
Hadoop學習(一)---搭建
阿新 • • 發佈:2018-12-22
一,VMware,Centos 7下載以及安裝
官網下載即可,然後虛擬機器安裝也是傻瓜式下一步下一步安裝。
二,JDK,hadoop安裝
1.JDK官網下載到虛擬機器,解壓到/opt/modules/目錄(沒有就建立一個)。
2.配置JDK環境變數。
進去解壓後的目錄,我的是
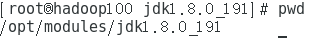
得到該路徑。

寫入這幾行
export JAVA_HOME="/opt/modules/jdk1.8.0_191"
export PATH=$JAVA_HOME/bin:$PATH
JAVA_HOME是上面pwd後得到的路徑。
3.測試JDK:

4.Hadoop下載到虛擬機器,解壓到/opt/modules/目錄(沒有就建立一個)。
5.配置Hadoop中的hadoop-env.sh
更改這一行,JAVA_HOME是剛剛pwd後得到的路徑

6.配置Hadoo環境變數
進去解壓後的目錄,我的是

得到該路徑。
寫入這幾行
export HADOOP_HOME=/opt/modules/hadoop-2.8.5
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
HADOOP_HOME是上面pwd後得到的路徑。
7.測試Hadoop:
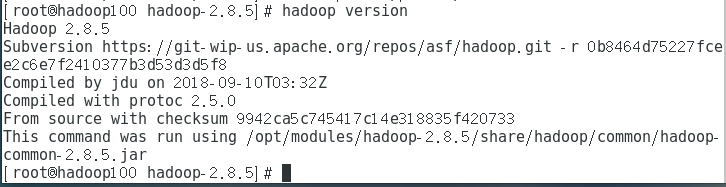
三,關閉防火牆,修改靜態ip,修改hostname
1.關閉防火牆
systemctl stop firewalld.service
2.修改靜態ip
2.1.關閉VMware中虛擬網路編輯器中DHCP服務
2.2.修改ifcfg-ens33檔案
vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO=static #修改 IPADDR="192.168.32.133" #增加 NETMAS="255.255.255.0" #增加 GATEWA="192.168.32.2" #增加 DNS="192.168.32.1" #增加 DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" UUID="0c99dbd0-79ee-45b4-9f84-dcab63e47a75" DEVICE="ens33" ONBOOT="yes" #修改 ~
2.3.重啟網路服務
service network restart
3.修改hostname
hostnamectl set-hostname xxx
四,本地執行Hadoop
1.建立一個資料夾存放資料
我的資料夾在:
/opt/modules/hadoop-2.8.5/input
裡面的資料為hadoop的配置資訊

2.執行share目錄下的mapreduce程式的grep案例:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar grep input/ output/ 'dfs[a-z]+'
input是存放輸入檔案的資料夾,output是存放輸出的資料夾(不能已經存在),後面的字串是需要匹配的。
結果是:

五,偽分散式執行Hadoop
1.首次使用需要(後面別再執行)namenode格式化
hdfs namenode -format
2.啟動namenode和datanode
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
3.上傳一個輸入檔案
hadoop fs -put wcinput/ /user
wcinput是本地上一個資料夾,裡面有資料,/user是hdfs上的資料夾
4.執行wordcount案例
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount /user/wcinput/ /user/output/
得到的結果再hdfs上的/user/output目錄