
從Java視角理解系統結構(二)CPU快取
從Java視角理解系統結構連載, 關注我的微博(連結)瞭解最新動態
眾所周知, CPU是計算機的大腦, 它負責執行程式的指令; 記憶體負責存資料, 包括程式自身資料. 同樣大家都知道, 記憶體比CPU慢很多. 其實在30年前, CPU的頻率和記憶體匯流排的頻率在同一個級別, 訪問記憶體只比訪問CPU暫存器慢一點兒. 由於記憶體的發展都到技術及成本的限制, 現在獲取記憶體中的一條資料大概需要200多個CPU週期(CPU cycles), 而CPU暫存器一般情況下1個CPU週期就夠了.
CPU快取
網頁瀏覽器為了加快速度,會在本機存快取以前瀏覽過的資料; 傳統資料庫或NoSQL資料庫為了加速查詢, 常在記憶體設定一個快取, 減少對磁碟(慢)的IO. 同樣記憶體與CPU的速度相差太遠, 於是CPU設計者們就給CPU加上了快取(CPU Cache). 如果你需要對同一批資料操作很多次, 那麼把資料放至離CPU更近的快取, 會給程式帶來很大的速度提升. 例如, 做一個迴圈計數, 把計數變數放到快取裡,就不用每次迴圈都往記憶體存取資料了. 下面是CPU Cache的簡單示意圖.
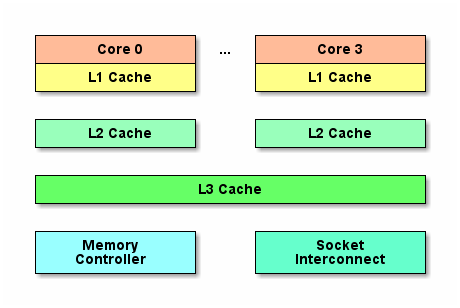
隨著多核的發展, CPU Cache分成了三個級別: L1, L2, L3. 級別越小越接近CPU, 所以速度也更快, 同時也代表著容量越小. L1是最接近CPU的, 它容量最小, 例如32K, 速度最快,每個核上都有一個L1 Cache(準確地說每個核上有兩個L1 Cache, 一個存資料 L1d Cache, 一個存指令 L1i Cache). L2 Cache 更大一些,例如256K, 速度要慢一些, 一般情況下每個核上都有一個獨立的L2 Cache; L3 Cache是三級快取中最大的一級,例如12MB,同時也是最慢的一級, 在同一個CPU插槽之間的核共享一個L3 Cache.
| 從CPU到 | 大約需要的CPU週期 | 大約需要的時間(單位ns) |
| 暫存器 | 1 cycle | |
| L1 Cache | ~3-4 cycles | ~0.5-1 ns |
| L2 Cache | ~10-20 cycles | ~3-7 ns |
| L3 Cache | ~40-45 cycles | ~15 ns |
| 跨槽傳輸 | ~20 ns | |
| 記憶體 | ~120-240 cycles | ~60-120ns |
感興趣的同學可以在Linux下面用cat /proc/cpuinfo, 或Ubuntu下lscpu看看自己機器的快取情況, 更細的可以通過以下命令看看:
$ cat /sys/devices/system/cpu/cpu0/cache/index0/size 32K $ cat /sys/devices/system/cpu/cpu0/cache/index0/type Data $ cat /sys/devices/system/cpu/cpu0/cache/index0/level 1 $ cat /sys/devices/system/cpu/cpu3/cache/index3/level 3
就像資料庫cache一樣, 獲取資料時首先會在最快的cache中找資料, 如果沒有命中(Cache miss) 則往下一級找, 直到三層Cache都找不到,那隻要向記憶體要資料了. 一次次地未命中,代表取資料消耗的時間越長.
快取行(Cache line)
為了高效地存取快取, 不是簡單隨意地將單條資料寫入快取的. 快取是由快取行組成的, 典型的一行是64位元組. 讀者可以通過下面的shell命令,檢視cherency_line_size就知道知道機器的快取行是多大.
$ cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size 64
CPU存取快取都是按行為最小單位操作的. 在這兒我將不提及快取的associativity問題, 將問題簡化一些. 一個Java long型佔8位元組, 所以從一條快取行上你可以獲取到8個long型變數. 所以如果你訪問一個long型陣列, 當有一個long被載入到cache中, 你將無消耗地載入了另外7個. 所以你可以非常快地遍歷陣列.
實驗及分析
我們在Java程式設計時, 如果不注意CPU Cache, 那麼將導致程式效率低下. 例如以下程式, 有一個二維long型陣列, 在我的32位筆記本上執行時的記憶體分佈如圖:
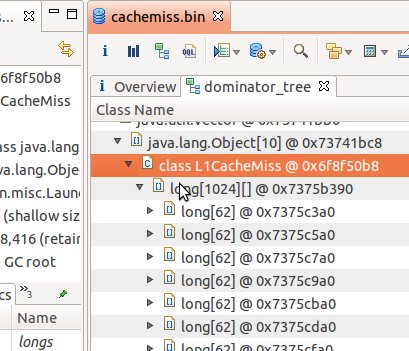
32位機器中的java的陣列物件頭共佔16位元組(詳情見 連結), 加上62個long型一行long資料一共佔512位元組. 所以這個二維資料是順序排列的.
public class L1CacheMiss {
private static final int RUNS = 10;
private static final int DIMENSION_1 = 1024 * 1024;
private static final int DIMENSION_2 = 62;
private static long[][] longs;
public static void main(String[] args) throws Exception {
Thread.sleep(10000);
longs = new long[DIMENSION_1][];
for (int i = 0; i < DIMENSION_1; i++) {
longs[i] = new long[DIMENSION_2];
for (int j = 0; j < DIMENSION_2; j++) {
longs[i][j] = 0L;
}
}
System.out.println("starting....");
final long start = System.nanoTime();
long sum = 0L;
for (int r = 0; r < RUNS; r++) {
// for (int j = 0; j < DIMENSION_2; j++) {
// for (int i = 0; i < DIMENSION_1; i++) {
// sum += longs[i][j];
// }
// }
for (int i = 0; i < DIMENSION_1; i++) {
for (int j = 0; j < DIMENSION_2; j++) {
sum += longs[i][j];
}
}
}
System.out.println("duration = " + (System.nanoTime() - start));
}
}
編譯後執行,結果如下
$ java L1CacheMiss starting.... duration = 1460583903
然後我們將22-26行的註釋取消, 將28-32行註釋, 編譯後再次執行,結果是不是比我們預想得還糟?
$ java L1CacheMiss starting.... duration = 22332686898
前面只花了1.4秒的程式, 只做一行的對調要執行22秒. 從上節我們可以知道在載入longs[i][j]時, longs[i][j+1]很可能也會被載入至cache中, 所以立即訪問longs[i][j+1]將會命中L1 Cache, 而如果你訪問longs[i+1][j]情況就不一樣了, 這時候很可能會產生 cache miss導致效率低下.
下面我們用perf來驗證一下,先將快的程式跑一下.
$ perf stat -e L1-dcache-load-misses java L1CacheMiss starting.... duration = 1463011588 Performance counter stats for 'java L1CacheMiss': 164,625,965 L1-dcache-load-misses 13.273572184 seconds time elapsed
一共164,625,965次L1 cache miss, 再看看慢的程式
$ perf stat -e L1-dcache-load-misses java L1CacheMiss starting.... duration = 21095062165 Performance counter stats for 'java L1CacheMiss': 1,421,402,322 L1-dcache-load-misses 32.894789436 seconds time elapsed
這回產生了1,421,402,322次 L1-dcache-load-misses, 所以慢多了.
以上我只是示例了在L1 Cache滿了之後才會發生的cache miss. 其實cache miss的原因有下面三種:
1. 第一次訪問資料, 在cache中根本不存在這條資料, 所以cache miss, 可以通過prefetch解決.
2. cache衝突, 需要通過補齊來解決.
3. 就是我示例的這種, cache滿, 一般情況下我們需要減少操作的資料大小, 儘量按資料的物理順序訪問資料.
具體的資訊可以參考這篇論文.

 周忱。阿里巴巴技術專家,曾經負責淘寶Hadoop,Hive研發, Hive Contributor, 目前在做分散式實時計算
周忱。阿里巴巴技術專家,曾經負責淘寶Hadoop,Hive研發, Hive Contributor, 目前在做分散式實時計算