
從ConcurrentHashMap的演進看Java多執行緒核心技術
執行緒不安全的HashMap
眾所周知,HashMap是非執行緒安全的。而HashMap的執行緒不安全主要體現在resize時的死迴圈及使用迭代器時的fast-fail上。
注:本章的程式碼均基於JDK 1.7.0_67
HashMap工作原理
HashMap資料結構
常用的底層資料結構主要有陣列和連結串列。陣列儲存區間連續,佔用記憶體較多,定址容易,插入和刪除困難。連結串列儲存區間離散,佔用記憶體較少,定址困難,插入和刪除容易。
HashMap要實現的是雜湊表的效果,儘量實現O(1)級別的增刪改查。它的具體實現則是同時使用了陣列和連結串列,可以認為最外層是一個數組,陣列的每個元素是一個連結串列的表頭。
HashMap定址方式
對於新插入的資料或者待讀取的資料,HashMap將Key的雜湊值對陣列長度取模,結果作為該Entry在陣列中的index。在計算機中,取模的代價遠高於位操作的代價,因此HashMap要求陣列的長度必須為2的N次方。此時將Key的雜湊值對2^N-1進行與運算,其效果即與取模等效。HashMap並不要求使用者在指定HashMap容量時必須傳入一個2的N次方的整數,而是會通過Integer.highestOneBit算出比指定整數大的最小的2^N值,其實現方法如下。
1 2 3 4 5 6 7 8 |
public static int highestOneBit(int i) {
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
}
|
由於Key的雜湊值的分佈直接決定了所有資料在雜湊表上的分佈或者說決定了雜湊衝突的可能性,因此為防止糟糕的Key的hashCode實現(例如低位都相同,只有高位不相同,與2^N-1取與後的結果都相同),JDK 1.7的HashMap通過如下方法使得最終的雜湊值的二進位制形式中的1儘量均勻分佈從而儘可能減少雜湊衝突。
1 2 3 4 |
int h = hashSeed; h ^= k.hashCode(); h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); |
resize死迴圈
transfer方法
當HashMap的size超過Capacity*loadFactor時,需要對HashMap進行擴容。具體方法是,建立一個新的,長度為原來Capacity兩倍的陣列,保證新的Capacity仍為2的N次方,從而保證上述定址方式仍適用。同時需要通過如下transfer方法將原來的所有資料全部重新插入(rehash)到新的陣列中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
|
該方法並不保證執行緒安全,而且在多執行緒併發呼叫時,可能出現死迴圈。其執行過程如下。從步驟2可見,轉移時連結串列順序反轉。
- 遍歷原陣列中的元素
- 對連結串列上的每一個節點遍歷:用next取得要轉移那個元素的下一個,將e轉移到新陣列的頭部,使用頭插法插入節點
- 迴圈2,直到連結串列節點全部轉移
- 迴圈1,直到所有元素全部轉移
單執行緒rehash
單執行緒情況下,rehash無問題。下圖演示了單執行緒條件下的rehash過程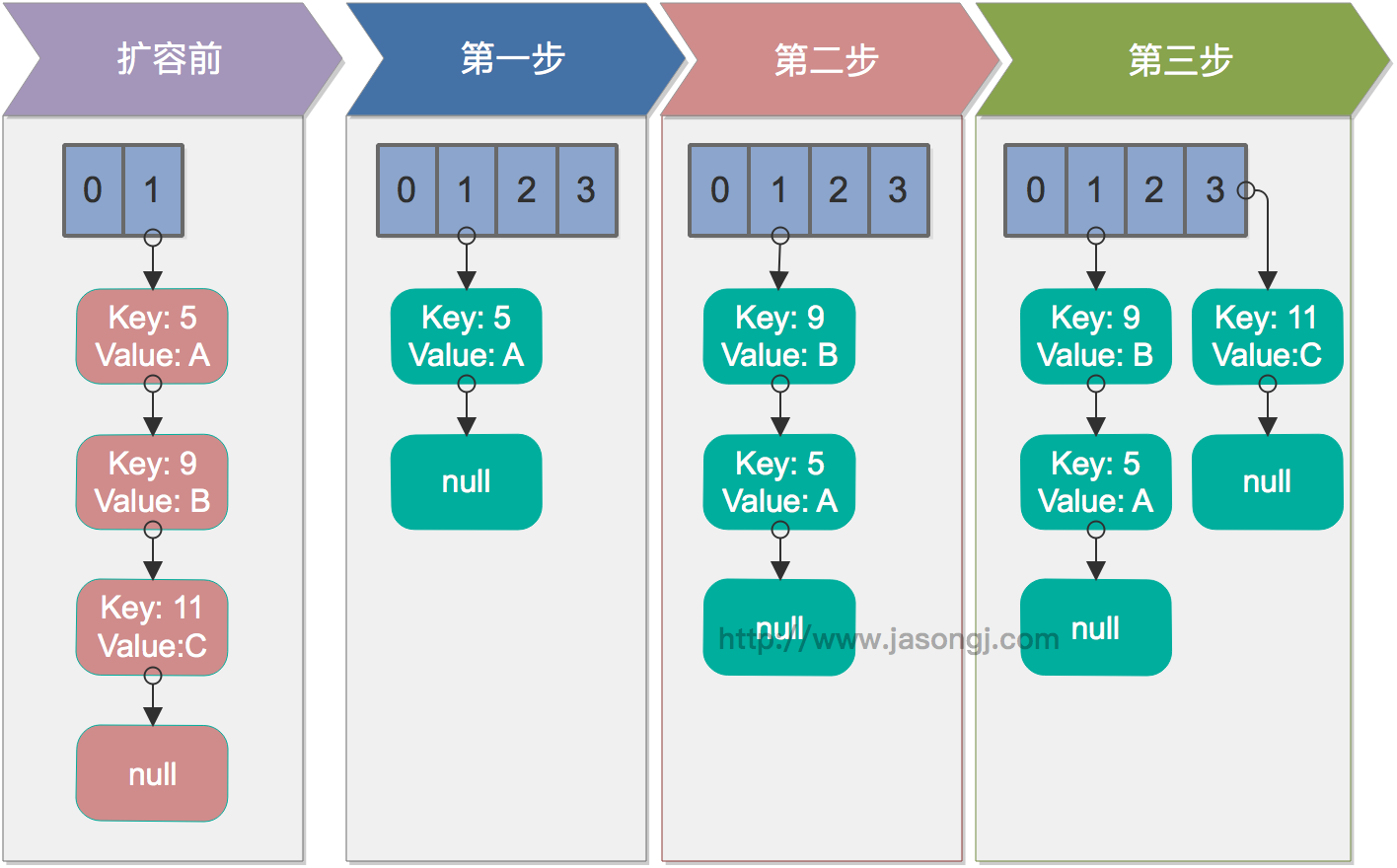
多執行緒併發下的rehash
這裡假設有兩個執行緒同時執行了put操作並引發了rehash,執行了transfer方法,並假設執行緒一進入transfer方法並執行完next = e.next後,因為執行緒排程所分配時間片用完而“暫停”,此時執行緒二完成了transfer方法的執行。此時狀態如下。
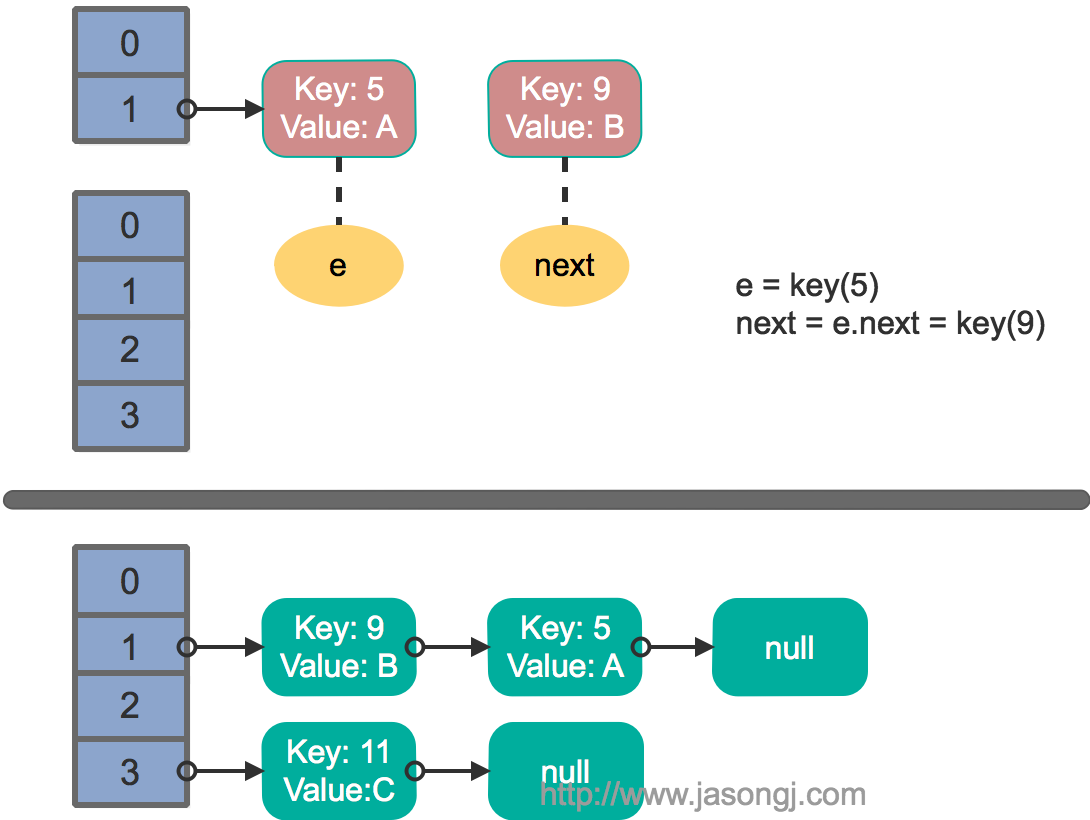
接著執行緒1被喚醒,繼續執行第一輪迴圈的剩餘部分
1 2 3 |
e.next = newTable[1] = null newTable[1] = e = key(5) e = next = key(9) |
結果如下圖所示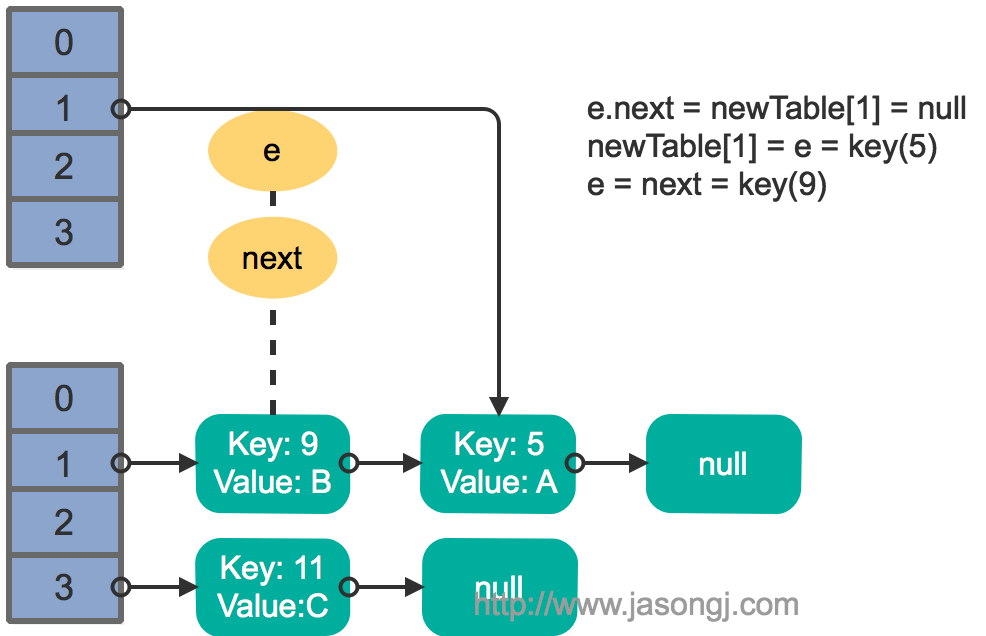
接著執行下一輪迴圈,結果狀態圖如下所示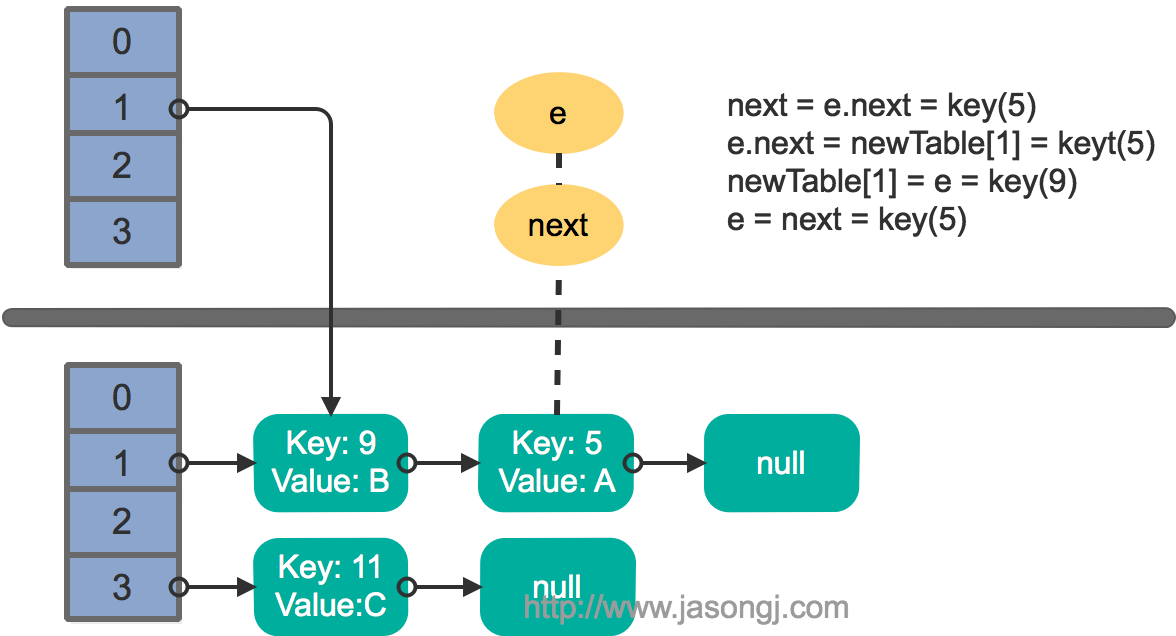
繼續下一輪迴圈,結果狀態圖如下所示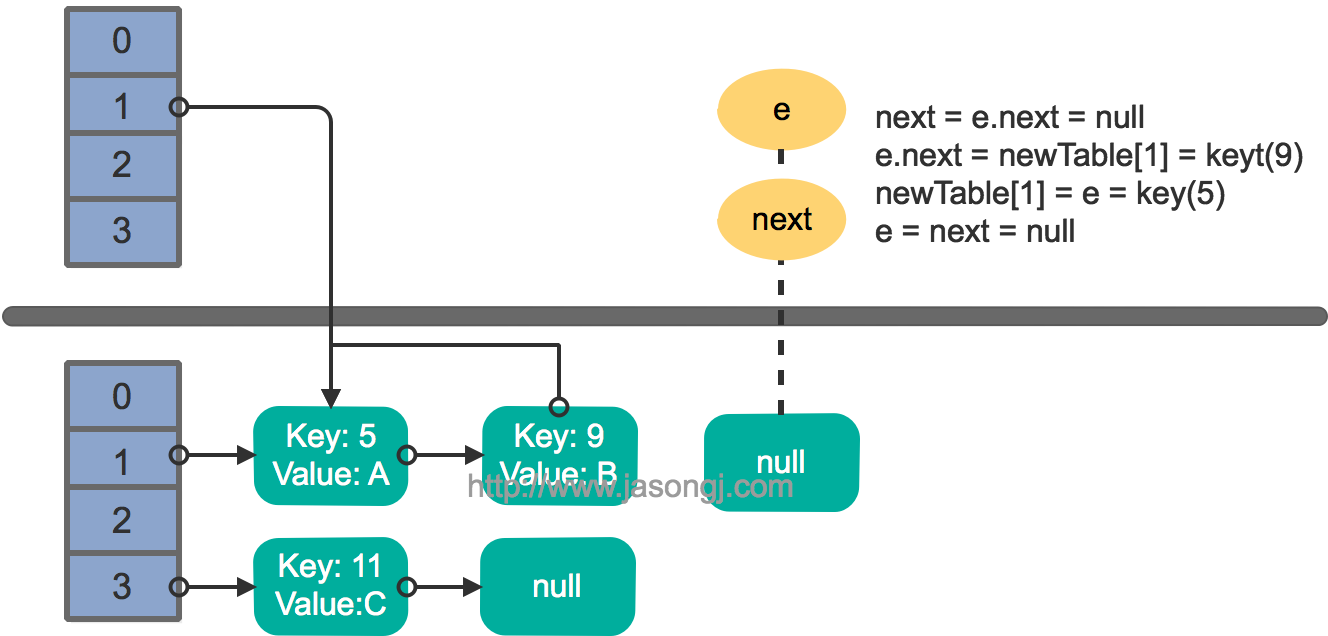
此時迴圈連結串列形成,並且key(11)無法加入到執行緒1的新陣列。在下一次訪問該連結串列時會出現死迴圈。
Fast-fail
產生原因
在使用迭代器的過程中如果HashMap被修改,那麼ConcurrentModificationException將被丟擲,也即Fast-fail策略。
當HashMap的iterator()方法被呼叫時,會構造並返回一個新的EntryIterator物件,並將EntryIterator的expectedModCount設定為HashMap的modCount(該變數記錄了HashMap被修改的次數)。
1 2 3 4 5 6 7 8 |
HashIterator() {
expectedModCount = modCount;
if (size > 0) { // advance to first entry
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
}
|
在通過該Iterator的next方法訪問下一個Entry時,它會先檢查自己的expectedModCount與HashMap的modCount是否相等,如果不相等,說明HashMap被修改,直接丟擲ConcurrentModificationException。該Iterator的remove方法也會做類似的檢查。該異常的丟擲意在提醒使用者及早意識到執行緒安全問題。
執行緒安全解決方案
單執行緒條件下,為避免出現ConcurrentModificationException,需要保證只通過HashMap本身或者只通過Iterator去修改資料,不能在Iterator使用結束之前使用HashMap本身的方法修改資料。因為通過Iterator刪除資料時,HashMap的modCount和Iterator的expectedModCount都會自增,不影響二者的相等性。如果是增加資料,只能通過HashMap本身的方法完成,此時如果要繼續遍歷資料,需要重新呼叫iterator()方法從而重新構造出一個新的Iterator,使得新Iterator的expectedModCount與更新後的HashMap的modCount相等。
多執行緒條件下,可使用Collections.synchronizedMap方法構造出一個同步Map,或者直接使用執行緒安全的ConcurrentHashMap。
Java 7基於分段鎖的ConcurrentHashMap
注:本章的程式碼均基於JDK 1.7.0_67
資料結構
Java 7中的ConcurrentHashMap的底層資料結構仍然是陣列和連結串列。與HashMap不同的是,ConcurrentHashMap最外層不是一個大的陣列,而是一個Segment的陣列。每個Segment包含一個與HashMap資料結構差不多的連結串列陣列。整體資料結構如下圖所示。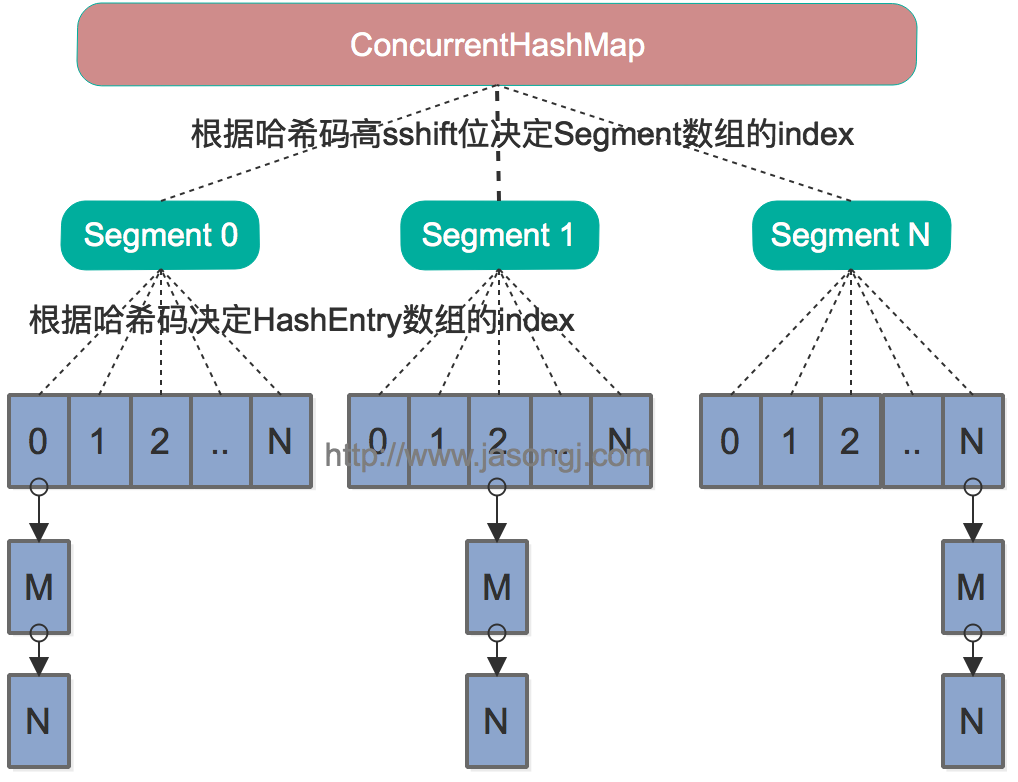
定址方式
在讀寫某個Key時,先取該Key的雜湊值。並將雜湊值的高N位對Segment個數取模從而得到該Key應該屬於哪個Segment,接著如同操作HashMap一樣操作這個Segment。為了保證不同的值均勻分佈到不同的Segment,需要通過如下方法計算雜湊值。
1 2 3 4 5 6 7 8 9 10 11 12 13 |
private int hash(Object k) {
int h = hashSeed;
if ((0 != h) && (k instanceof String)) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
|
同樣為了提高取模運算效率,通過如下計算,ssize即為大於concurrencyLevel的最小的2的N次方,同時segmentMask為2^N-1。這一點跟上文中計算陣列長度的方法一致。對於某一個Key的雜湊值,只需要向右移segmentShift位以取高sshift位,再與segmentMask取與操作即可得到它在Segment陣列上的索引。
1 2 3 4 5 6 7 8 9 |
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
|
同步方式
Segment繼承自ReentrantLock,所以我們可以很方便的對每一個Segment上鎖。
對於讀操作,獲取Key所在的Segment時,需要保證可見性(請參考如何保證多執行緒條件下的可見性)。具體實現上可以使用volatile關鍵字,也可使用鎖。但使用鎖開銷太大,而使用volatile時每次寫操作都會讓所有CPU內快取無效,也有一定開銷。ConcurrentHashMap使用如下方法保證可見性,取得最新的Segment。
1 |
Segment<K,V> s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u) |
獲取Segment中的HashEntry時也使用了類似方法
1 2 |
HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE) |
對於寫操作,並不要求同時獲取所有Segment的鎖,因為那樣相當於鎖住了整個Map。它會先獲取該Key-Value對所在的Segment的鎖,獲取成功後就可以像操作一個普通的HashMap一樣操作該Segment,並保證該Segment的安全性。
同時由於其它Segment的鎖並未被獲取,因此理論上可支援concurrencyLevel(等於Segment的個數)個執行緒安全的併發讀寫。
獲取鎖時,並不直接使用lock來獲取,因為該方法獲取鎖失敗時會掛起(參考可重入鎖)。事實上,它使用了自旋鎖,如果tryLock獲取鎖失敗,說明鎖被其它執行緒佔用,此時通過迴圈再次以tryLock的方式申請鎖。如果在迴圈過程中該Key所對應的連結串列頭被修改,則重置retry次數。如果retry次數超過一定值,則使用lock方法申請鎖。
這裡使用自旋鎖是因為自旋鎖的效率比較高,但是它消耗CPU資源比較多,因此在自旋次數超過閾值時切換為互斥鎖。
size操作
put、remove和get操作只需要關心一個Segment,而size操作需要遍歷所有的Segment才能算出整個Map的大小。一個簡單的方案是,先鎖住所有Sgment,計算完後再解鎖。但這樣做,在做size操作時,不僅無法對Map進行寫操作,同時也無法進行讀操作,不利於對Map的並行操作。
為更好支援併發操作,ConcurrentHashMap會在不上鎖的前提逐個Segment計算3次size,如果某相鄰兩次計算獲取的所有Segment的更新次數(每個Segment都與HashMap一樣通過modCount跟蹤自己的修改次數,Segment每修改一次其modCount加一)相等,說明這兩次計算過程中無更新操作,則這兩次計算出的總size相等,可直接作為最終結果返回。如果這三次計算過程中Map有更新,則對所有Segment加鎖重新計算Size。該計算方法程式碼如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
public int size() {
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
|
不同之處
ConcurrentHashMap與HashMap相比,有以下不同點
- ConcurrentHashMap執行緒安全,而HashMap非執行緒安全
- HashMap允許Key和Value為null,而ConcurrentHashMap不允許
- HashMap不允許通過Iterator遍歷的同時通過HashMap修改,而ConcurrentHashMap允許該行為,並且該更新對後續的遍歷可見
Java 8基於CAS的ConcurrentHashMap
注:本章的程式碼均基於JDK 1.8.0_111
資料結構
Java 7為實現並行訪問,引入了Segment這一結構,實現了分段鎖,理論上最大併發度與Segment個數相等。Java 8為進一步提高併發性,摒棄了分段鎖的方案,而是直接使用一個大的陣列。同時為了提高雜湊碰撞下的定址效能,Java 8在連結串列長度超過一定閾值(8)時將連結串列(定址時間複雜度為O(N))轉換為紅黑樹(定址時間複雜度為O(long(N)))。其資料結構如下圖所示
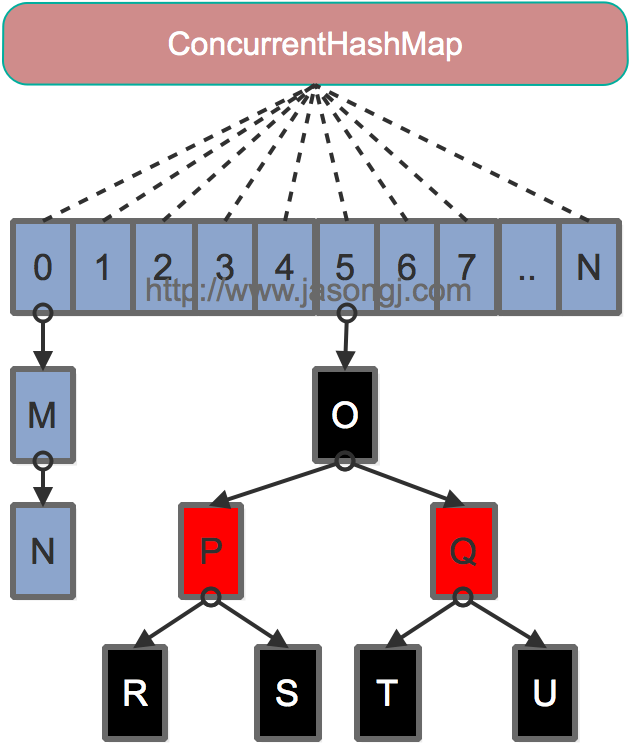
定址方式
Java 8的ConcurrentHashMap同樣是通過Key的雜湊值與陣列長度取模確定該Key在陣列中的索引。同樣為了避免不太好的Key的hashCode設計,它通過如下方法計算得到Key的最終雜湊值。不同的是,Java 8的ConcurrentHashMap作者認為引入紅黑樹後,即使雜湊衝突比較嚴重,定址效率也足夠高,所以作者並未在雜湊值的計算上做過多設計,只是將Key的hashCode值與其高16位作異或並保證最高位為0(從而保證最終結果為正整數)。
1 2 3 |
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
|
同步方式
對於put操作,如果Key對應的陣列元素為null,則通過CAS操作將其設定為當前值。如果Key對應的陣列元素(也即連結串列表頭或者樹的根元素)不為null,則對該元素使用synchronized關鍵字申請鎖,然後進行操作。如果該put操作使得當前連結串列長度超過一定閾值,則將該連結串列轉換為樹,從而提高定址效率。
對於讀操作,由於陣列被volatile關鍵字修飾,因此不用擔心陣列的可見性問題。同時每個元素是一個Node例項(Java 7中每個元素是一個HashEntry),它的Key值和hash值都由final修飾,不可變更,無須關心它們被修改後的可見性問題。而其Value及對下一個元素的引用由volatile修飾,可見性也有保障。
1 2 3 4 5 6 |
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
|
對於Key對應的陣列元素的可見性,由Unsafe的getObjectVolatile方法保證。
1 2 3 |
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
|
size操作
put方法和remove方法都會通過addCount方法維護Map的size。size方法通過sumCount獲取由addCount方法維護的Map的size。