
聊聊併發(四)深入分析ConcurrentHashMap
術語定義
| 術語 | 英文 | 解釋 |
| 雜湊演算法 | hash algorithm | 是一種將任意內容的輸入轉換成相同長度輸出的加密方式,其輸出被稱為雜湊值。 |
| 雜湊表 | hash table | 根據設定的雜湊函式H(key)和處理衝突方法將一組關鍵字映象到一個有限的地址區間上,並以關鍵字在地址區間中的象作為記錄在表中的儲存位置,這種表稱為雜湊表或雜湊,所得儲存位置稱為雜湊地址或雜湊地址。 |
執行緒不安全的HashMap
因為多執行緒環境下,使用Hashmap進行put操作會引起死迴圈,導致CPU利用率接近100%,所以在併發情況下不能使用HashMap。
如以下程式碼:
final HashMap<String, String> map = new HashMap<String, String>(2);
Thread t = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
map.put(UUID.randomUUID().toString(), "");
}
}, "ftf" + i).start();
}
}
}, "ftf");
t.start();
t.join();
效率低下的HashTable容器
HashTable容器使用synchronized來保證執行緒安全,但線上程競爭激烈的情況下HashTable的效率非常低下。因為當一個執行緒訪問HashTable的同步方法時,其他執行緒訪問HashTable的同步方法時,可能會進入阻塞或輪詢狀態。如執行緒1使用put進行新增元素,執行緒2不但不能使用put方法新增元素,並且也不能使用get方法來獲取元素,所以競爭越激烈效率越低。
ConcurrentHashMap的鎖分段技術
HashTable容器在競爭激烈的併發環境下表現出效率低下的原因,是因為所有訪問HashTable的執行緒都必須競爭同一把鎖,那假如容器裡有多把鎖,每一把鎖用於鎖容器其中一部分資料,那麼當多執行緒訪問容器裡不同資料段的資料時,執行緒間就不會存在鎖競爭,從而可以有效的提高併發訪問效率,這就是ConcurrentHashMap所使用的鎖分段技術,首先將資料分成一段一段的儲存,然後給每一段資料配一把鎖,當一個執行緒佔用鎖訪問其中一個段資料的時候,其他段的資料也能被其他執行緒訪問。
ConcurrentHashMap的結構
我們通過ConcurrentHashMap的類圖來分析ConcurrentHashMap的結構。
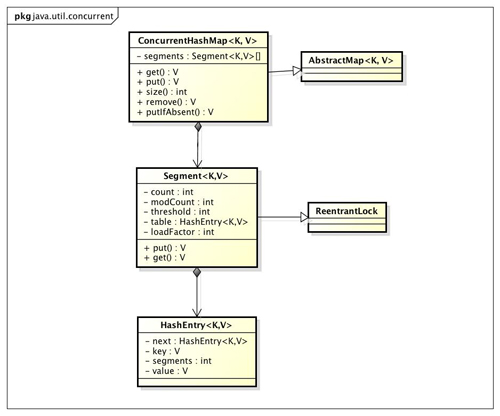
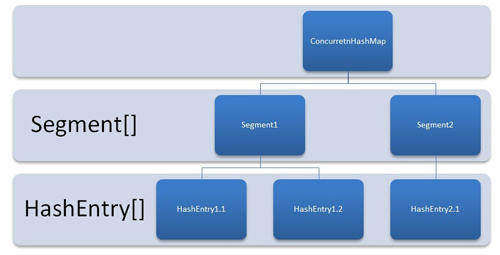
ConcurrentHashMap是由Segment陣列結構和HashEntry陣列結構組成。Segment是一種可重入鎖ReentrantLock,在ConcurrentHashMap裡扮演鎖的角色,HashEntry則用於儲存鍵值對資料。一個ConcurrentHashMap裡包含一個Segment陣列,Segment的結構和HashMap類似,是一種陣列和連結串列結構, 一個Segment裡包含一個HashEntry陣列,每個HashEntry是一個連結串列結構的元素, 每個Segment守護者一個HashEntry數組裡的元素,當對HashEntry陣列的資料進行修改時,必須首先獲得它對應的Segment鎖。
ConcurrentHashMap的初始化
ConcurrentHashMap初始化方法是通過initialCapacity,loadFactor, concurrencyLevel幾個引數來初始化segments陣列,段偏移量segmentShift,段掩碼segmentMask和每個segment裡的HashEntry陣列。
初始化segments陣列。讓我們來看一下初始化segmentShift,segmentMask和segments陣列的原始碼。
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
segmentShift = 32 - sshift;
segmentMask = ssize - 1;
this.segments = Segment.newArray(ssize);
由上面的程式碼可知segments陣列的長度ssize通過concurrencyLevel計算得出。為了能通過按位與的雜湊演算法來定位segments陣列的索引,必須保證segments陣列的長度是2的N次方(power-of-two size),所以必須計算出一個是大於或等於concurrencyLevel的最小的2的N次方值來作為segments陣列的長度。假如concurrencyLevel等於14,15或16,ssize都會等於16,即容器裡鎖的個數也是16。注意concurrencyLevel的最大大小是65535,意味著segments陣列的長度最大為65536,對應的二進位制是16位。
初始化segmentShift和segmentMask。這兩個全域性變數在定位segment時的雜湊演算法裡需要使用,sshift等於ssize從1向左移位的次數,在預設情況下concurrencyLevel等於16,1需要向左移位移動4次,所以sshift等於4。segmentShift用於定位參與hash運算的位數,segmentShift等於32減sshift,所以等於28,這裡之所以用32是因為ConcurrentHashMap裡的hash()方法輸出的最大數是32位的,後面的測試中我們可以看到這點。segmentMask是雜湊運算的掩碼,等於ssize減1,即15,掩碼的二進位制各個位的值都是1。因為ssize的最大長度是65536,所以segmentShift最大值是16,segmentMask最大值是65535,對應的二進位制是16位,每個位都是1。
初始化每個Segment。輸入引數initialCapacity是ConcurrentHashMap的初始化容量,loadfactor是每個segment的負載因子,在構造方法裡需要通過這兩個引數來初始化陣列中的每個segment。
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = 1;
while (cap < c)
cap <<= 1;
for (int i = 0; i < this.segments.length; ++i)
this.segments[i] = new Segment<K,V>(cap, loadFactor);
上面程式碼中的變數cap就是segment裡HashEntry陣列的長度,它等於initialCapacity除以ssize的倍數c,如果c大於1,就會取大於等於c的2的N次方值,所以cap不是1,就是2的N次方。segment的容量threshold=(int)cap*loadFactor,預設情況下initialCapacity等於16,loadfactor等於0.75,通過運算cap等於1,threshold等於零。
定位Segment
既然ConcurrentHashMap使用分段鎖Segment來保護不同段的資料,那麼在插入和獲取元素的時候,必須先通過雜湊演算法定位到Segment。可以看到ConcurrentHashMap會首先使用Wang/Jenkins hash的變種演算法對元素的hashCode進行一次再雜湊。
private static int hash(int h) {
h += (h << 15) ^ 0xffffcd7d; h ^= (h >>> 10);
h += (h << 3); h ^= (h >>> 6);
h += (h << 2) + (h << 14); return h ^ (h >>> 16);
}
再雜湊,其目的是為了減少雜湊衝突,使元素能夠均勻的分佈在不同的Segment上,從而提高容器的存取效率。假如雜湊的質量差到極點,那麼所有的元素都在一個Segment中,不僅存取元素緩慢,分段鎖也會失去意義。我做了一個測試,不通過再雜湊而直接執行雜湊計算。
System.out.println(Integer.parseInt("0001111", 2) & 15);
System.out.println(Integer.parseInt("0011111", 2) & 15);
System.out.println(Integer.parseInt("0111111", 2) & 15);
System.out.println(Integer.parseInt("1111111", 2) & 15);
計算後輸出的雜湊值全是15,通過這個例子可以發現如果不進行再雜湊,雜湊衝突會非常嚴重,因為只要低位一樣,無論高位是什麼數,其雜湊值總是一樣。我們再把上面的二進位制資料進行再雜湊後結果如下,為了方便閱讀,不足32位的高位補了0,每隔四位用豎線分割下。
0100|0111|0110|0111|1101|1010|0100|1110 1111|0111|0100|0011|0000|0001|1011|1000 0111|0111|0110|1001|0100|0110|0011|1110 1000|0011|0000|0000|1100|1000|0001|1010
可以發現每一位的資料都雜湊開了,通過這種再雜湊能讓數字的每一位都能參加到雜湊運算當中,從而減少雜湊衝突。ConcurrentHashMap通過以下雜湊演算法定位segment。
預設情況下segmentShift為28,segmentMask為15,再雜湊後的數最大是32位二進位制資料,向右無符號移動28位,意思是讓高4位參與到hash運算中, (hash >>> segmentShift) & segmentMask的運算結果分別是4,15,7和8,可以看到hash值沒有發生衝突。
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
ConcurrentHashMap的get操作
Segment的get操作實現非常簡單和高效。先經過一次再雜湊,然後使用這個雜湊值通過雜湊運算定位到segment,再通過雜湊演算法定位到元素,程式碼如下:
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}
get操作的高效之處在於整個get過程不需要加鎖,除非讀到的值是空的才會加鎖重讀,我們知道HashTable容器的get方法是需要加鎖的,那麼ConcurrentHashMap的get操作是如何做到不加鎖的呢?原因是它的get方法裡將要使用的共享變數都定義成volatile,如用於統計當前Segement大小的count欄位和用於儲存值的HashEntry的value。定義成volatile的變數,能夠線上程之間保持可見性,能夠被多執行緒同時讀,並且保證不會讀到過期的值,但是隻能被單執行緒寫(有一種情況可以被多執行緒寫,就是寫入的值不依賴於原值),在get操作裡只需要讀不需要寫共享變數count和value,所以可以不用加鎖。之所以不會讀到過期的值,是根據java記憶體模型的happen before原則,對volatile欄位的寫入操作先於讀操作,即使兩個執行緒同時修改和獲取volatile變數,get操作也能拿到最新的值,這是用volatile替換鎖的經典應用場景。
transient volatile int count; volatile V value;
在定位元素的程式碼裡我們可以發現定位HashEntry和定位Segment的雜湊演算法雖然一樣,都與陣列的長度減去一相與,但是相與的值不一樣,定位Segment使用的是元素的hashcode通過再雜湊後得到的值的高位,而定位HashEntry直接使用的是再雜湊後的值。其目的是避免兩次雜湊後的值一樣,導致元素雖然在Segment裡雜湊開了,但是卻沒有在HashEntry裡雜湊開。
hash >>> segmentShift) & segmentMask//定位Segment所使用的hash演算法 int index = hash & (tab.length - 1);// 定位HashEntry所使用的hash演算法
ConcurrentHashMap的Put操作
由於put方法裡需要對共享變數進行寫入操作,所以為了執行緒安全,在操作共享變數時必須得加鎖。Put方法首先定位到Segment,然後在Segment裡進行插入操作。插入操作需要經歷兩個步驟,第一步判斷是否需要對Segment裡的HashEntry陣列進行擴容,第二步定位新增元素的位置然後放在HashEntry數組裡。
是否需要擴容。在插入元素前會先判斷Segment裡的HashEntry陣列是否超過容量(threshold),如果超過閥值,陣列進行擴容。值得一提的是,Segment的擴容判斷比HashMap更恰當,因為HashMap是在插入元素後判斷元素是否已經到達容量的,如果到達了就進行擴容,但是很有可能擴容之後沒有新元素插入,這時HashMap就進行了一次無效的擴容。
如何擴容。擴容的時候首先會建立一個兩倍於原容量的陣列,然後將原數組裡的元素進行再hash後插入到新的數組裡。為了高效ConcurrentHashMap不會對整個容器進行擴容,而只對某個segment進行擴容。
ConcurrentHashMap的size操作
如果我們要統計整個ConcurrentHashMap裡元素的大小,就必須統計所有Segment裡元素的大小後求和。Segment裡的全域性變數count是一個volatile變數,那麼在多執行緒場景下,我們是不是直接把所有Segment的count相加就可以得到整個ConcurrentHashMap大小了呢?不是的,雖然相加時可以獲取每個Segment的count的最新值,但是拿到之後可能累加前使用的count發生了變化,那麼統計結果就不準了。所以最安全的做法,是在統計size的時候把所有Segment的put,remove和clean方法全部鎖住,但是這種做法顯然非常低效。
因為在累加count操作過程中,之前累加過的count發生變化的機率非常小,所以ConcurrentHashMap的做法是先嚐試2次通過不鎖住Segment的方式來統計各個Segment大小,如果統計的過程中,容器的count發生了變化,則再採用加鎖的方式來統計所有Segment的大小。
那麼ConcurrentHashMap是如何判斷在統計的時候容器是否發生了變化呢?使用modCount變數,在put , remove和clean方法裡操作元素前都會將變數modCount進行加1,那麼在統計size前後比較modCount是否發生變化,從而得知容器的大小是否發生變化。
參考資料

