
語音識別中的資料增強技術
由於工作需要,調研了語音識別中的資料增強方法,順便對此進行總結。由於能力有限,難免有不對之處,請大家多多指正!
1. VTLP
VPLN用於語音識別,以消除由聲道長度差異引起的說話人與說話人之間的差異。通過求每個說話人特徵向量的均值和方差,並進行均值為0方差為1的規整化,能夠有效減小不同說話人特徵之間的差異。而VTLP反其道而行,通過對訓練集的輸入特徵加上差異性來進行資料增強。
1.1 Mel filter banks
人類聽覺感知實驗表明,人類聽覺的感知只聚焦在某些特定的區域,而不是整個頻譜包絡。實驗觀測發現,人耳就像一個濾波器組一樣,它只關心某些特定的頻率分量(人的聽覺對頻率是有選擇性的)。但是這些濾波器在頻率座標軸上卻不是統一分佈的,在低頻區有很多的濾波器,他們分佈比較密集,而在高頻區,濾波器數量減少,分佈很稀疏,如下圖所示:
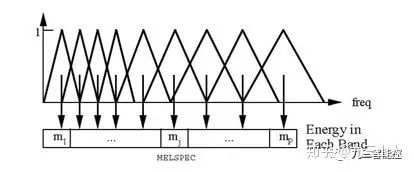
Mel濾波器組是根據人耳聽覺特性設計的三角形濾波器組,它可以將線性頻譜對映到基於聽覺感知的Mel非線性頻譜中,其具體的轉換公式定義如下:

在Mel頻域內,人對音調對感知度為線性關係,可表示為下圖:
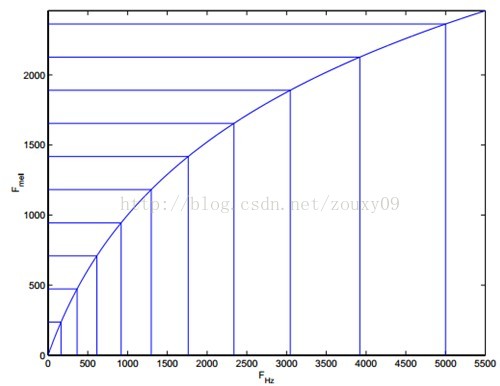
一般地,Mel濾波器的範圍在0~8kHz之間,並且每一個濾波器都開始於前一個濾波器的中心頻率,結束於下一個濾波器的中心頻率,如下圖所示:

1.2 VTLP
VTLP (vocal tract length perturbation) 通過為每句話隨機生成一個摺疊因子在頻率軸進行對映,將原始頻率f
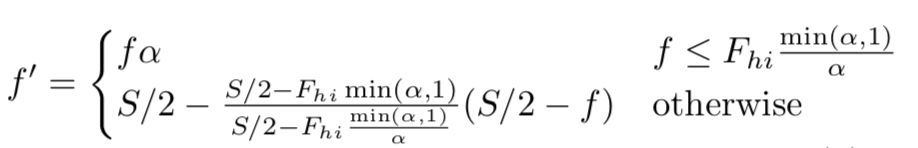
其中
![]() 為覆蓋有效共振峰的邊界資訊。一般地,在VTLN中摺疊因子
為覆蓋有效共振峰的邊界資訊。一般地,在VTLN中摺疊因子
1.3 注意事項
- 在訓練時,對於每一個epoch,我們對每一個語句生成一個隨機的摺疊因子
,然後生成40維的Mel濾波器特徵;
- 摺疊因子
- 論文中,為了方便,對同一語句的所有幀都採用同一個摺疊因子。此外,還計算了語譜圖的一階和二階差分,並且為了更好地對狀態標籤進行對齊,考慮上下文資訊,採用當前幀及其前後各7幀總共15幀作為資料向量。
- 對於解碼階段,也對測試語句進行擾動,V個不同都向量輸入到神經網路得到不同HMM狀態到概率,對這些概率論文采用對後驗概率求平均(Avg)、最大值(Max)和幾何平均(Prod)三種方法。
參考資料
- https://blog.csdn.net/zouxy09/article/details/9156785
-
Vocal Tract Length Perturbation (VTLP) improves speech recognition