
MapReduce shuffle和排序(理論層級)
什麼是shuffle:mapreduce確保每個reduce的輸入都是按鍵排序的,系統執行排序、將map輸出作為輸入傳給reducer的過程稱為shuffle。
零. 引
總體邏輯圖
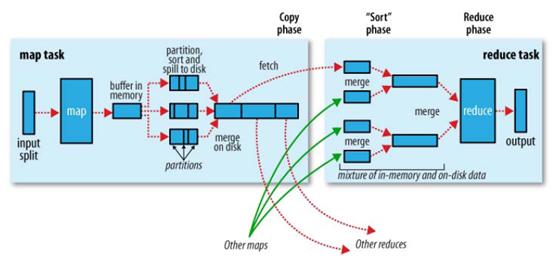
一. Map端
1. map溢寫
hadoop map與reduce任務之間的中間結果為磁碟儲存,但map任務並不是一開始即把輸出寫入檔案。map任務有一個環形緩衝區用於儲存任務輸出,預設大小為100M1,若輸出達到闕值(預設80%2),則會有一個後臺程序白記憶體溢寫到磁碟中。 檔案位置由mapreduce.cluster.local.dir屬性定義,一般位於本地磁碟中。每次溢寫操作會生成一個溢寫檔案。
特殊情況:若在溢寫過程中,剩餘20%記憶體被填滿時,map會被阻塞。
2. map分割槽、排序、合併
map任務在輸出到記憶體後,會根據一定規則進行分割槽3,然後針對該分割槽按鍵排序。此任務由一個後臺執行緒完成。任務完成之前溢位檔案會被合併為一個已分割槽且已排序的檔案。
3. map combiner
3.1 combiner函式說明
combiner函式:hadoop 的一個針對map任務輸出的優化函式,其結果會作為reduce任務輸入。並不是所有任務都適合於該函式,一般該函式用於計算最大值,最小值等(功能滿足結合律)功能。由於該函式屬於優化函式,其可能被呼叫0次到多次。其會使map輸出更加緊湊。其本質上相當於一個本地reduce操作。
3.2 combiner函式作用時間
在combiner函式指定之後,hadoop會在以下情況下呼叫該函式。
- 達到記憶體溢位闕值,寫入磁碟之前。
- 溢位檔案個數大於3個4,在合併前,會再次執行。
二. Reduce端
1. reduce任務的開始時間
reduce任務並不是等所有的map任務完成後才開始執行,reduce任務具有複製執行緒,在每個map任務完成後,複製執行緒便會複製其輸出。map任務全部完成且資料取完後,才開始進行reduce後續操作(複製完成前為複製階段)。
2. reduce如何獲取map端輸出檔案
map任務完成後,會使用心跳通知AM(所以AM知道map任務與node的對應關係),reduce有一個執行緒定期詢問AM以確定map位置,直到獲取所有檔案。 reduce預設有5個
3. map輸出儲存
若map輸出很小,其會被複制到reduce任務的JVM記憶體6中,否則會被複制到磁碟中。一旦記憶體緩衝區達到闕值7或達到map輸出闕值8,則合併後溢位寫入到磁碟中(斜體部分為hadoop權威指南原話,求指導)。若制定了combiner,則在合併期間執行它以降低寫入硬碟的資料量。磁碟中副本量變大時,後臺執行緒會將他們合併成更大的,排好序的檔案。map壓縮的輸出資料會在記憶體中解壓。
4. reduce的排序(或叫合併、歸併)階段
4.1 開始時間
reduce獲取到所有map輸出後即進入reduce階段。
4.2 主要任務
迴圈合併map輸出,維持其順序排序。生成reduce最後一趟所需檔案。
4.3 合併因子
合併因子,即每次合併的檔案數,預設為10,通過mapreduce.task.io.sort.factor屬性設定。假設有30個map輸出,合併因子為10,則其需要合併3趟。
合併時有個原則,即儘量減少磁碟IO。因此一般情況下,合併的目標是合併最少數量檔案以滿足最後一趟的合併係數。以如下為例:
有30個map輸出,合併因子為10,則在排序階段完成後結果為1, 1, 1 ,7,最後7個檔案未合併,合併完後,共10個檔案
3 ------> 1 第一趟
10 ------> 1 第二趟
10 ------> 1 第三趟
7 ------> 7 未合併
5. reduce階段
reduce直接對已排序輸出中的每個鍵呼叫reduce函式,此階段的輸出直接寫入到輸出檔案系統中。如果採用HDFS,由於節點NM也執行data node,因此第一個塊副本被寫到本地磁碟。
屬性由
mapreduce.task.io.sort.mb設定 ↩︎屬性由
mapreduce.map.sort.spill.percent設定,值為0.8或80% ↩︎對於map輸出的每一個鍵值對,系統都會給定一個partition,partition值預設通過計算key的hash值後對Reduce task的數量取模獲得。分割槽方式可自定義,詳見連結 ↩︎
屬性由
mapreduce.map.combine.minspills設定,預設為3 ↩︎屬性由
mapreduce.reduce.shuffle.parallelcopies設定。 ↩︎屬性由
mapreduce.reduce.shuffle.input.buffer.percent設定。 ↩︎屬性由
mapreduce.reduce.shuffle.merge.percent設定。 ↩︎屬性由
mapreduce.reduce.merge.inmem.threshold設定。 ↩︎