
hadoop隨手筆記

圖2.1 HDFS檔案系統的架構圖
(1)hadoop的資訊的傳遞主要依靠心跳機制:依靠傳遞packet來想Datanode寫入資料,一個packet由多個數據chunk組成,每個chunk對應這一個校驗和,當chunk的數目足夠多的時候,packet會被寫入Dataqueue。其中packet包含兩種:心跳packet(裡面不含有任何chunk,4個位元組儲存packet的長度,8個位元組儲存呢packet在block中的偏移量,8個位元組儲存呢在Block中的序列號,1個位元組用於標識該packet是否是block中的最後一個packet)與資料packet。
(2)在傳送packet之前,DataStreamer類首先會從Namenode中獲得blockid與block的位置資訊,然後會迴圈的從Dataqueue中取得第一個packet,然後將該packet寫入與Datanode所建立的socket 中。當屬於一個block的所有packet都發送給Datanode,並且返回了與每個packet所對應的相應資訊之後,DataStream會關閉當前的資料block。
(3)在寫入資料的時候DataNode節點會在Out/InStream就是資料包傳輸的管道線性排列,然後會依次按照將資料寫入DataNode,然後會按照原路依次向上返回響應的資訊,最終返回給客戶端,使用responseprocessor用來處理客戶端向DataNode傳送資料後響應,因為每一個數據包(packet)在DataNode接受之後會有一個反饋,該執行緒會在客戶端執行並且處理的packet的資訊也不是最後一個是時候,會迴圈處理來自DataNode中的響應,如果返回的是失敗的響應會記錄下索引並丟擲異常;在客戶端會建立兩個佇列如Dataqueue與ackqueue佇列,其中前一個用來儲存將要傳送的資料包,而後一個是用來儲存已經發送,但是沒有收到確認資訊的資料包。
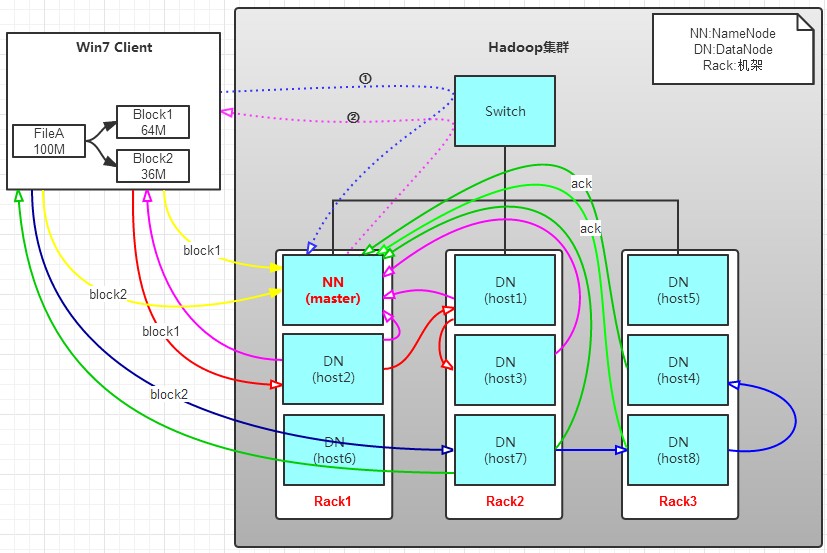
有一個檔案FileA,100M大小。Client將FileA寫入到HDFS上。
HDFS按預設配置。
HDFS分佈在三個機架上Rack1,Rack2,Rack3。
a. Client將FileA按64M分塊。分成兩塊,block1和Block2;
b. Client向nameNode傳送寫資料請求,如圖藍色虛線①------>。
c. NameNode節點,記錄block資訊。並返回可用的DataNode,如粉色虛線②--------->。
Block1: host2,host1,host3
Block2: host7,host8,host4
原理:
NameNode具有RackAware機架感知功能,這個可以配置。
若client為DataNode節點,那儲存block時,規則為:副本1,同client的節點上;副本2,不同機架節點上;副本3,同第二個副本機架的另一個節點上;其他副本隨機挑選。
若client不為DataNode節點,那儲存block時,規則為:副本1,隨機選擇一個節點上;副本2,不同副本1,機架上;副本3,同副本2相同的另一個節點上;其他副本隨機挑選。
d. client向DataNode傳送block1;傳送過程是以流式寫入。
流式寫入過程,
1>將64M的block1按64k的package劃分;
2>然後將第一個package傳送給host2;
3>host2接收完後,將第一個package傳送給host1,同時client想host2傳送第二個package;
4>host1接收完第一個package後,傳送給host3,同時接收host2發來的第二個package。
5>以此類推,如圖紅線實線所示,直到將block1傳送完畢。
6>host2,host1,host3向NameNode,host2向Client傳送通知,說“訊息傳送完了”。如圖粉紅顏色實線所示。
7>client收到host2發來的訊息後,向namenode傳送訊息,說我寫完了。這樣就真完成了。如圖黃色粗實線
8>傳送完block1後,再向host7,host8,host4傳送block2,如圖藍色實線所示。
9>傳送完block2後,host7,host8,host4向NameNode,host7向Client傳送通知,如圖淺綠色實線所示。
10>client向NameNode傳送訊息,說我寫完了,如圖黃色粗實線。。。這樣就完畢了。
分析,通過寫過程,我們可以瞭解到:
①寫1T檔案,我們需要3T的儲存,3T的網路流量貸款。
②在執行讀或寫的過程中,NameNode和DataNode通過HeartBeat進行儲存通訊,確定DataNode活著。如果發現DataNode死掉了,就將死掉的DataNode上的資料,放到其他節點去。讀取時,要讀其他節點去。
③掛掉一個節點,沒關係,還有其他節點可以備份;甚至,掛掉某一個機架,也沒關係;其他機架上,也有備份。
(4)分散式系統中解決互斥鎖的問題,1.每次執行寫入的時候,客戶端都需要向NameNode申請互斥鎖,從而導致了網路的開銷增大;2.當某個客戶端獲得互斥鎖之後和NameNode失去聯絡的時候,會造成互斥鎖無法釋放的問題。因此可以使用lease租約來解決互斥鎖的問題。當獲取到互斥鎖的時候,會在租約這一段時間內,無需再申請互斥鎖,在客戶端一直工作的過程中,如果租約期滿了之後,客戶端會再次續約。這樣即使客戶端因為異常斷開的時候,也不會一直佔用互斥鎖,並且HDFS會在客戶端每次寫入資料的時候回增加版本資訊,異常客戶端寫入的資料版本號會很低,從而可以被安全的刪除。
(5)NameNode是hadoop的首席、captain,它包含了hadoop中資料檔案儲存的索引,包括檔案儲存各種資訊,負責管理HDFS檔案系統,具體包括namespace名稱空間的管理即檔案系統的目錄結構,資料block的管理(filename-->>block list,block--》》DataNode list)。其始終作為被動提供服務的Server,不會主動的向客戶端DFSClient或者DataNode傳送請求,所有的請求都是客戶端或者DataNode發起的。
(6)inode同linux 中的inode,也是硬碟中開闢的一塊空間,裡面主要儲存檔案的資訊,如建立日期,檔案大小,擁有者,擁有組,(在給硬碟格式化的時候,被分為資料區(block)與資訊區(inode))。在hadoop中也是inode用來儲存檔案資訊,定義了各種許可權、建立時間、檔案的位置,inode是hadoop中檔案儲存的最基本的類,其子類有indeDirectory與inodeFile分別代表系統中的目錄與檔案。namespace是函式的名稱空間,因為不同的程式設計師會規定相同的函式名,此時為了區分,需要將在前面加上標誌用來區分檔案。
(7)FSDirectory主要用來儲存整個HDFS檔案系統目錄的狀態,管理向磁碟寫入的手或者從磁碟載入的資料,並且會將目錄中的資料所發生的改變記錄到日誌當中,儲存了一個最新的file--》Block list的對映表,並且將該對映表寫入到磁碟中,當系統載入FSImage的時候,FSImage會在FSDirectory物件上重建檔案目錄的狀態(因此這兩類的內容是大致是一樣的,用來儲存資訊)。FSEditLog類主要用於namnode對HDFS的namespace的修改操作進行日誌記錄。在namenode中,namespace(檔案系統中的目錄樹/檔案等元資料資訊,但是不包括block資訊)是被全部快取在記憶體中的,所以一旦namenode重啟或者宕機,這些元資料資訊會丟失。因此在namenode重啟的時候必須要將整個namespace進行重建,namemode的當前實現的是將namesapce資訊記錄到一個Fsimage繼承自Storage的二進位制檔案中,當namenode重啟的時候根據讀取這個fsimage檔案中的資訊來重建namespace目錄樹結構,但是fsimage是儲存在硬碟上的檔案,不可能時時刻刻與namenode記憶體中的資料結構保持同步,而是通過每隔一段時間來更新一次fsimage檔案,來保證fsimage與namenode記憶體中的namesapce的儘量同步,而在一個新的fsimage與上一個fsimage之間的namenode的操作,都會被記錄到editlog檔案中,因此每隔namenode都會對應著一個fsimage檔案和editlog檔案。FSEditlog類就是用來管理這個editlog檔案的。
(8)host2NodesMap儲存了從主機到主機上的所有的DataNode的DatanodeDescriptor的對映,主要負責對叢集中的DataNode按照它們所在的主機進行分類管理。一個主機上可以同時開啟多個DataNode執行緒,也就是多個DataNode節點,HDFS是以主機為基本單位來計算叢集的負載情況的。當一個DataNode節點向NameNode註冊成功之後,NameNode會將這個DataNode新增到它的FSNamesystem變數的Host2NodesMap成員變數中。
(9)NetworkTopology類代表一個具有樹狀網路拓撲結構的計算機叢集。例如,在一個叢集中可能有多個數據中心,在每個計算中心都分佈著很多為計算需求而設定的計算機的機架,在網路拓撲結構中,每個葉子節點代表一個DataNode,而不同的機架之間的路由選擇由InnerNode內部類來表示。而且,當NameNode將一個DataNode交給NetworkTopology類儲存之前,它已經將DataNode所在的主機的IP地址解析成了/*/*/*/*格式。
(10)機架:由於現實場景中機架槽位與網口的限制,會使一個機架上的只能放置有限的伺服器,在每個機架之間的伺服器傳輸速度會遠遠大於機架之間的伺服器的傳輸速度,機架之間的機器網路傳輸速度回受到上層交換機的網路速度的限制。

這裡面rack即代表機架,DataNode即代表每臺伺服器,第一層與第二層是路由器。
第一個block副本放在和client所在的node裡(如果client不在叢集範圍內,則這第一個node是隨機選取的)。
第二個副本放置在與第一個節點不同的機架中的node中(隨機選擇)。
第三個副本似乎放置在與第一個副本所在節點同一機架的另一個節點上。
但是hadoop是不能直接對機架做出感應的,所以這時候需要對檔案系統進行配置,使得hadoop能夠感知出機架。
(精華:DataNode與伺服器硬體之間產生聯絡,命名方式:hostname:port,而且該DataNode在資料中心dog裡的orange機架上,那麼這個DataNode在網路拓撲結構中的位置為“/dog/orange”)。一個Node實力可能表示的是一個DataNode,也可能是叢集中的機架或者路由器,而一個InnerNode例項表示的是一個機架或者路由器。每個Node在網路拓撲中有一個名稱與對應的位置,而Node的位置資訊使用類似檔案路徑的方式來定義。
(11)HostFileReader用於個弄哪些DataNode允許連線到NameNode,哪些允許連線到NameNode。
(12)BlocksMap維護從資料塊到其元資料的對映,其中資料塊的元資料資訊包括資料所屬的Inode、儲存資料塊的DataNode等。FSimage沒有記錄下每一個數據Block對應的哪幾個DataNode的對應表的資訊,只是儲存了與namespace相關的資訊,在所有的DataNode啟動的時候,每個DataNode對本地磁碟進行掃描,將block對應到DataNode列表的資訊彙報給NameNode,NameNode在接收到每個DataNode的塊資訊的時候,將這些資訊都儲存在記憶體中,NameNode是利用BlocksMap資料結構儲存從Block到DataNode列表資訊的對映關係的。(inode包含在元資料中,linux中的inode與hadoop中的inode儲存的資料元素不一樣)
(13)FSNamesystem HDFS檔案系統的名稱空間:主要管理的資料結構表:1.檔名到資料塊列表的對映,這些資訊會被持久化到FSimage和日誌中。2.所有有效的資料塊列表。3.資料塊到DataNode的對映,這些資訊只會被儲存在記憶體中,並不會持久化。4.從DataNode到資料塊的對映。5.最近傳送過的心跳資訊的DataNode列表。
(14)NameNode控制著兩個重要的表:1.filename->blocksequence(namesapce)(一個檔案所對的block序列),存放在硬碟當中。2.block->machinelist("inodes")(一個Block所在的machine列表),在每次NameNode啟動的時候會被重新建立。
(15)DataNodeID用於唯一的標識一個DataNode,其中使用主機名:埠號的格式標識DataNode的ID名稱,同時包含儲存介質ID,伺服器執行時所用的埠號,NameNode與DataNode進行連線時或者是DataNode之間通訊的時候會使用這個埠號。
(16)ClientDatanodeProtocol是用於和Client互動的,InterDatanodeProtocol是Datanode之間的通訊介面。
(17)Magic number一般是指硬寫到程式碼裡的整數常量,數值是程式設計者自己指定的,其他人不知道數值有什麼具體意義,ELF檔案頭會寫入一個magic number,檢查這個數和自己預想的是否一致可以判斷檔案是否損壞。在緩衝區陣列旁放一個magic number(稱作canary金絲雀),通過檢查是否一致可檢測緩衝區溢位攻擊。