
Tomcat效能調優
一.一切基於JVM(記憶體)的優化
1. 32位作業系統與64位作業系統中JVM的對比

我們一般的開發人員,基本用的是都是32位的Windows系統,這就導致了一個嚴重的問題即:32位windows系統對記憶體限制
上述問題解決後,我們又碰到一個新的問題,32位系統下JVM對記憶體的限制:不能突破2GB記憶體,即使你在Win2003 Advanced Server下你的機器裝有8GB-16GB的記憶體,而你的JAVA,只能用到2GB的記憶體。
其實我一直很想推薦大家使用Linux或者是Mac作業系統的,而且要裝64位,因為必竟我們是開發用的不是打遊戲用的,而Java源自Unix歸於Unix(Linux只是執行在PC上的Unix而己)。
所以很多開發人員執行在win32位系統上更有甚者在生產環境下都會佈署win32位的系統,那麼這時你的Tomcat要優化,就要講究點技巧了。而在64位作業系統上無論是系統記憶體還是JVM都沒有受到2GB這樣的限制。
Tomcat的優化分成兩塊:
ü Tomcat啟動命令列中的優化引數即JVM優化
ü Tomcat容器自身引數的優化(這塊很像ApacheHttp Server)
這一節
先要講的是Tomcat啟動命令列中的優化引數。
Tomcat首先跑在JVM之上的,因為它的啟動其實也只是一個java命令列,首先我們需要對這個JAVA的啟動命令列進行調優。
需要注意的是:
這邊討論的JVM優化是基於Oracle Sun的jdk1.6版有以上,其它JDK或者低版本JDK不適用。
2. Tomcat啟動行引數的優化
Tomcat 的啟動引數位於tomcat的安裝目錄\bin目錄下,如果你是Linux作業系統就是catalina.sh檔案,如果你是Windows作業系統那麼 你需要改動的就是catalina.bat檔案。開啟該檔案,一般該檔案頭部是一堆的由##包裹著的註釋文字,找到註釋文字的最後一段如:
敲入一個回車,加入如下的引數
Linux系統中tomcat的啟動引數
export JAVA_OPTS="-server -Xms1400M -Xmx1400M -Xss512k -XX:+AggressiveOpts -XX:+UseBiasedLocking -XX:PermSize=128M -XX:MaxPermSize=256M -XX:+DisableExplicitGC -XX:MaxTenuringThreshold=31 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -Djava.awt.headless=true "
Windows系統中tomcat的啟動引數
set JAVA_OPTS=-server -Xms1400M -Xmx1400M -Xss512k -XX:+AggressiveOpts -XX:+UseBiasedLocking -XX:PermSize=128M -XX:MaxPermSize=256M -XX:+DisableExplicitGC -XX:MaxTenuringThreshold=31 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection
-XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -Djava.awt.headless=true
上面引數好多啊,可能有人寫到現在都沒見一個tomcat的啟動命令里加了這麼多引數,當然,這些引數只是我機器上的,不一定適合你,尤其是引數後的value(值)是需要根據你自己的實際情況來設定的。
引數解釋:
ü -server
我不管你什麼理由,只要你的tomcat是執行在生產環境中的,這個引數必須給我加上
因 為tomcat預設是以一種叫java –client的模式來執行的,server即意味著你的tomcat是以真實的production的模式在執行的,這也就意味著你的tomcat以 server模式執行時將擁有:更大、更高的併發處理能力,更快更強捷的JVM垃圾回收機制,可以獲得更多的負載與吞吐量。。。更。。。還有更。。。
Y給我記住啊,要不然這個-server都不加,那是要打屁股了。
ü -Xms–Xmx
即JVM記憶體設定了,把Xms與Xmx兩個值設成一樣是最優的做法,有人說Xms為最小值,Xmx為最大值不是挺好的,這樣設定還比較人性化,科學化。人性?科學?你個頭啊。
大家想一下這樣的場景:
一 個系統隨著併發數越來越高,它的記憶體使用情況逐步上升,上升到最高點不能上升了,開始回落,你們不要認為這個回落就是好事情,由其是大起大落,在記憶體回落 時它付出的代價是CPU高速開始運轉進行垃圾回收,此時嚴重的甚至會造成你的系統出現“卡殼”就是你在好好的操作,突然網頁像死在那邊一樣幾秒甚至十幾秒 時間,因為JVM正在進行垃圾回收。
因此一開始我們就把這兩個設成一樣,使得Tomcat在啟動時就為最大化引數充分利用系統的效率,這個道理和jdbcconnection pool裡的minpool size與maxpool size的需要設成一個數量是一樣的原理。
如何知道我的JVM能夠使用最大值啊?拍腦袋?不行!
在設這個最大記憶體即Xmx值時請先開啟一個命令列,鍵入如下的命令:’

看,能夠正常顯示JDK的版本資訊,說明,這個值你能夠用。不是說32位系統下最高能夠使用2GB記憶體嗎?即:2048m,我們不防來試試
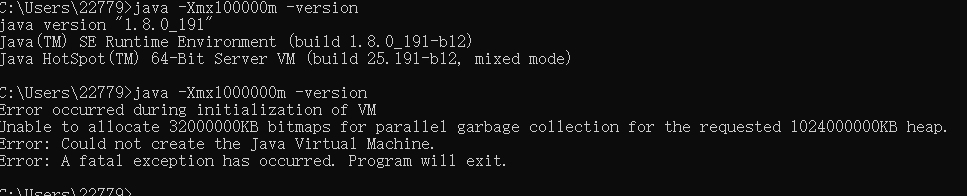
因此在設這個-Xms與-Xmx值時一定一定記得先這樣測試一下,要不然直接加在tomcat啟動命令列中你的tomcat就再也起不來了,要飛是飛不了,直接成了一隻瘟貓了。
ü –Xmn
設定年輕代大小為512m。整個堆大小=年輕代大小 + 年老代大小 + 持久代大小。持久代一般固定大小為64m,所以增大年輕代後,將會減小年老代大小。此值對系統性能影響較大,Sun官方推薦配置為整個堆的3/8。
ü -Xss
是指設定每個執行緒的堆疊大小。這個就要依據你的程式,看一個執行緒 大約需要佔用多少記憶體,可能會有多少執行緒同時執行等。一般不易設定超過1M,要不然容易出現out ofmemory。
ü -XX:+AggressiveOpts
作用如其名(aggressive),啟用這個引數,則每當JDK版本升級時,你的JVM都會使用最新加入的優化技術(如果有的話)
ü -XX:+UseBiasedLocking
啟用一個優化了的執行緒鎖,我們知道在我們的appserver,每個http請求就是一個執行緒,有的請求短有的請求長,就會有請求排隊的現象,甚至還會出現執行緒阻塞,這個優化了的執行緒鎖使得你的appserver內對執行緒處理自動進行最優調配。
ü -XX:PermSize=128M-XX:MaxPermSize=256M
JVM使用-XX:PermSize設定非堆記憶體初始值,預設是實體記憶體的1/64;
在資料量的很大的檔案匯出時,一定要把這兩個值設定上,否則會出現記憶體溢位的錯誤。
由XX:MaxPermSize設定最大非堆記憶體的大小,預設是實體記憶體的1/4。
那麼,如果是實體記憶體4GB,那麼64分之一就是64MB,這就是PermSize預設值,也就是永生代記憶體初始大小;
四分之一是1024MB,這就是MaxPermSize預設大小。
ü -XX:+DisableExplicitGC
在 程式程式碼中不允許有顯示的呼叫”System.gc()”。看到過有兩個極品工程中每次在DAO操作結束時手動呼叫System.gc()一下,覺得這樣 做好像能夠解決它們的out ofmemory問題一樣,付出的代價就是系統響應時間嚴重降低,就和我在關於Xms,Xmx裡的解釋的原理一樣,這樣去呼叫GC導致系統的JVM大起大 落,效能不到什麼地方去喲!
ü -XX:+UseParNewGC
對年輕代採用多執行緒並行回收,這樣收得快。
ü -XX:+UseConcMarkSweepGC
即CMS gc,這一特性只有jdk1.5即後續版本才具有的功能,它使用的是gc估算觸發和heap佔用觸發。
我們知道頻頻繁的GC會造面JVM的大起大落從而影響到系統的效率,因此使用了CMS GC後可以在GC次數增多的情況下,每次GC的響應時間卻很短,比如說使用了CMS GC後經過jprofiler的觀察,GC被觸發次數非常多,而每次GC耗時僅為幾毫秒。
ü -XX:MaxTenuringThreshold
設 置垃圾最大年齡。如果設定為0的話,則年輕代物件不經過Survivor區,直接進入年老代。對於年老代比較多的應用,可以提高效率。如果將此值設定為一 個較大值,則年輕代物件會在Survivor區進行多次複製,這樣可以增加物件再年輕代的存活時間,增加在年輕代即被回收的概率。
這個值的設定是根據本地的jprofiler監控後得到的一個理想的值,不能一概而論原搬照抄。
ü -XX:+CMSParallelRemarkEnabled
在使用UseParNewGC 的情況下, 儘量減少 mark 的時間
ü -XX:+UseCMSCompactAtFullCollection
在使用concurrent gc 的情況下, 防止 memoryfragmention, 對live object 進行整理, 使 memory 碎片減少。
ü -XX:LargePageSizeInBytes
指定 Java heap的分頁頁面大小
ü -XX:+UseFastAccessorMethods
get,set 方法轉成原生代碼
ü -XX:+UseCMSInitiatingOccupancyOnly
指示只有在 oldgeneration 在使用了初始化的比例後concurrent collector 啟動收集
ü -XX:CMSInitiatingOccupancyFraction=70
CMSInitiatingOccupancyFraction,這個引數設定有很大技巧,基本上滿足(Xmx-Xmn)(100- CMSInitiatingOccupancyFraction)/100>=Xmn就 不會出現promotion failed。在我的應用中Xmx是6000,Xmn是512,那麼Xmx-Xmn是5488兆,也就是年老代有5488
兆,CMSInitiatingOccupancyFraction=90說明年老代到90%滿的時候開始執行對年老代的併發垃圾回收(CMS),這時還 剩10%的空間是548810%=548兆,所以即使Xmn(也就是年輕代共512兆)裡所有物件都搬到年老代裡,548兆的空間也足夠了,所以只要滿 足上面的公式,就不會出現垃圾回收時的promotion failed;
因此這個引數的設定必須與Xmn關聯在一起。
ü -Djava.awt.headless=true
這 個引數一般我們都是放在最後使用的,這全引數的作用是這樣的,有時我們會在我們的J2EE工程中使用一些圖表工具如:jfreechart,用於在web 網頁輸出GIF/JPG等流,在winodws環境下,一般我們的app server在輸出圖形時不會碰到什麼問題,但是在linux/unix環境下經常會碰到一個exception導致你在winodws開發環境下圖片顯 示的好好可是在linux/unix下卻顯示不出來,因此加上這個引數以免避這樣的情況出現。
上述這樣的配置,基本上可以達到:
ü 系統響應時間增快
ü JVM回收速度增快同時又不影響系統的響應率
ü JVM記憶體最大化利用
ü 執行緒阻塞情況最小化
3.Tomcat容器內的優化
前面我們對Tomcat啟動時的命令進行了優化,增加了系統的JVM可使用數、垃圾回收效率與執行緒阻塞情況、增加了系統響應效率等還有一個很重要的指標,我們沒有去做優化,就是吞吐量。
還記得學習中說的,這個系統本身可以處理1000,你沒有優化和配置導致它預設只能處理25。因此下面我們來看Tomcat容器內的優化。
開啟tomcat安裝目錄\conf\server.xml檔案,定位到這一行:
<connector port="8080" protocol="HTTP/1.1" <="" p="" style="word-wrap: break-word;">
這一行就是我們的tomcat容器效能引數設定的地方,它一般都會有一個預設值,這些預設值是遠遠不夠我們的使用的,我們來看經過更改後的這一段的配置:
<connector port="8080" protocol="HTTP/1.1" <="" p="" style="word-wrap: break-word;">
URIEncoding="UTF-8"
minSpareThreads="25"
maxSpareThreads="75"
enableLookups="false"
disableUploadTimeout="true"
connectionTimeout="20000"
acceptCount="300"
maxThreads="300"
maxProcessors="1000"
minProcessors="5"
useURIValidationHack="false"
compression="on"
compressionMinSize="2048"
compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain"
redirectPort="8443"
/>
ü URIEncoding=”UTF-8”
使得tomcat可以解析含有中文名的檔案的url,真方便,不像apache裡還有搞個mod_encoding,還要手工編譯
ü maxSpareThreads
maxSpareThreads 的意思就是如果空閒狀態的執行緒數多於設定的數目,則將這些執行緒中止,減少這個池中的執行緒總數。
ü minSpareThreads
最小備用執行緒數,tomcat啟動時的初始化的執行緒數。
ü enableLookups
這個功效和Apache中的HostnameLookups一樣,設為關閉。
ü connectionTimeout
connectionTimeout為網路連線超時時間毫秒數。
ü maxThreads
maxThreads Tomcat使用執行緒來處理接收的每個請求。這個值表示Tomcat可建立的最大的執行緒數,即最大併發數。
ü acceptCount
acceptCount是當執行緒數達到maxThreads後,後續請求會被放入一個等待佇列,這個acceptCount是這個佇列的大小,如果這個佇列也滿了,就直接refuse connection
ü maxProcessors與minProcessors
在 Java中執行緒是程式執行時的路徑,是在一個程式中與其它控制執行緒無關的、能夠獨立執行的程式碼段。它們共享相同的地址空間。多執行緒幫助程式設計師寫出CPU最 大利用率的高效程式,使空閒時間保持最低,從而接受更多的請求。
通常Windows是1000個左右,Linux是2000個左右。
ü useURIValidationHack
我們來看一下tomcat中的一段原始碼:
security
if (connector.getUseURIValidationHack()) {
String uri = validate(request.getRequestURI());
if (uri == null) {
res.setStatus(400);
res.setMessage("Invalid URI");
throw new IOException("Invalid URI");
} else {
req.requestURI().setString(uri);
// Redoing the URI decoding
req.decodedURI().duplicate(req.requestURI());
req.getURLDecoder().convert(req.decodedURI(), true);
}
}
可以看到如果把useURIValidationHack設成"false",可以減少它對一些url的不必要的檢查從而減省開銷。
ü enableLookups=“false”
為了消除DNS查詢對效能的影響我們可以關閉DNS查詢,方式是修改server.xml檔案中的enableLookups引數值。
ü disableUploadTimeout
類似於Apache中的keeyalive一樣
ü 給Tomcat配置gzip壓縮(HTTP壓縮)功能
compression=“on” compressionMinSize=“2048”
compressableMimeType=“text/html,text/xml,text/javascript,text/css,text/plain”```
HTTP 壓縮可以大大提高瀏覽網站的速度,它的原理是,在客戶端請求網頁後,從伺服器端將網頁檔案壓縮,再下載到客戶端,由客戶端的瀏覽器負責解壓縮並瀏覽。相對 於普通的瀏覽過程HTML,CSS,Javascript , Text ,它可以節省40%左右的流量。更為重要的是,它可以對動態生成的,包括CGI、PHP , JSP , ASP , Servlet,SHTML等輸出的網頁也能進行壓縮,壓縮效率驚人。
1)compression="on" 開啟壓縮功能
2)compressionMinSize="2048" 啟用壓縮的輸出內容大小,這裡面預設為2KB
3)noCompressionUserAgents="gozilla, traviata" 對於以下的瀏覽器,不啟用壓縮
4)compressableMimeType="text/html,text/xml" 壓縮型別
最後不要忘了把8443埠的地方也加上同樣的配置,因為如果我們走https協議的話,我們將會用到8443埠這個段的配置,對吧?
<connector port=“8443” protocol=“HTTP/1.1” <="" p="" style=“word-wrap: break-word;”>
URIEncoding=“UTF-8” minSpareThreads=“25” maxSpareThreads=“75”
enableLookups=“false” disableUploadTimeout=“true” connectionTimeout=“20000”
acceptCount=“300” maxThreads=“300” maxProcessors=“1000” minProcessors=“5”
useURIValidationHack=“false”
compression=“on” compressionMinSize=“2048”
compressableMimeType=“text/html,text/xml,text/javascript,text/css,text/plain”
SSLEnabled=“true”
scheme=“https” secure=“true”
clientAuth=“false” sslProtocol=“TLS”
keystoreFile=“d:/tomcat2/conf/shnlap93.jks” keystorePass=“aaaaaa”
/>
好了,所有的Tomcat優化的地方都加上了。結合Apache的效能優化,我們這個架構可以“飛奔”起來了,當然這邊把有提及任何關於資料庫優化的步驟,但僅憑這兩步,我們的系統已經有了很大的提升。
舉個真實的例子:經過4輪優化,第一輪進行了問題的定位,第二輪就是進行了apache+tomcat/weblogic的優化,第三輪是做叢集優化,第四輪是sql與codes的優化。
在到達第二輪時,我們的效能已經提升了多少倍呢?我們來看一個loaderrunner的截圖吧:

左邊第一列是第一輪沒有經過任何調優的壓力測試報告。
右邊這一列是經過了apache優化,tomcat優化後得到的壓力測試報告。
大家看看,這就提高了多少倍?這還只是在沒有改動程式碼的情況下得到的改善,現在明白了好好的調優一
個apache和tomcat其實是多麼的重要了?如果加上後面的程式碼、SQL的調優、資料庫的調優。。。。。。所以我在上一個工程中有單筆交易效能(無論是吞吐量、響應時間)提高了80倍這樣的極端例子的存在。