排程演算法-尋找predicates和priorities

scheduler的主要邏輯是predicate和priority,前者回答哪些節點可以執行pod的問題,後者回答哪個節點更合適執行pod的問題。今天我們的任務是:從主函數出發,尋找predicates和priorities的入口!
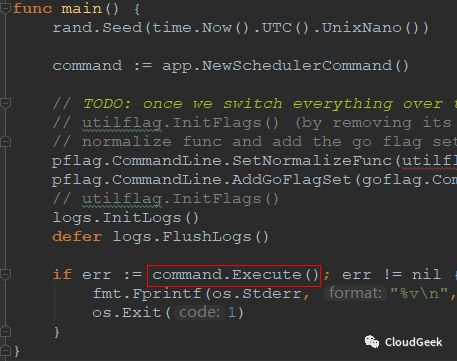
前面我們提到過Execute()其實是運行了這個Run方法,在cmd/kube-scheduler/app/server.go的337行。
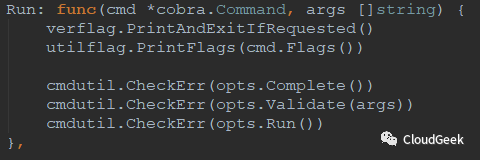
順著opts.Run()往裡跟:
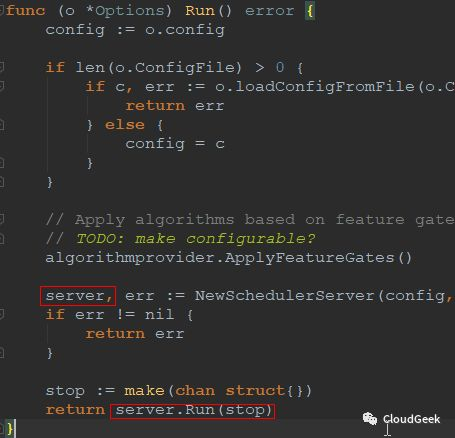
可以很清楚看到opts.Run()的邏輯,初始化一個server,然後執行server.Run()方法。這裡的server型別是*SchedulerServer,這個型別的官方解釋是:
SchedulerServer represents all the parameters required to start the kubernetes scheduler server. 也就是說執行scheduler server所需的所有引數集合:
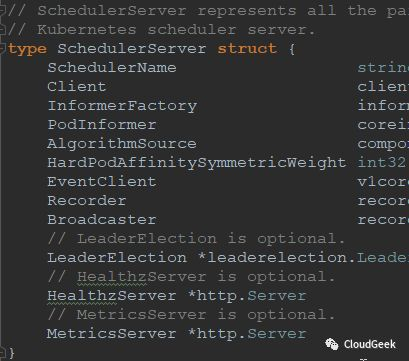
我們順著主幹往下走,看一下server.Run()方法的定義:
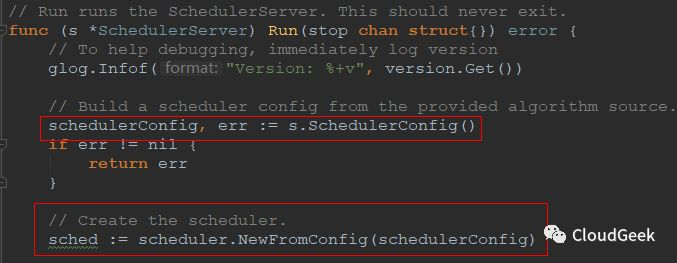
如上圖,我們需要關注一下函式開頭的註釋,這個Run是要執行SchedulerServer,永遠不退出!也就是說到這裡就啟動了一個server,開始無怨無悔永不停息地處理pod的scheduler流程!接著通過一個方法SchedulerConfig()獲取到一個物件叫做schedulerConfig,我們也看一下這個物件的定義:Config is an implementation of the Scheduler's configured input data.
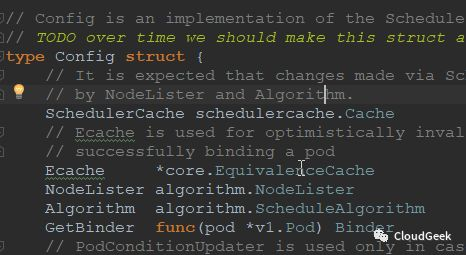
最後一個sched的建立代表著scheduler的daemon程式準備差不多了!sched的型別如下:

從註釋中我們可以得到很多資訊,Scheduler監視者未排程的pods,嘗試尋找合適的node,把pod和node的繫結關係告訴api server!Run函式繼續往後看可以找到(server.go的602行):
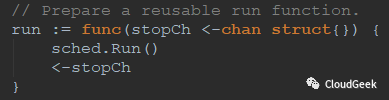
可以看到準備好了一個sched.Run(),但是沒有立刻執行,626行有一個run(stop),就不貼截圖了,我們直接跟到sched.Run()這個方法看一下里面寫了啥:
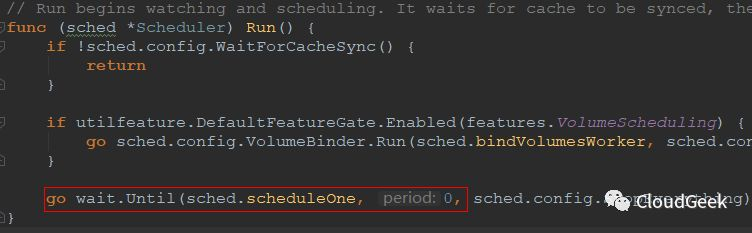
這個Run()方法開始watching and scheduling,最後面的紅框需要注意幾點,這是新開一個goroutine執行,然後立刻返回的。新開的goroutine是幹嘛呢?每隔0秒就執行一次sched.scheduleOne方法!這裡的0秒可能需要理解一下,我們看一下wait.Until()方法的定義:
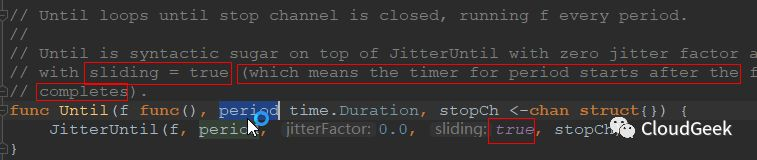
ok,其實是當f這個函式被呼叫完成後過0秒開始下一次呼叫,說白了就是前赴後繼中間不休息!後面我們當然繼續看scheduleOne()方法做了啥:
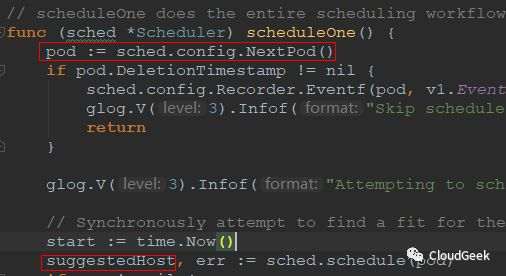
可以看到scheduleOne()方法能夠處理一個pod完整的schedulering工作流。第一步是獲取一個pod,這個pod的獲取方法是這樣定義的:

這裡我們關注一下這個方法首先是阻塞的,也就是不返回一個結果就一直卡住。接著看一下suggestedHost是什麼:
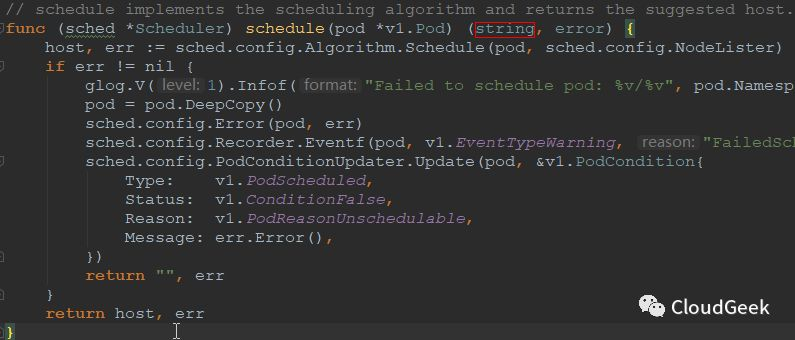
可以看到,這個型別是string,string不就意味著這就是最後的結果嗎?不然怎麼著也是一個[]string是吧???所以這裡的suggestedHost也就是最後排程演算法所給出建議跑pod的host!!!ok,我們的路沒有偏離主線,繼續看schedule方法的邏輯(上圖中可以看到host是通過方法:sched.config.Algorithm.Schedule()獲取的,我們直接看Schedule()方法):
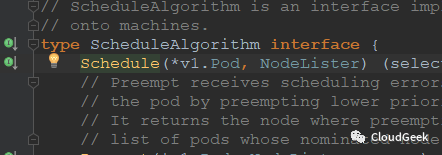
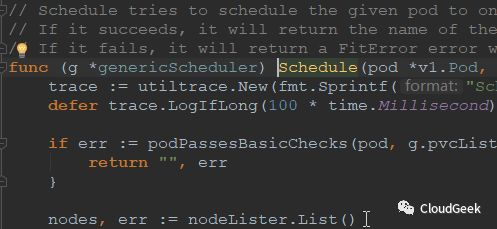
這個方法的引數是pod資訊和node資訊(獲取node資訊的介面),返回值是string型別,也就是根據pod資訊和nodes資訊看pod能夠跑在哪個node上,然後返回這個node的名字!

上圖從generic_scheduler.go的134行開始,這個msg資訊很有意思,"Computing predicates",後面的findNodesThatFit()函式返回filteredNodes,也就是predicates過程的結果,返回的filteredNodes也就是可以執行pod的node集合!往下看150行處:
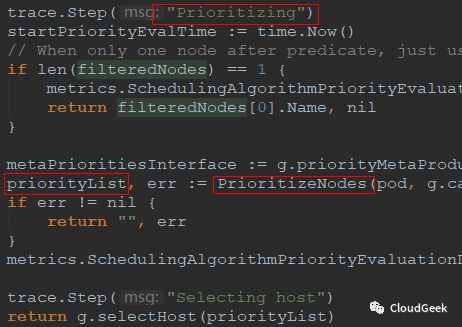
可以看到priorities過程在這裡,PrioritizeNodes()函式返回一個priorityList,這個priorityList是schedulerapi.HostPriorityList型別,也就是[]HostPriority型別,HostPriority型別的定義如下:
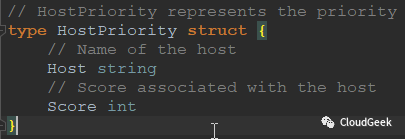
可以看到,這個型別其實存的資料就是一個節點的名字和分數資訊,也就是說PrioritizeNodes()函式完成了所有可以跑pod的node的分數計算!結尾的selectHost()方法就很簡單是,選擇一個分高的host返回:
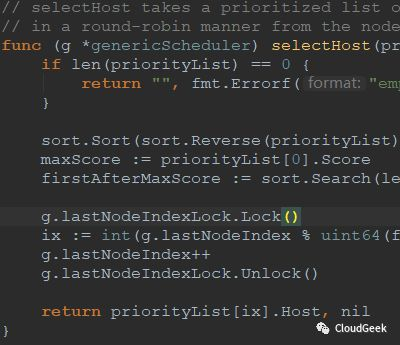
ok,總算跟完了,到這裡我們就完成了整個排程過程的略讀,下次開始我們可以看具體的predicates和priorities演算法了!