
python:用scrapy爬去天貓評論
阿新 • • 發佈:2018-12-21
1,建立scrapy startproject tb
2 , cd tb ,建立一個spider scrapy genspider 爬蟲名字 網站域名
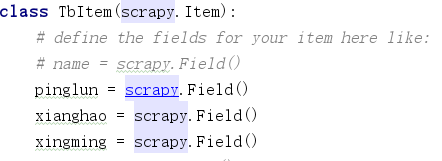
3, 在items中寫自己想爬的東西 ,這裡我爬的是評論 ,型號,使用者名稱
4,在pippelines.py寫儲存的方式 我這裡寫的是資料夾

5,seting裡面開啟
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 3
DOWNLOADER_MIDDLEWARES = {
'tb.middlewares.SeleniumMiddlewares': 543,
}
ITEM_PIPELINES = {
'tb.pipelines.TbPipeline': 300,
}
6 spdier.py 中
import scrapy
from scrapy import Request
import lxml.html
from tb.items import TbItem
class TaobaosSpider(scrapy.Spider):
name = 'tianmao1'
#allowed_domains = ['www.tianmao.com','detail.tmall.com']
#@property
def start_requests(self):
base_url = "https://detail.tmall.com/item.htm?spm=a220m.1000858.1000725.7.3c3f2a68kywm0p&id=549984903510&skuId=3721826599822&areaId=410100&user_id=370627083&cat_id=2&is_b=1&rn=da3c446a634049bd41933f1cde5d6d1f"
yield Request(url=base_url,callback=self.parse,dont_filter=True,meta={"page": "1"})
#start_urls = ['https://detail.tmall.com/item.htm?spm=a220o.1000855.0.da321h.739b68c88QNKJE&id=565262586274&skuId=4029282759058']
def parse(self,response):
item = TbItem()
tr_list = response.xpath('//div[@class="rate-grid"]/table/tbody/tr').extract()
for tr in tr_list:
html = lxml.html.fromstring(tr)
pinglun = html.xpath('//td[@class="tm-col-master"]/div/div[1]/text()')[0]
xinghao = html.xpath('//td[@class="col-meta"]/div/p/text()')[0]
xingming = html.xpath('//td[@class="col-author"]/div/text()')[0]
#time = html.xpath('//td[@class="tm-col-master"]/div[@class="tm-rate-date"]/text()')[0]
item["pinglun"]=pinglun
item["xianghao"]=xinghao
item["xingming"]=xingming
#item["time"]=time
yield item
yield Request(url="http://www.baidu.com",callback=self.parse,meta={"page": "2"},dont_filter=True)
7,在middlewares.py填寫class SeleniumMiddlewares(object):
def __init__(self):
self.options = Options()
#self.options.add_argument('-headless')
self.browser = webdriver.Chrome(executable_path="F:\第七重新爬蟲\day06\day06全天\ziliao\chromedriver.exe",chrome_options=self.options)
def process_request(self,request,spider):
if int(request.meta["page"]) == 1:
self.browser.get(request.url)
time.sleep(5)
for y in range(10):
self.browser.execute_script("window.scrollBy(0,220)")
time.sleep(3)
pages = self.browser.find_element_by_xpath('//li/a[@href="#J_Reviews"]')
pages.click()
time.sleep(5)
return HtmlResponse(url=self.browser.current_url,body=self.browser.page_source,request=request,encoding="utf-8")
if int(request.meta["page"]) == 2:
for y in range(20):
self.browser.execute_script("window.scrollBy(0,200)")
time.sleep(3)
pages = self.browser.find_element_by_link_text("下一頁>>")
self.browser.execute_script("arguments[0].click();", pages)
#pages.click()
return HtmlResponse(url=self.browser.current_url, body=self.browser.page_source, request=request,encoding="utf-8")
這裡用的Selenium模擬點選評論連結 獲取頁面 傳給spdier然後解析
8 ,啟動爬蟲 scrapy crawl 爬蟲名
