器溢位時還沒有收到確認,它就重發該資料。那定時器時間應該設為多久呢?重複的頻率應該是什麼呢?本章主要講述RTT(Round Trip Time,表示從傳送端到接收端的一去一回需要的時間)的測量方式與RTO(超時重傳時間)如何確定,TCP如何發現包超時、如何決定重發,如何主動避免擁塞
21.1 RTT與RTO
由於路由器和網路流量均會變化,因此RTT會也會程序變化,TCP應該跟蹤這些變化並相應的改變其超時時間。
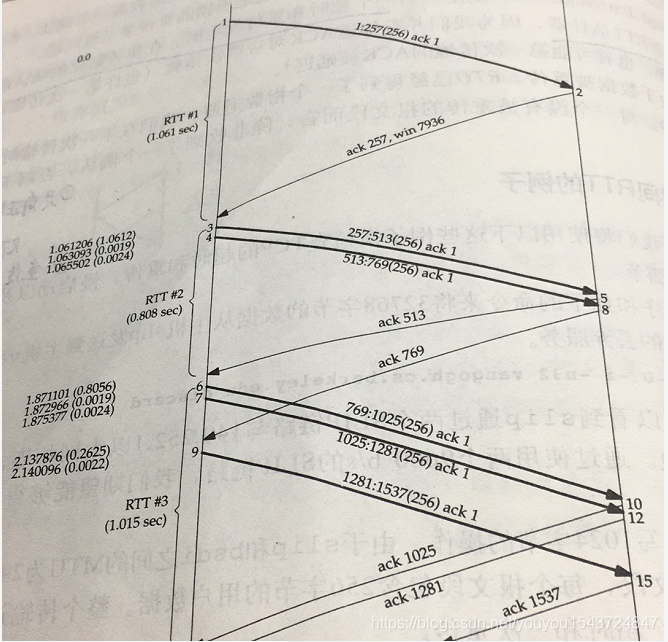
TCP通過記錄傳送的TCP資料段的時間和接收到該位元組的確認的時間來衡量RTT。如下圖,可通過報文4,7測量到一個RTT。

用M表示所測量到的RTT。最開始的TCP規範使用低通過濾器來更新一個被平滑的RTT估計器,即為R(即會對每次測量到的RTT進行平滑過濾處理)。
R=a*R+(1-a)M (式1)
這裡a是一個推薦值為0.9的平滑因子。每次進行新策略時,這個被平滑的RTT將會得到更新。
RFC 793推薦的重傳超時時間RTO(Retransmission timeout)的值為:
RT0=Rβ (式2)
其中β為推薦值為2的時延離散因子(即隨時間變化,每次自增兩倍,直到RTO變成64s封頂)
舉例:如果資料報D超時還沒有收到ACK,則首次在R時間後重傳,如果還沒有收到確認,則在2R後再次重傳,之後是4R…,直到增加到64s秒後,一直按照64s的間隔重傳。
** 另外,TCP還需要記錄RTT的方差。當RRT變化起伏很大時,使用基於均值和方差來計算RTO **,其計算公式如下:
Err=M-A
A=A+gErr
D=D + h(|Err | - D)
RTO = A + 4D
其中A表示被平滑的RTT。即上公式1計算出的值。D是被平滑的均值偏差。Err是剛得到的測量結果與當前RTT估計值之差。增量g起平均作用,取值為1/8。偏差的增益是h,取值為0.25。當RTT變化時,較大的偏差增益使得RTO快速上升。
21.1.1 ACK的多義性 與RTT的更新
當ACK超時,發生重傳後,收到一個ACK,則該ACK是對之前的包的確認還是對重傳包的確認呢?
當一個超時和重傳發生時,在重傳資料的確認最後到達時,不能更新RTT的估計值,因為我們不知道該ACK是針對那次資料傳輸。
另外,還有一種情況不不會進行RTT的更新,即:在傳送一個報文段時,如果給定連線的定時器已經被使用,則該報文段不被計時(即不會測量、記錄該報文的RTT)
舉例:
當傳送報文3 後,啟動了定時器,此時3包的ack沒有收到,則該定時器不會關閉,此時傳送了報文 4多個報文,則在收到4的ack也不會更新RTT(原因很簡單,傳送時,這幾個報文的傳送不會產生新的定時器,所有也無從計時)。這裡會在收到3的ack後,記錄到一個新的RTT。
21.1.2 小節
TCP會記錄追蹤RTT,並根據RTT來確定RTO(什麼時候應用重傳了)。當RTT比較平穩(方差較小時),使用 被平滑的RTT估計值公式估計RTT,並更新RTO。當RTT方差較大,使用均值偏差公式計算RTT和RTO。
另外,當發生重傳後,對重傳包的ACK不進行RTT的更新。
21.2 慢啟動、擁塞避免、快速重傳與快速恢復
本節主要講述TCP如何控制自己的傳送速度,以保證自己的傳輸速度,另外,在網路擁塞發生時,儘量控制自己的速度,造成網路情況的快速惡化。
TCP在開始建立連線後,會執行慢啟動來快速的增加自己的傳送速度。當傳送速度達到某一個值後,開始執行擁塞避免演算法來控制自己的傳送速度 。 但是網路還壞情況動態變化的,有時候,會發現一下網路異常情況,如包丟失,這時TCP會進行快速重傳,然後TCP傳送進入快速恢復階段。
相關變數:
- cwnd:擁塞視窗大小。初始化為1個報文段大小。
- ssthresh:慢啟動門限。初始化為65535位元組,當擁塞發生時,ssthresh=max( 2, min(cwnd, rwnd)/2)。
- rwnd:通告視窗,即TCP接收方告知的自己的接收緩衝區的大小;
- 傳送視窗:min(cwnd,rwnd);
擁塞的定義:
由於有份受到損壞引起的丟失是非常少的。因此,分組的丟失就意味者在源主機和目的主機之間的某處發生了擁塞。有兩種分組丟失的指示:發生超時和收到重複的確認。
21.2.1慢啟動
採用該演算法的條件:當 cwnd <= ssthresh
演算法執行過程:
- 開始時,將cwn初始化為1.
- 此後,每收到一個ACK,Cwnd加1。該種情況下,視窗按照指數方式增加。直到cwnd > ssthresh此後,每收到一個ACK,Cwnd加1。該種情況下,視窗按照指數方式增加。直到cwnd > ssthresh
- 另外,如果包超時引起了擁塞時,會重置cwnd 為1個報文段大小。
21.2.2擁塞避免
採用該演算法的條件:當 cwnd > ssthresh
演算法執行過程:
- 開始時,將ssthresh=65535位元組。當擁塞發生時(超時或是產生了重複的確認),ssthresh=max( 2, min(cwnd, rwnd)/2 )。
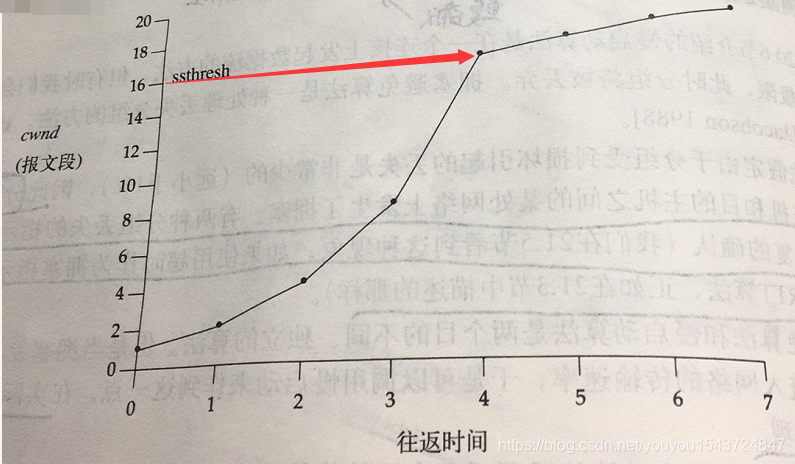
- 此後,每次收到一個確認時,將cwnd增加1/cwnd,cwnd處於線性增長。(在一個往返時間內,最多能傳送cwnd包,則在一個往返時間內,最多能收到接近於cwnd個的ack。則下次cwnd 趨近與cwnd+1 )。在一個往返時間內,cwnd最多增加一個報文段。(對比,慢啟動演算法中,在一個往返時間內,cwnd最多能增加cwnd)。
正常情況(沒有發生擁塞時),cwnd的增長曲線如下:
21.2.3快速重傳與快速恢復
TCP在收到一個失序的報文時,TCP立即產生一個ACK(重複的ACK,該重複的ACK的目的在於讓對方直到收到了失序的ACK,並告訴對方自己希望收到的序號) 。正常情況下,會是經受時延的確認,即資料捎帶ACK或是ACK確認時鐘超時後傳送(絕大多數實現,採用的時延是200ms,即TCP將以最大200ms的時延等待是否有資料一起傳送)。
由於我們不知道一個重複的ACK是由一個丟失的報文啟動的,還是由於因為出現了幾個報文段的重新排序,因此我們等待少量的ACK到來。如果只是一些重新排序,則在重新排序的被處理時,可能只會產生1~2個重複的ACK。如果收到3個或三個以上的重複ACK,就非常可能是一個報文段丟失了。於是立馬重傳丟失的報文段,而無需等待超時定時器溢位,這就是快速重傳。
快速重傳:當確定發生包丟失時,立馬重傳丟失的報文段,而無需等待超時定時器溢位,這就是快速重傳。
採用該演算法的條件:當發生快速重傳後,會進入快速恢復演算法
演算法執行過程:
- 如果收到3個或三個以上的重複ACK時,將ssthresh設定為當前cwnd的一半。重傳丟失的報文段;
- 設定cwnd為ssthresh加上三倍的報文段大小;
- 每次收到另外一個重複的ack,cwnd增加一個1個報文段大小,併發送1個分組(如果新的傳送視窗允許傳送);
- 當下一個確認新資料的ACK達到時,設定cwnd為ssthresh。該ACK應該是在進行重傳後的第一個往返時間內對步驟1中重傳的確認。另外,同時,這個ACK也應該對丟失分組和收到的第一個重複的ACK之間的所有的中間報文段的確認(例如,接收方收到了報文3,4,5,然後收到了7,8。報文6丟失,則在收到重傳的報文6後,確認的是報文8,一起確認了7和8)。之後恢復正常,進入擁塞避免階段,採用擁塞避免演算法。
22 TCP的堅持定時器
當TCP通過讓接收方指定希望從傳送方接收的自己樹(即視窗大小)來進行流量控制。如果當視窗變成0之後,傳送方會停止傳送新的資料,直到接收方傳送一個視窗更新報文。那麼如果該視窗更新報文丟失會怎麼樣呢?傳送方等待視窗更新,而接收方等待發送方傳送新的資料。TCP必須能夠處理此視窗更新報文丟失的情況。
TCP 的ACK傳輸並不可靠,TCP不會對ACK報文進行確認,只確認那些含有資料的ACK報文段(不然,會不停的、無休止的雙方確認下去)
為了防止視窗更新報文丟失引起了雙方相互等待,傳送方使用一個檢查定時器(persist timer)來週期性的向接收方查詢,以便發現視窗是否增加。這些傳送方發成的報文段稱為視窗探查。
當TCP傳送方收到一個通告視窗為0的報文時,傳送方設定其堅持定時器。如果該定時器時間到時還沒有收到視窗更新報文,則傳送方傳送視窗探查報文,查詢這個視窗更新報文是否丟失。
定時器的時間序列:堅持定時器使用了普通的TCP指數退避,對於一個典型的區域網連線,檢測定時器首次超時時間1.5s左右,第二次超時增加一倍,為3s,下次乘以4,再下次乘以8…
==視窗探查報文:==包含一個位元組的資料。TCP總是允許傳送已關閉的視窗之後的一個位元組的資料(如果視窗更新了,則會對該位元組進行確認;否則確認是原先的資料,該新資料由於緩衝區慢,而丟棄了,不會進行確認)
基於視窗的流量控制方案,會導致“糊塗視窗綜合症”的狀態。如果發生這種狀況,則連線之間會發送少量的資料,而不是滿長度的報文段(即連線之間會存在小報文)
該種情況可發生在連線的任何一方:接收方通告一個小的視窗(而不是一直等到有大的視窗時才通告),而傳送方傳送少量的資料(而不是等待其他的資料以便傳送一個大的報文段),這兩種情況就是“糊塗視窗綜合症”的現象。為了避免這種情況(糊塗視窗綜合症),在視窗更新時,TCP採用如下的方法:
- 接收方不通告小視窗。通常的演算法是接收方不通告一個比當前大的視窗,除非視窗可增加一個報文段大小(也就是說要接收的化,接收MSS大小的資料)或者是增加接收方快取空間的一半,不論實際大小(也就是說,接收方接收視窗空閒區變化很小時,不會更新。如某個時候,快取區滿了,這是接收方傳送視窗為0的通告。然後一段時間後,接收應用程式讀取了3個位元組的資料,然後程式處理其他優先順序更高的事去了,TCP接收快取區空了3個位元組的空間,但是TCP不會更新這個3個位元組的變化,防止傳送方傳送只有三個位元組有效資料的小包);
- 傳送方避免出現“糊塗視窗綜合症”的措施是隻有以下條件之一滿足時,才傳送資料:1)可以傳送一個滿長度的報文段;2)可以傳送至少接收方通告視窗大小的一半的報文;3)能夠傳送手頭的所有資料,並且不希望接收ACK(傳送方沒有未被確認的資料)或是連線禁止了Nagle演算法。
23 TCP的保活定時器
正常情況下,在建立連線後,如果雙方都沒有傳送任何資料,只要兩端的主機沒有重啟,則連線會依然保持建立。
寶貨定時器的作用是:試圖檢測半開發的連線(例如,當client關閉後,伺服器還是保持連線,等待來自client的資料)。
注意:保活並不是TCP規範中的一部分。該功能也可以在應用級完成,如在應用層協議或是應用程式中實現。