
深入理解並行程式設計-分割和同步設計(四)
原文連結 作者:paul 譯者:謝寶友,魯陽,陳渝
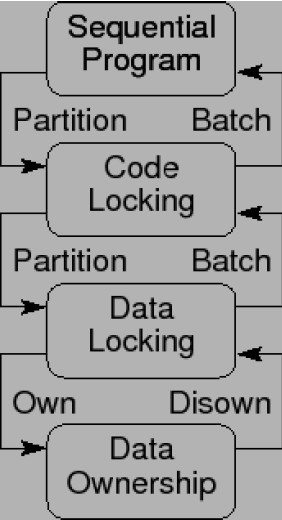
圖1.1:設計模式與鎖粒度
圖1.1是不同程度同步粒度的圖形表示。每一種同步粒度都用一節內容來描述。下面幾節主要關注鎖,不過其他幾種同步方式也有類似的粒度問題。
1.1. 序列程式
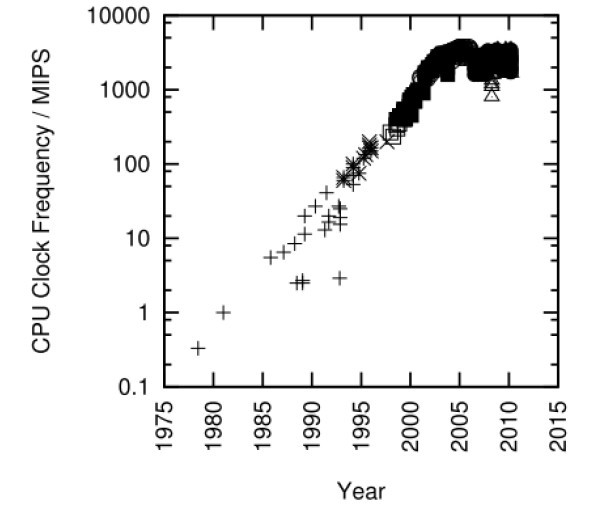
圖1.2:Intel處理器的MIPS/時鐘頻率變化趨勢
如果程式在單處理器上執行的足夠快,並且不與其他程序、執行緒或者中斷處理程式發生互動,那麼您可以將程式碼中所有的同步原語刪掉,遠離它們所帶來的開銷和複雜性。好多年前曾有人爭論摩爾定律最終會讓所有程式都變得如此。但是,隨著2003年以來Intel CPU的CPU MIPS和時鐘頻率增長速度的停止,見圖1.2,此後要增加效能,就必須提高程式的並行化程度。關於是否這種趨勢會導致一塊晶片上整合幾千個CPU的爭論不會很快停息,但是考慮到Paul是在一臺雙核筆記本上敲下這句話的,SMP的壽命極有可能比你我都長。另一個需要注意的地方是乙太網的頻寬持續增長,如圖1.3所示。這種增長會導致多執行緒伺服器的產生,這樣才能有效處理通訊載荷。
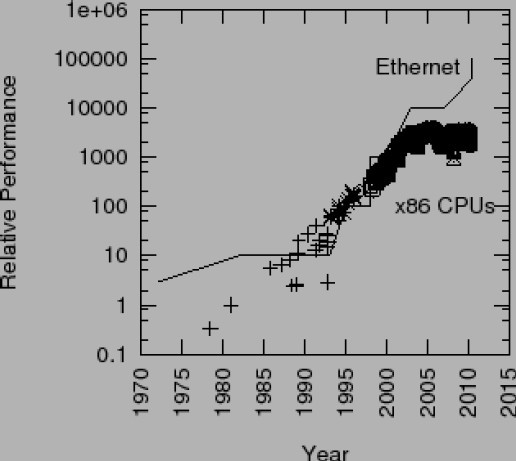
圖1.3:乙太網頻寬 v.s. Intel x86處理器的效能
請注意,這並不意味這您應該在每個程式中使用多執行緒方式程式設計。我再一次說明,如果一個程式在單處理器上執行的很好,那麼您就從SMP同步原語的開銷和複雜性中解脫出來吧。圖1.4中雜湊表查詢程式碼的簡單之美強調了這一點。
struct hash_table
{
long nbuckets;
struct node **buckets;
};
typedef struct node {
unsigned long key;
struct node *next;
} node_t;
int hash_search(struct hash_table *h, long key)
{
struct node *cur;
cur = h->buckets[key % h->nbuckets];
while (cur != NULL) {
if (cur->key >= key) {
return (cur->key == key);
}
cur = cur->next;
}
return 0;
}
圖1.4:序列版的雜湊表搜尋演算法
1.2. 程式碼鎖
程式碼鎖是最簡單的設計,只使用全域性鎖。在已有的程式上使用程式碼鎖,可以很容易的讓程式可以在多處理器上執行。如果程式只有一個共享資源,那麼程式碼鎖的效能是最優的。但是,許多較大且複雜的程式會在臨界區上執行許多次,這就讓程式碼鎖的擴充套件性大大受限。
spinlock_t hash_lock;
struct hash_table
{
long nbuckets;
struct node **buckets;
};
typedef struct node {
unsigned long key;
struct node *next;
} node_t;
int hash_search(struct hash_table *h, long key)
{
struct node *cur;
int retval;
spin_lock(&hash_lock);
cur = h->buckets[key % h->nbuckets];
while (cur != NULL) {
if (cur->key >= key) {
retval = (cur->key == key);
spin_unlock(&hash_lock);
return retval;
}
cur = cur->next;
}
spin_unlock(&hash_lock);
return 0;
}
圖1.5:基於程式碼鎖的雜湊表搜尋演算法
因此,您最好在只有一小段執行時間在臨界區程式,或者對擴充套件性要求不高的程式上使用程式碼鎖。這種情況下,程式碼鎖可以讓程式相對簡單,和單執行緒版本類似,如圖1.5所示。但是,和圖1.4相比,hash_search()從簡單的一行return變成了3行語句,因為在返回前需要釋放鎖。

圖1.6:鎖競爭
並且,程式碼鎖尤其容易引起“鎖競爭”,一種多個CPU併發訪問同一把鎖的情況。照顧一群小孩子(或者像小孩子一樣的老人)的SMP程式設計師肯定能馬上意識到某樣東西只有一個的危險,如圖1.6所示。
該問題的一種解決辦法是下節描述的“資料鎖”。
1.3. 資料鎖
struct hash_table
{
long nbuckets;
struct bucket **buckets;
};
struct bucket {
spinlock_t bucket_lock;
node_t *list_head;
};
typedef struct node {
unsigned long key;
struct node *next;
} node_t;
int hash_search(struct hash_table *h, long key)
{
struct bucket *bp;
struct node *cur;
int retval;
bp = h->buckets[key % h->nbuckets];
spin_lock(&bp->bucket_lock);
cur = bp->list_head;
while (cur != NULL) {
if (cur->key >= key) {
retval = (cur->key == key);
spin_unlock(&bp->hash_lock);
return retval;
}
cur = cur->next;
}
spin_unlock(&bp->hash_lock);
return 0;
}
圖1.7:基於資料鎖的雜湊表搜尋演算法
許多資料結構都可以分割,資料結構的每個部分帶有一把自己的鎖。這樣雖然每個部分一次只能執行一個臨界區,但是資料結構的各個部分形成的臨界區就可以並行執行了。在鎖競爭必須降低時,和同步開銷不是主要侷限時,可以使用資料鎖。資料鎖通過將一塊過大的臨界區分散到各個小的臨界區來減少鎖競爭,比如,維護雜湊表中的per-hash-bucket臨界區,如圖1.7所示。不過這種擴充套件性的增強帶來的是複雜性的提高,增加了額外的資料結構struct bucket。

圖1.8:資料鎖
和圖1.6中所示的緊張局面不同,資料鎖帶來了和諧,見圖1.8——在並行程式中,這總是意味著效能和可擴充套件性的提升。基於這種原因,Sequent在它的DYNIX和DYNIX/ptx作業系統中大量使用了資料鎖[BK85][Inm85][Gar90][Dov90][MD92][MG92][MS93]。
不過,那些照顧過小孩子的人可以證明,再細心的照料也不能保證一切風平浪靜。同樣的情況也適用於SMP程式。比如,Linux核心維護了一種檔案和目錄的快取(叫做“dcache”)。該快取中的每個條目都有一把自己的鎖,但是對應根目錄的條目和它的直接後代相較於其他條目更容易被遍歷到。這將導致許多CPU競爭這些熱門條目的鎖,就像圖1.9中所示的情景。

圖1.9:資料鎖出現問題
在許多情況下,可以設計演算法來減少資料衝突的次數,某些情況下甚至可以完全消滅衝突(像Linux核心中的dcache一樣[MSS04])。資料鎖通常用於分割像雜湊表一樣的資料結構,也適用於每個條目用某個資料結構的例項表示這種情況。2.6.17核心的task list就是後者的例子,每個任務結構都有一把自己的proc_lock鎖。
在動態分配結構中,資料鎖的關鍵挑戰是如何保證在已經獲取鎖的情況下結構本身是否存在。圖1.7中的程式碼通過將鎖放入靜態分配並且永不釋放的雜湊桶,解決了上述挑戰。但是,這種手法不適用於雜湊表大小可變的情況,所以鎖也需要動態分配。在這種情況,還需要一些手段來阻止雜湊桶在鎖被獲取後這段時間內釋放。
小問題1.1:當結構的鎖被獲取時,如何防止結構被釋放呢?
1.4. 資料所有權
資料所有權方法按照執行緒或者CPU的個數分割資料結構,這樣每個執行緒/CPU都可以在不需任何同步開銷的情況下訪問屬於它的子集。但是如果執行緒A希望訪問另一個執行緒B的資料,那麼執行緒A是無法直接做到這一點的。取而代之的是,執行緒A需要先與執行緒B通訊,這樣執行緒B以執行緒A的名義執行操作,或者,另一種方法,將資料遷移到執行緒A上來。
資料所有權看起來很神祕,但是卻應用得十分頻繁。
1. 任何只能被一個CPU或者一個執行緒訪問的變數(C或者C++中的auto變數)都屬於這個CPU或者這個程序。
2. 使用者介面的例項擁有對應的使用者上下文。這在與並行資料庫引擎互動的應用程式中十分常見,這讓並行引擎看起來就像順序程式一樣。這樣的應用程式擁有使用者介面和他當前的操作。顯式的並行化只在資料庫引擎內部可見。
3. 引數模擬通常授予每個執行緒一段特定的引數區間,以此達到某種程度的並行化。
如果共享比較多,執行緒或者CPU間的通訊會帶來較大的複雜性和通訊開銷。不僅如此,如果使用的最多的資料正好被一個CPU擁有,那麼這個CPU就成為了“熱點”,有時就會導致圖1.9中的類似情況。不過,在不需要共享的情況下,資料所有權可以達到理想效能,程式碼也可以像圖1.4中所示的順序程式例子一樣簡單。最壞情況通常被稱為“尷尬的並行化”,而最好情況,則像圖1.8中所示一樣。
另一個數據所有權的重要例項發生在資料是隻讀時,這種情況下,所有執行緒可以通過複製來“擁有”資料。
1.5鎖粒度與效能
本節以一種數學上的同步效率的視角,將視線投向鎖粒度和效能。對數學不敢興趣的讀者可以跳過本節。
本節的方法是用一種關於同步機制效率的粗略佇列模型,該機制只操作一個共享的全域性變數,基於M/M/1佇列。M/M/1佇列。
(本節未翻譯)
…
