
python字典型別
字典型別簡介
字典(dict)是儲存key/value資料的容器,也就是所謂的map、hash、關聯陣列。無論是什麼稱呼,都是鍵值對儲存的方式。
在python中,dict型別使用大括號包圍:
D = {"key1": "value1",
"key2": "value2",
"key3": "value3"}dict物件中儲存的元素沒有位置順序,所以dict不是序列,不能通過索引的方式取元素。dict是按照key進行儲存的,所以需要通過key作為定位元素的依據,比如取元素或修改key對應的value。比如:
D['key1'] # 得到value1 D['key2'] # 得到value2 D['key3'] # 得到value3
字典的結構
dict是一個hashtable資料結構,除了資料型別的宣告頭部分,還主要儲存了3部分資料:一個hash值,兩個指標。下面詳細解釋dict的結構。
下面是一個Dict物件:
D = {"key1": "value1",
"key2": "value2",
"key3": "value3"}它的結構圖如下:
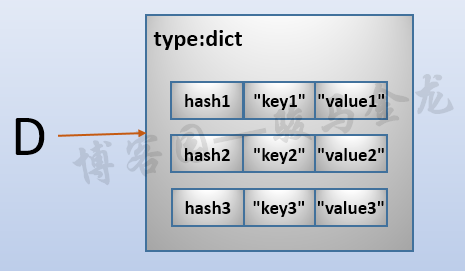
這個圖很容易理解,key和value一一對應,只不過這裡多加了一個hash值而已。但這只是便於理解的結構,它並非正確。看原始碼中對dict型別的簡單定義。
typedef struct { /* Cached hash code of me_key. */ Py_hash_t me_hash; PyObject *me_key; PyObject *me_value; } PyDictKeyEntry;
從原始碼中可知,一個hash值,這個hash值是根據key運用內建函式hash()來計算的,佔用8位元組(64位機器)。除了hash值,後面兩個是指標,這兩個指標分別是指向key、指向value的指標,每個指標佔用一個機器字長,也即是說對於64位機器各佔用8位元組,所以一個dict的元素,除了實際的資料佔用的記憶體空間,還額外佔用24位元組的空間。
所以,正確的結構圖如下:
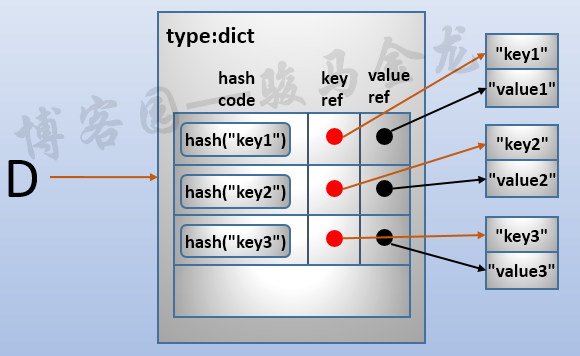
對於儲存dict元素的時候,首先根據key計算出hash值,然後將hash值儲存到dict物件中,與每個hash值同時儲存的還有兩個引用,分別是指向key的引用和指向value的引用。
如果要從dict中取出key對應的那個記錄,則首先計算這個key的hash值,然後從dict物件中查詢這個hash值,能找到說明有對應的記錄,於是通過對應的引用可以找到key/value資料。
dict是可變的,可以刪除元素、增加元素、修改元素的value。這些操作的過程與上面的過程類似,都是先hash,並根據hash值來儲存或檢索元素。
這裡需要注意的是,在python中,能hashable的資料型別都必須是不可變型別的,所以列表、集合、字典不能作為dict的key,字串、數值、元組都可以作為dict的key(類的物件例項也可以,因為自定義類的物件預設是不可變的)。
# 字串作為key
>>> D = {"aa":"aa","bb":"bb"}
>>> D
{'aa': 'aa', 'bb': 'bb'}
# 數值作為key
>>> D = {1:"aa","bb":"bb"}
>>> D[1]
'aa'
# 元組作為key
>>> D = {(1,2):"aa","bb":"bb"}
>>> D
{(1, 2): 'aa', 'bb': 'bb'}
# 列表作為key,報錯
>>> D = {[1,2]:"aa","bb":"bb"}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'字典元素的順序改變
因為元素儲存到dict的時候,都經過hash()計算,且儲存的實際上是key對應的hash值,所以dict中各個元素是無序的,或者說無法保證順序。所以,遍歷dict得到的元素結果也是無序的。
# python 3.5.2
>>> d = {'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> d
{'four': 4, 'two': 2, 'three': 3, 'one': 1}無序是理論上的。但是在python 3.7中,已經保證了python dict中元素的順序和插入順序是一致的。
Changed in version 3.7: Dictionary order is guaranteed to be insertion order. This behavior was an implementation detail of CPython from 3.6.
# python 3.7.1
>>> d = {'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> d
{'one': 1, 'two': 2, 'three': 3, 'four': 4}雖保證了順序,但後面介紹dict的時候,仍然將它當作無序來解釋。
字典和列表的比較
python中list是元素有序儲存的序列代表,dict是元素無序儲存的代表。它們都可變,是python中最靈活的兩種資料型別。
但是:
- dict的元素檢索、增刪改速度快,不會隨著元素增多、減少而改變。但缺點是記憶體佔用大
- list的元素檢索、增刪改速度隨著元素增多會越來越慢(當然實際影響並沒有多大),但是記憶體佔用小
換句話說,dict是空間換時間,list是時間換空間。
其實從dict和list的資料結構上很容易可以看出dict要比list佔用的記憶體大。不考慮儲存元素的實際資料空間,list儲存每個元素只需一個指標共8位元組(64位機器)即可儲存,而dict至少需要24位元組(64位機器)。
構造字典
有幾種構造字典的方式:
- 使用大括號包圍
- 使用dict()構造方法,dict()構造有3種方式:
- dict(key=value)
- dict(DICT)
- dict(iterable),其中iterable的每個元素必須是兩元素的資料物件,例如
("one",1)、["two",2]
- 後兩種都可以結合第一種方式
- dict(key=value)
- 使用dict物件的fromkey()方法
- 使用dict物件的copy()方法
- 字典解析的方式。這個在後文再解釋
>>> D = {} # 空字典
>>> type(D)
<class 'dict'>
>>> D = {"key1": "value1",
"key2": "value2",
"key3": "value3"}
>>> D
{'key1': 'value1', 'key2': 'value2', 'key3': 'value3'}
>>> a = dict(one=1, two=2, three=3)
>>> b = {'one': 1, 'two': 2, 'three': 3}
>>> c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
>>> d = dict([('two', 2), ('one', 1), ('three', 3)])
>>> e = dict({'three': 3, 'one': 1, 'two': 2})
>>> f = dict([('two', 2), ('one', 1), ('three', 3)], four=4, five=5)fromkey(seq,value)是dict的類方法,所以可直接通過dict類名來呼叫(當然,使用已存在的物件來呼叫也沒有問題)。它構造的字典的key來自於給定的序列,值來自於指定的第二個引數,如果沒有第二個引數,則所有key的值預設為None。所以,第二個引數是構造新dict時的預設值。
例如,構造一個5元素,key全為數值的字典:
>>> dict.fromkeys(range(5))
{0: None, 1: None, 2: None, 3: None, 4: None}
>>> dict.fromkeys(range(5), "aa")
{0: 'aa', 1: 'aa', 2: 'aa', 3: 'aa', 4: 'aa'}再例如,根據已有的dict來初始化一個新的dict:
>>> d = dict(one=1, two=2, three=3, four=4, five=5)
>>> dict.fromkeys(d)
{'one': None, 'two': None, 'three': None, 'four': None, 'five': None}
>>> dict.fromkeys(d, "aa")
{'one': 'aa', 'two': 'aa', 'three': 'aa', 'four': 'aa', 'five': 'aa'}因為key的來源可以是任意序列,所以也可以從元組、列表、字串中獲取。
>>> dict.fromkeys("abcd","aa")
{'a': 'aa', 'b': 'aa', 'c': 'aa', 'd': 'aa'}
>>> L = ["a", "b", "c", "d"]
>>> dict.fromkeys(L)
{'a': None, 'b': None, 'c': None, 'd': None}
>>> T = ("a", "b", "c", "d")
>>> dict.fromkeys(L)
{'a': None, 'b': None, 'c': None, 'd': None}dict的copy()方法會根據已有字典完全拷貝成一個新的字典副本。但需要注意的是,拷貝過程是淺拷貝。
>>> d = {'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> dd = d.copy()
>>> dd
{'three': 3, 'one': 1, 'two': 2, 'four': 4}
>>> id(d["one"]), id(dd["one"])
(10919424, 10919424)操作字典
官方手冊:https://docs.python.org/3/library/stdtypes.html#mapping-types-dict
dict的增刪改查
通過key即可檢索到元素。
>>> d
{'one': 1, 'two': 2, 'three': 3}
>>> d["one"]
1
>>> d["four"] = 4
>>> d
{'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> d["ten"]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'ten'對於dict型別,檢索不存在的key時會報錯。但如果自己去定義dict的子類,那麼可以自己重寫__missing__()方法來決定檢索的key不存在時的行為。例如,對於不存在的鍵總是返回None。
>>> d = {'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> class mydict(dict):
... def __missing__(self, key):
... return None
...
>>> dd = mydict(d)
>>> dd
{'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> dd["ten"]
>>> print(dd["ten"])
Noneget(key,default)方法檢索dict中的元素,如果元素存在,則返回對應的value,否則返回指定的default值,如果沒有指定default,且檢索的key又不存在,則返回None。這正好是上面自定義dict子類的功能。
>>> d = {'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> d.get("two")
2
>>> d.get("six","not exists")
'not exists'
>>> print(d.get("six"))
Nonelen()函式可以用來檢視字典有多少個元素:
>>> d
{'three': 3, 'four': 4, 'two': 2, 'one': 1}
>>> len(d)
4setdefault(key,default)方法檢索並設定一個key/value,如果key已存在,則直接返回對應的value,如果key不存在,則新插入這個key並指定其value為default並返回這個default,如果沒有指定default,key又不存在,則預設為None。
>>> d.setdefault("one")
1
>>> d.setdefault("five")
{'one': 1, 'two': 2, 'three': 3, 'four': 4, 'five': None}
>>> d.setdefault("six",6)
6
>>> d
{'one': 1, 'two': 2, 'three': 3, 'four': 4, 'five': None, 'six': 6}update(key/value)方法根據給定的key/value對更新已有的鍵,如果鍵不存在則新插入。key/value的表達方式有多種,只要能表達出key/value的配對行為就可以。比如已有的dict作為引數,key=value的方式,2元素的迭代容器物件。
>>> d
{'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> d.update(five=5, six=6) # key=value的方式
>>> d
{'one': 1, 'two': 2, 'three': 3, 'four': 4, 'five': 5, 'six': 6}
>>> d.update({"one":11, "two":22}) # dict作為引數
>>> d
{'one': 11, 'two': 22, 'three': 3, 'four': 4, 'five': 5, 'six': 6}
>>> d.update([("five",55),("six",66)]) # 列表中2元素的元組
>>> d
{'one': 11, 'two': 22, 'three': 3, 'four': 4, 'five': 55, 'six': 66}
>>> d.update((("five",55),("six",66))) # 這些都可以
>>> d.update((["five",55],["six",66]))
>>> d.update(zip(["five","six"],[55,66]))del D[KEY]可以用來根據key刪除字典D中給定的元素,如果元素不存在則報錯。
>>> d = {'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> del d["four"]
>>> d
{'three': 3, 'two': 2, 'one': 1}
>>> del d["five"]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'five'clear()方法用來刪除字典中所有元素。
>>> d = {'three': 3, 'four': 4, 'two': 2, 'one': 1}
>>> d.clear()
>>> d
{}pop(key,default)用來移除給定的元素並返回移除的元素。但如果元素不存在,則返回default,如果不存在且沒有給定default,則報錯。
>>> d = {'three': 3, 'four': 4, 'two': 2, 'one': 1}
>>> d.pop("one")
1
>>> d.pop("five","hello world")
'hello world'
>>> d.pop("five")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'five'popitem()用於移除並返回一個(key,value)元組對,每呼叫一次移除一個元素,沒元素可移除後將報錯。在python 3.7中保證以LIFO的順序移除,在此之前不保證移除順序。
例如,下面是在python 3.5中的操作時(不保證順序):
>>> d
{'three': 3, 'four': 4, 'two': 2, 'one': 1}
>>> d.popitem()
('three', 3)
>>> d.popitem()
('four', 4)
>>> d.popitem()
('two', 2)
>>> d.popitem()
('one', 1)
>>> d.popitem()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'popitem(): dictionary is empty'測試
通過d[key]的方式檢索字典中的某個元素時,如果該元素不存在將報錯。使用get()方法可以指定元素不存在時的預設返回值,而不報錯。而設定元素時,可用通過直接賦值的方式,也可以通過setdefault()方法來為不存在的值設定預設值。
重點在於元素是否存在於字典中。上面的幾種方法能在檢測元素是否存在時做出對應的操作,但字典作為容器,也可以直接用in和not in去測試元素的存在性。
>>> "one" in d
True
>>> "one3" in d
False
>>> "one3" not in d
True迭代和dict檢視
- keys()返回字典中所有的key組成的檢視物件;
- values()返回字典中所有value組成的檢視物件;
- items()返回字典中所有(key,value)元組對組成的檢視物件;
- iter(d)函式返回字典中所有key組成的可迭代物件。等價於
iter(d.keys())
前3個方法返回的是字典檢視物件,關於這個稍後再說。先看返回結果:
>>> d
{'three': 3, 'four': 4, 'two': 2, 'one': 1}
>>> d.keys()
dict_keys(['three', 'four', 'two', 'one'])
>>> list(d.keys())
['three', 'four', 'two', 'one']
>>> d.values()
dict_values([3, 4, 2, 1])
>>> d.items()
dict_items([('three', 3), ('four', 4), ('two', 2), ('one', 1)])iter(d)返回的是由key組成的可迭代物件。
>>> iter(d)
<dict_keyiterator object at 0x7f0ab9c9c4f8>
>>> for i in iter(d):print(i)
...
three
four
two
one既然這些都返回key、value、item組成的"列表"物件(檢視物件),那麼可以直接拿來迭代遍歷。
>>> for i in d.keys():
... print(i)
...
three
four
two
one
>>> for i in d.values():
... print(i)
...
3
4
2
1
>>> for (key,value) in d.items():
... print(key,"-->",value)
...
three --> 3
four --> 4
two --> 2
one --> 1dict檢視物件
keys()、values()、items()返回字典檢視物件。檢視物件中的資料會隨著原字典的改變而改變。如果知道關係型資料庫裡的檢視,這很容易理解。
>>> d
{'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> d.keys()
dict_keys(['one', 'two', 'three', 'four'])
>>> list(d.keys())
['one', 'two', 'three', 'four']字典檢視物件是可迭代物件,可以用來一個個地生成對應資料,但它畢竟不是列表。如果需要得到列表,只需使用list()方法構造即可。
>>> list(d.keys())
['one', 'two', 'three', 'four']因為字典試圖是可迭代物件,所以可以進行測試存在性、迭代、遍歷等。
KEY in d.keys()
for key in d.keys(): ...
for value in d.values(): ...
for (key, value) in d.items(): ...字典的檢視物件有兩個函式:
- len(obj_view):返回檢視物件的長度
- iter(obj_view):返回檢視物件對應的可迭代物件
>>> len(d.keys())
4
>>> iter(d.keys())
<dict_keyiterator object at 0x000001F0A7D9A9F8>注意,字典檢視物件是可迭代物件,但並不是實際的列表,所以不能使用sort方法來排序,但可以使用sorted()內建函式來排序(按照key進行排序)。
最後,檢視物件是隨原始字典動態改變的。修改原始字典,檢視也會改變。例如:
>>> d = {'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> ks = d.keys()
>>> del d["one"]
>>> k
dict_keys(['two', 'three', 'four'])字典迭代和解析
字典自身有迭代器,如果需要迭代key,則不需要使用keys()來間接迭代。所以下面是等價的:
for key in d:
for key in d.keys()關於字典解析,看幾個示例即可理解:
>>> d = {k:v for (k,v) in zip(["one","two","three"],[1,2,3])}
>>> d
{'one': 1, 'two': 2, 'three': 3}
>>> d = {x : x ** 2 for x in [1,2,3,4]}
>>> d
{1: 1, 2: 4, 3: 9, 4: 16}
>>> d = {x : None for x in "abcde"}
>>> d
{'a': None, 'b': None, 'c': None, 'd': None, 'e': None}