
訊息佇列中的7個連環炮
訊息佇列7連擊
(1)第一問,你知道不知道你們系統裡為什麼要用訊息佇列這個東西?
答:
①首先是解耦作用
我們先看如果沒有用mq會是什麼情況呢?

接下來,我們需要用mq來改進上面的問題
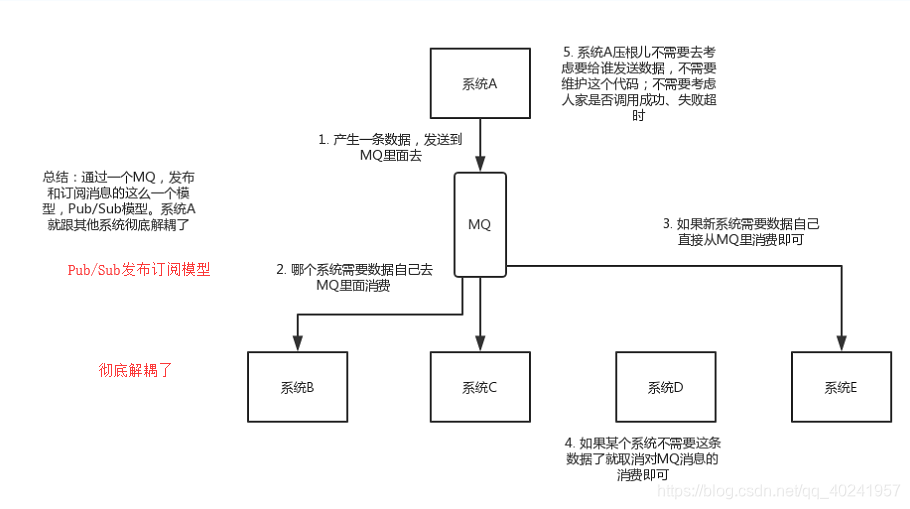
②然後mq還有非同步化的作用(減少各系統之間呼叫的時間消耗)
下面先來看一下如果沒有mq會是什麼情況?
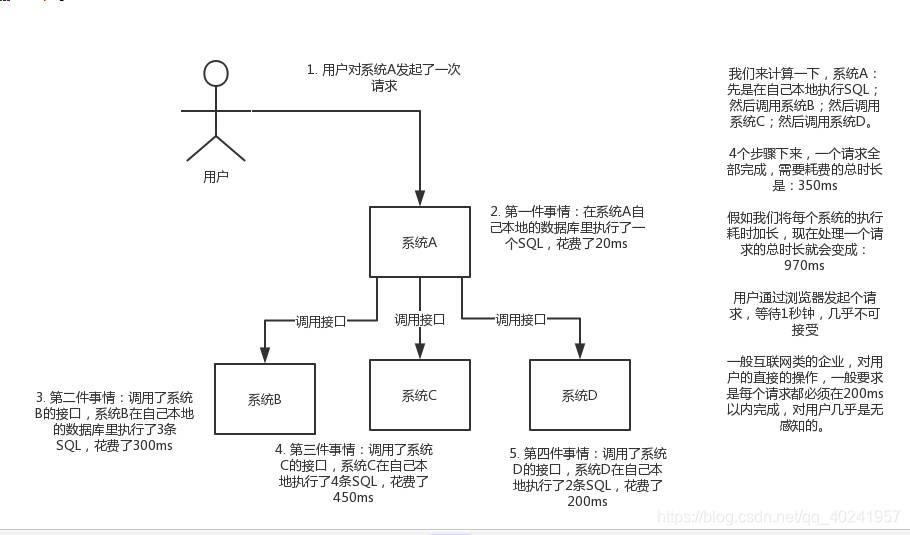
很明顯A系統序列呼叫其他各個系統來執行sql語句,很費時間,這樣的話,使用者體驗就不好
用mq來解決這個問題吧

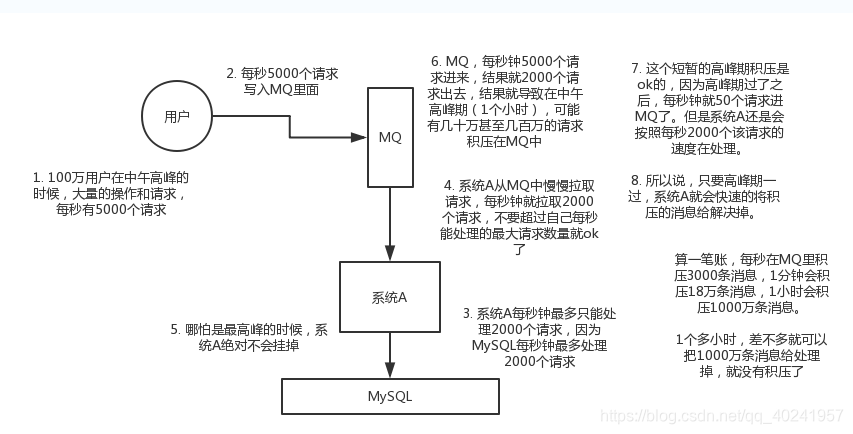
③mq還可以削峰
如果我們不用mq的話見下圖

這樣的話,mysql伺服器很容易癱瘓宕機,
所以我們如果用mq的話,見下圖
以上三點說的都是mq的優點,那麼有優點肯定就有缺點啊,
缺點:第一點,萬一mq宕機怎麼辦
第二點,就是資料一致性問題可能會出現
一致性問題:A系統處理完了直接返回成功了,人人都以為你這個請求就成功了;但是問題是,要是BCD三個系統那裡,BD兩個系統寫庫成功了,結果C系統寫庫失敗了,咋整?你這資料就不一致了。見下圖

(2)第二問,kafka、activemq、rabbitmq、rocketmq都有什麼優點和缺點啊?
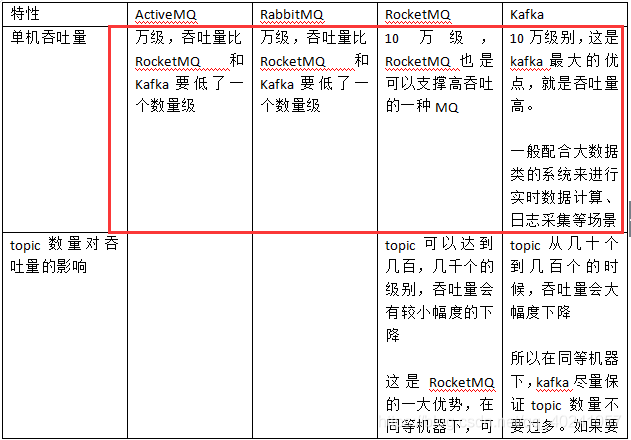
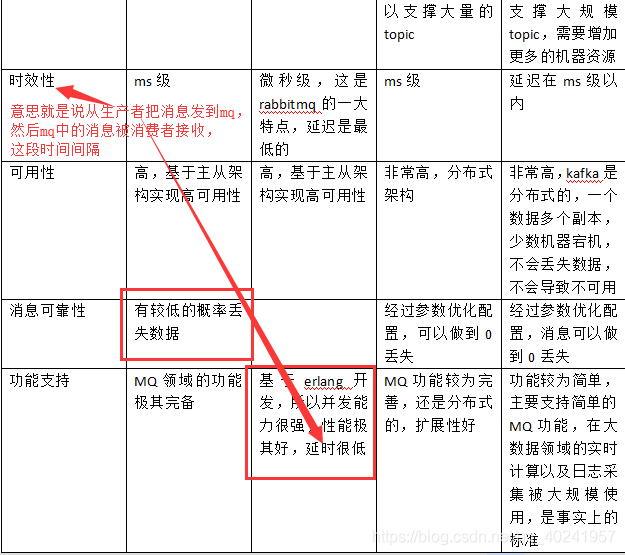



對四種mq的總結如下:
綜上所述,各種對比之後,我個人傾向於是:
一般的業務系統要引入MQ,最早大家都用ActiveMQ,但是現在確實大家用的不多了,沒經過大規模吞吐量場景的驗證,社群也不是很活躍,所以大家還是算了吧,我個人不推薦用這個了;
後來大家開始用RabbitMQ,但是確實erlang語言阻止了大量的java工程師去深入研究和掌控他,對公司而言,幾乎處於不可控的狀態,但是確實人是開源的,比較穩定的支援,活躍度也高;
不過現在確實越來越多的公司,會去用RocketMQ,確實很不錯,但是我提醒一下自己想好社群萬一突然黃掉的風險,對自己公司技術實力有絕對自信的,我推薦用RocketMQ,否則回去老老實實用RabbitMQ吧,人是活躍開源社群,絕對不會黃
所以中小型公司,技術實力較為一般,技術挑戰不是特別高,用RabbitMQ是不錯的選擇;大型公司,基礎架構研發實力較強,用RocketMQ是很好的選擇
如果是大資料領域的實時計算、日誌採集等場景,用Kafka是業內標準的,絕對沒問題,社群活躍度很高,絕對不會黃,何況幾乎是全世界這個領域的事實性規範
(3).第三問,如何保證訊息佇列的高可用啊?
(1)RabbitMQ的高可用性
RabbitMQ是比較有代表性的,因為是基於主從做高可用性的,我們就以它為例子講解第一種MQ的高可用性怎麼實現。
rabbitmq有三種模式:單機模式,普通叢集模式,映象叢集模式
單機模式:就是demo級別的,一般就是你本地啟動了玩玩兒的,沒人生產用單機模式
普通叢集模式:意思就是在多臺機器上啟動多個rabbitmq例項,每個機器啟動一個。但是你建立的queue,只會放在一個rabbtimq例項上,但是每個例項都同步queue的元資料。完了你消費的時候,實際上如果連線到了另外一個例項,那麼那個例項會從queue所在例項上拉取資料過來。
這種方式確實很麻煩,也不怎麼好,沒做到所謂的分散式,就是個普通叢集。因為這導致你要麼消費者每次隨機連線一個例項然後拉取資料,要麼固定連線那個queue所在例項消費資料,前者有資料拉取的開銷,後者導致單例項效能瓶頸。
而且如果那個放queue的例項宕機了,會導致接下來其他例項就無法從那個例項拉取,如果你開啟了訊息持久化,讓rabbitmq落地儲存訊息的話,訊息不一定會丟,得等這個例項恢復了,然後才可以繼續從這個queue拉取資料。
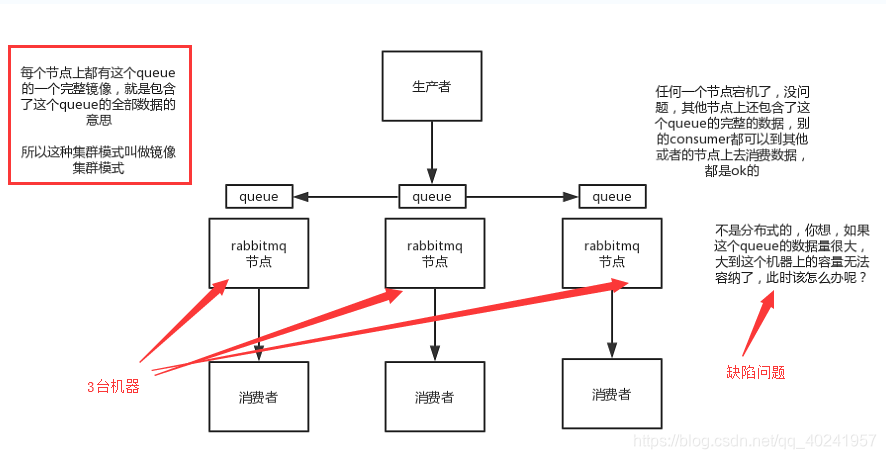
映象叢集模式:這種模式,才是所謂的rabbitmq的高可用模式,跟普通叢集模式不一樣的是,你建立的queue,無論元資料還是queue裡的訊息都會存在於多個例項上,然後每次你寫訊息到queue的時候,都會自動把訊息到多個例項的queue裡進行訊息同步。
這樣的話,好處在於,你任何一個機器宕機了,沒事兒,別的機器都可以用。壞處在於,第一,這個效能開銷也太大了吧,訊息同步所有機器,導致網路頻寬壓力和消耗很重!第二,這麼玩兒,就沒有擴充套件性可言了,如果某個queue負載很重,你加機器,新增的機器也包含了這個queue的所有資料,並沒有辦法線性擴充套件你的queue
那麼怎麼開啟這個映象叢集模式呢?我這裡簡單說一下,避免面試人家問你你不知道,其實很簡單rabbitmq有很好的管理控制檯,就是在後臺新增一個策略,這個策略是映象叢集模式的策略,指定的時候可以要求資料同步到所有節點的,也可以要求就同步到指定數量的節點,然後你再次建立queue的時候,應用這個策略,就會自動將資料同步到其他的節點上去了。
下面是普通叢集模式的高可用實現,但是還是有缺陷

映象叢集模式如下:(rabbitmq不是分散式的:(什麼意思呢?就是說不可能一個完整的資訊包分攤儲存在下圖中的3個機器上,每個機器都存一部分))
(2)kafka的高可用性 kafka一個最基本的架構認識:多個broker組成,每個broker是一個節點;你建立一個topic,這個topic可以劃分為多個partition,每個partition可以存在於不同的broker上,每個partition就放一部分資料。
這就是天然的分散式訊息佇列,就是說一個topic的資料,是分散放在多個機器上的,每個機器就放一部分資料。
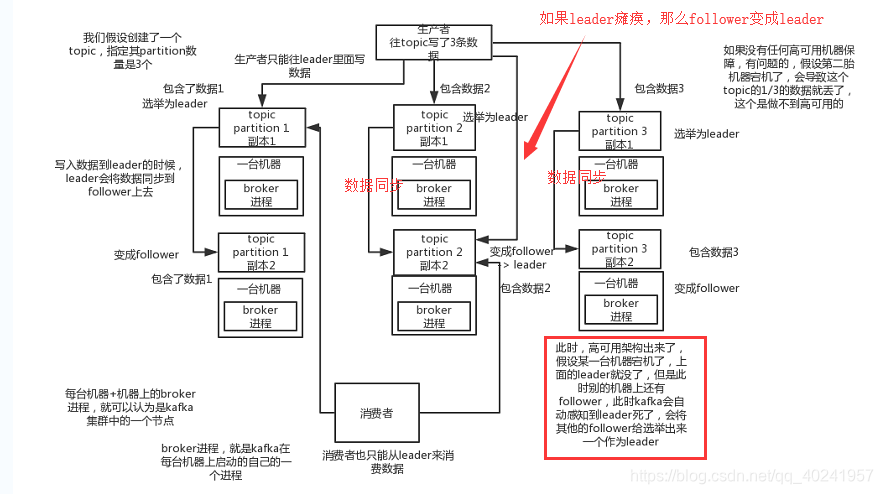
上圖重點:每臺機器+機器上的broker程序,就可以認為是kafaka叢集中的一個節點(上圖左下角)