
貸款逾期(3)--XGBoost與Lightgm
阿新 • • 發佈:2018-12-22
任務三
構建xgboost和lightgbm模型進行預測。
遇到的問題
- 引數不知道怎麼呼叫
- xgboost的介面和sklearn介面不明白
- LGB和XGB自帶介面預測(predict)的都是概率
- 訓練之前都要將資料轉化為相應模型所需的格式
程式碼
特徵處理
import pickle import pandas as pd #資料分析 from pandas import Series,DataFrame from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler import time print("開始......") t_start = time.time() path = "E:/mypython/moxingxuexi/data/" """===================================================================================================================== 1 讀取資料 """ print("資料預處理") data = pd.read_csv(path + 'data.csv',encoding='gbk') """===================================================================================================================== 2 資料處理 """ """將每一個樣本的缺失值的個數作為一個特徵""" temp1=data.isnull() num=(temp1 == True).astype(bool).sum(axis=1) is_null=DataFrame(list(zip(num))) is_null=is_null.rename(columns={0:"is_null_num"}) data = pd.merge(data,is_null,left_index = True, right_index = True, how = 'outer') """ 1.1 缺失值用100填充 """ data=DataFrame(data.fillna(100)) """ 1.2 對reg_preference_for_trad 的處理 【對映】 nan=0 境外=1 一線=5 二線=2 三線 =3 其他=4 """ n=set(data['reg_preference_for_trad']) dic={} for i,j in enumerate(n): dic[j]=i data['reg_preference_for_trad'] = data['reg_preference_for_trad'].map(dic) """ 1.2 對source 的處理 【對映】 """ n=set(data['source']) dic={} for i,j in enumerate(n): dic[j]=i data['source'] = data['source'].map(dic) """ 1.3 對bank_card_no 的處理 【對映】 """ n=set(data['bank_card_no']) dic={} for i,j in enumerate(n): dic[j]=i data['bank_card_no'] = data['bank_card_no'].map(dic) """ 1.2 對 id_name的處理 【對映】 """ n=set(data['id_name']) dic={} for i,j in enumerate(n): dic[j]=i data['id_name'] = data['id_name'].map(dic) """ 1.2 對 time 的處理 【刪除】 """ data.drop(["latest_query_time"],axis=1,inplace=True) data.drop(["loans_latest_time"],axis=1,inplace=True) data.drop(['trade_no'],axis=1,inplace=True) status = data.status # """===================================================================================================================== # 4 time時間歸一化 小時 # """ # data['time'] = pd.to_datetime(data['time']) # time_now = data['time'].apply(lambda x:int((x-datetime(2018,11,14,0,0,0)).seconds/3600)) # data['time']= time_now """===================================================================================================================== 2 劃分訓練集和驗證集,驗證集比例為test_size """ print("劃分訓練集和驗證集,驗證集比例為test_size") train, test = train_test_split(data, test_size=0.3, random_state=666) """ 標準化資料 """ standardScaler = StandardScaler() train_fit = standardScaler.fit_transform(train) test_fit = standardScaler.transform(test) """===================================================================================================================== 3 分標籤和 訓練資料 """ y_train= train.status train.drop(["status"],axis=1,inplace=True) y_test= test.status test.drop(["status"],axis=1,inplace=True) print("3 儲存至本地") data = (train, test, y_train,y_test) fp = open( 'E:/mypython/moxingxuexi/feature/V3.pkl', 'wb') pickle.dump(data, fp) fp.close()
XGB
#!/user/bin/env python #-*- coding:utf-8 -*- import pickle import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from pandas import Series,DataFrame from xgboost import XGBClassifier from sklearn.metrics import accuracy_score,f1_score,r2_score """ 讀取特徵資料 """ path= "E:/mypython/moxingxuexi/" f = open(path + 'feature/V3.pkl','rb') train,test,y_train,y_test= pickle.load(f) f.close() """ 模型訓練 """ print("xgb訓練模型") xgb_model = XGBClassifier() xgb_model.fit(train,y_train) """ 模型預測 """ y_test_pre =xgb_model.predict(test) """ 模型評估 """ f1 = f1_score(y_test,y_test_pre,average='macro') print("f1的分數: {}".format(f1)) r2 = r2_score(y_test,y_test_pre) print("f2分數:{}".format(r2)) score = xgb_model.score(test,y_test) print("驗證集分數:{}".format(score))
結果

XGB1
用的自帶介面與sklearn介面
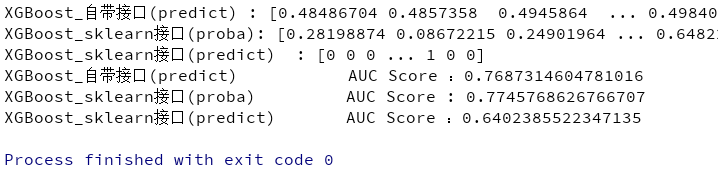
#!/user/bin/env python #-*- coding:utf-8 -*- # @Time : 2018/11/18 15:07 # @Author : 劉 # @Site : # @File : xgb1.py # @Software: PyCharm import pickle import xgboost as xgb import pandas as pd from sklearn.model_selection import train_test_split from xgboost.sklearn import XGBClassifier from sklearn import metrics from sklearn.externals import joblib print("開始") """ 讀取特徵 """ path = "E:/mypython/moxingxuexi/" f = open(path+ 'feature/V3.pkl','rb') train ,test,y_train,y_test=pickle.load(f) f.close() """ 將資料格式轉換成XGB所需的格式 """ xgb_val = xgb.DMatrix(test,label= y_test) xgb_train = xgb.DMatrix(train,y_train) xgb_test = xgb.DMatrix(test) """ 模型引數設定 """ ##XGB自帶介面 params={ 'booster': 'gbtree',#常用的booster有樹模型(tree)和線性模型(linear model) 'objective': 'reg:linear', 'gamma': 0.1,#用於控制是否後剪枝的引數,越大越保守一般是0.1,0.2 'max_depth': 10,#構建樹的深度,越大越容易過擬合 'lambda': 2,#控制權重值的L2正則化項引數,引數越大,模型越不容易過擬合 'subsample': 0.7,#隨機訓練樣本 'colsample_bytree': 0.7,#生成樹時進行的列取樣 'min_child_weight': 3, # 這個引數預設是 1,是每個葉子裡面 h 的和至少是多少,對正負樣本不均衡時的 0-1 分類而言 #,假設 h 在 0.01 附近,min_child_weight 為 1 意味著葉子節點中最少需要包含 100 個樣本。 #這個引數非常影響結果,控制葉子節點中二階導的和的最小值,該引數值越小,越容易 overfitting。 'silent': 0,#設定成1則沒有執行資訊輸出,最好是設定為0 'eta': 0.001,# 如同學習率 'seed': 1000,#隨機種子 # 'nthread':7,# cpu 執行緒數 #'eval_metric': # 'auc' } plst = list(params.items())## 轉化為list num_rounds = 50 # 設定迭代次數 #sklearn介面 ##分類使用XGBClassifier ##迴歸使用XGBRegression clf = XGBClassifier( n_estimators =30, learning_rate =0.3, max_depth=3, min_child_weight=1, gamma=0.3, subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=12, scale_pos_weight=1, reg_lambda=1, seed=27) watchlist = [(xgb_train, 'train'),(xgb_val, 'val')] """ 模型訓練 """ # training model #early_stopping_rounds 當設定的迭代次數較大時,early_stopping_rounds 可在一定的迭代次數內準確率沒有提升就停止訓練 # 使用XGBoost有自帶介面 """使用XGBOOST自帶訓練介面""" model_xgb= xgb.train(plst,xgb_train,num_rounds,watchlist,early_stopping_rounds=100) """使用sklenar介面訓練""" model_xgb_sklearn =clf.fit(train,y_train) """ 模型儲存 """ print('模型儲存') joblib.dump(model_xgb,path+"model/xgb.pkl") joblib.dump(model_xgb_sklearn,path+"model/xgb_sklearn.pkl") """ 模型預測 """ """【使用XGB自帶介面預測】""" y_xgb=model_xgb.predict(xgb_test) """【使用xgb sklearn預測】""" y_sklearn_pre= model_xgb_sklearn.predict(test) y_sklearn_proba= model_xgb_sklearn.predict_proba(test)[:,1] """5 模型評分""" print("XGBoost_自帶介面(predict) : %s" % y_xgb) print("XGBoost_sklearn介面(proba): %s" % y_sklearn_proba) print("XGBoost_sklearn介面(predict) : %s" % y_sklearn_pre) # print("XGBoost_自帶介面(predict) AUC Score : %f" % metrics.roc_auc_score(y_test, y_xgb)) # print("XGBoost_sklearn介面(proba) AUC Score : %f" % metrics.roc_auc_score(y_test, y_sklearn_proba)) # print("XGBoost_sklearn介面(predict) AUC Score : %f" % metrics.roc_auc_score(y_test, y_sklearn_pre)) """【roc_auc_score】""" #直接根據真實值(必須是二值)、預測值(可以是0/1,也可以是proba值)計算出auc值,中間過程的roc計算省略。 # f1 = f1_score(y_test, predictions, average='macro') print("XGBoost_自帶介面(predict) AUC Score :{}".format(metrics.roc_auc_score(y_test, y_xgb))) print("XGBoost_sklearn介面(proba) AUC Score : {}".format(metrics.roc_auc_score(y_test, y_sklearn_proba))) print("XGBoost_sklearn介面(predict) AUC Score :{}".format(metrics.roc_auc_score(y_test, y_sklearn_pre)))
評分
LGB
#!/user/bin/env python
#-*- coding:utf-8 -*-
# @Time : 2018/11/17 23:03
# @Author : 劉
# @Site :
# @File : lig.py
# @Software: PyCharm
import pickle
import pandas as pd
from pandas import Series,DataFrame
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.metrics import f1_score,r2_score
"""
讀取特徵
"""
path= "E:/mypython/moxingxuexi/"
f =open(path + 'feature/V3.pkl','rb')
train,test,y_train,y_test= pickle.load(f)
f.close()
"""
模型訓練
"""
print("lgb模型訓練")
lgb_model = LGBMClassifier()
lgb_model.fit(train,y_train)
"""
模型預測
"""
y_test_pre = lgb_model.predict(test)
"""
模型評估
"""
f1 = f1_score(y_test,y_test_pre,average='macro')
print("f1的分數: {}".format(f1))
r2 = r2_score(y_test,y_test_pre)
print("f2分數:{}".format(r2))
score = lgb_model.score(test,y_test)
print("驗證集分數:{}".format(score))評分

LGB1
#!/user/bin/env python
#-*- coding:utf-8 -*-
# @Time : 2018/11/17 23:03
# @Author : 劉
# @Site :
# @File : lig.py
# @Software: PyCharm
import pickle
import pandas as pd
from pandas import Series,DataFrame
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.metrics import f1_score,r2_score
"""
讀取特徵
"""
path= "E:/mypython/moxingxuexi/"
f =open(path + 'feature/V3.pkl','rb')
train,test,y_train,y_test= pickle.load(f)
f.close()
"""
模型訓練
"""
print("lgb模型訓練")
lgb_model = LGBMClassifier()
lgb_model.fit(train,y_train)
"""
模型預測
"""
y_test_pre = lgb_model.predict(test)
"""
模型評估
"""
f1 = f1_score(y_test,y_test_pre,average='macro')
print("f1的分數: {}".format(f1))
r2 = r2_score(y_test,y_test_pre)
print("f2分數:{}".format(r2))
score = lgb_model.score(test,y_test)
print("驗證集分數:{}".format(score))評分
