
Nginx監控運維
Nginx 特性
作為 Web 伺服器,Nginx 不免要與 Apache 進行比較。
相比 Apache 伺服器,Nginx 因其採用的非同步非阻塞工作模型,使其具備高併發、低資源消耗的特性,高度模組化設計使 Nginx 具備很好的擴充套件性;在處理靜態檔案、反向代理請求等方面,Nginx 表現出很大的優勢。
Nginx 常見的使用方式
Nginx 可以作為反向代理伺服器來轉發使用者請求;並能夠在處理請求的過程中實現後端例項負載均衡,實現分發請求的功能;也可將 Nginx 配置為本地靜態伺服器,處理靜態請求。
Nginx 監控
監控指標梳理
Nginx 處理請求的全過程應被監控起來,以便我們及時發現服務是否能夠正常運轉。
Nginx 處理請求的過程被詳細地記錄在 access.log 以及 error.log 檔案中,我們給出以下(表 1)需要監控的關鍵指標:

表1:關鍵指標
監控實踐
下面從延遲、錯誤、流量以及飽和度四個指標對 Nginx 監控實踐進行說明。
延遲監控
延遲監控主要關注對 $request_time 的監控,並繪製 TP 指標圖,來確認 TP99 指標值。
另外,我們還可以增加對 $upstream_response_time 指標的監控,來輔助定位延遲問題的原因。

圖 1:TP 指標
圖 1 展示了過去 15min 內 Nginx 處理使用者請求的時間,可以看出使用者 90% 的請求可以在 0.1s 內處理完成,99% 的請求可以在 0.3s 內完成。
根據 TP 指標值,並結合具體業務對延遲的容忍度,來設定延遲的報警閾值。
錯誤監控
Nginx 作為 Web 伺服器,不但要對 Nginx 本身執行狀態進行監控,還必須對 Nginx 的各類錯誤響應進行監控,HTTP 錯誤狀態碼以及 error.log 中記錄的錯誤詳細日誌都應被監控起來以協助解決問題。
①基於 HTTP 語義的 Nginx 埠監控
單純的 Nginx 埠監控無法反映服務真實執行狀態,我們要關注的是 Nginx 本身存活以及是否可以正常提供服務。
基於我們的實踐,我們推薦用語義監控代替埠監控,即從 Nginx 本機以 http://local_ip:port/ 的方式進行訪問,校驗返回的資料格式、內容及 HTTP 狀態碼是否符合預期。
②錯誤碼監控
必須新增對諸如 500/502/504 等 5xx 服務類錯誤狀態碼的監控,它們告訴我們服務本身出現了問題。

圖 2:狀態碼監控
5xx 類錯誤每分鐘出現的頻率應該在個位數,太多的 5xx 應及時排查問題並解決;4xx 類錯誤,在協助解決一些非預期的許可權錯誤、資源丟失或效能等問題上可以給予幫助。
可以選擇性得對 301/302 重定向類監控,應對特殊配置跳轉的監控,如後端伺服器返回 5xx 後,Nginx 配置重定向跳轉並返回跳轉後的請求結果。
③對錯誤日誌監控
Nginx 內部實現了對請求處理錯誤的詳細記錄,並儲存在 error.log 檔案中。
錯誤型別有很多種,我們主要針對關鍵的、能體現服務端異常的錯誤進行採集並監控,以協助我們進行故障定位:

表 2:錯誤日誌資訊
流量監控
①Nginx 所接受請求總量的監控
關注流量波動週期,並捕獲流量突增、突降的情況;通常穩態下流量低峰和高峰浮動 20% 需要關注下原因。
對於有明顯波動週期的服務,我們也可以採用同環比增漲/降低的告警策略,來及時發現流量的變化。

圖 3:PV 流量圖

圖 4:關鍵流量圖
圖 3 為京東雲某平臺一週內的流量波動圖,流量存在明顯低峰和高峰並有天級別的週期性。
基於網站執行特性,根據低峰、高峰的值來監控網站流量的波動,並通過自身的監控儀表盤配置網站關鍵頁面的流量圖(圖 4),以協助故障排查。

圖 5:網絡卡流量圖
②對網絡卡 IO 等機器級別流量進行監控
可以及時發現伺服器硬體負載的壓力,當 Nginx 被用於搭建檔案伺服器時,此監控指標需要我們尤為關注。
飽和度監控
Google SRE 中提到,飽和度應關注服務對資源的利用率以及服務在當前執行情況下還可以承受多少負載。
Nginx 是低資源消耗的高效能伺服器,但諸如在電商場景下,新產品搶購會在短時間內造成 CPU 利用率、請求連線數、磁碟寫入的飆升。
CPU 利用率還要考慮通過 worker_cpu_affinity 繫結 Worker 程序到特定 CPU 核心的使用情況,處理高流量時,該配置可以減少 CPU 切換的效能損耗。
Nginx 可以接受的最大連線數在配置檔案 nginx.conf 中由 worker_processes 和 worker_connections 兩個引數的乘積決定。

圖 6
通過 Nginx 自帶的模組 http_stub_status_module 可以對 Nginx 的實時執行資訊(圖 6)進行監控。
因我們更關心當前 Nginx 執行情況,不對已處理的請求做過多關注,所以我們只對如下指標進行採集監控:

表 3:指標含義
基於開源軟體搭建 Nginx 視覺化監控系統
①採用 Elasticsearch+Logstash+Kibana 搭建視覺化日誌監控

圖 7:ELK 棧架構圖
針對以上四個監控黃金指標,搭建的 ELK 棧儀表盤,設定常用的 Nginx 日誌過濾規則(圖 8),以便可以快速定位分析問題。

圖 8:ELK 儀表盤
②採用 Kibana+Elasticsearch+Rsyslog+Grafana 搭建視覺化日誌監控
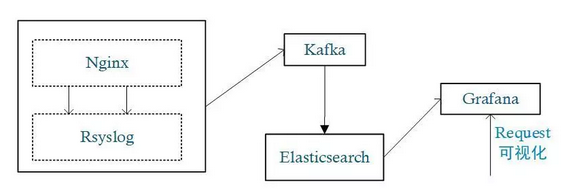
圖 9:Grafana 視覺化架構圖
相較於 Kibana 能快速地對日誌進行檢索,Grafana 則在資料展示方面體現了更多的靈活性,某些情況下二者可以形成互補。

圖 10:Grafana 儀表盤
我們在實踐中實現上述兩種架構的 Nginx 日誌視覺化監控;從需求本身來講,ELK 棧模型可以提供實時的日誌檢索,各種日誌規則的過濾和資料展示,基本可以滿足 Nginx 日誌監控的需求。
Grafana 架構模型無法進行日誌檢索和瀏覽,但提供了角色許可權的功能,來防護一些敏感資料的訪問。
另外,Grafana 更為豐富的圖表型別和資料來源支援,使其具有更多的應用場景。
基於 Nginx 監控發現並定位問題案例
案例 1:大流量衝擊
問題:某平臺,進行了一次新產品的搶購活動。活動期間因流量飆升導致商品詳情頁、下單等核心功能處理耗時增加的情況。
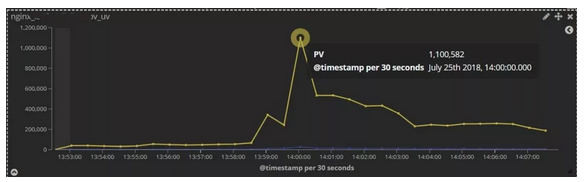
圖 11:PV 飆升圖
解決:訂單監控及 Nginx 的 PV、請求時間等監控指標發出報警後,運維人員迅速通過自建的 ELK 監控儀表盤,關注網站流量變化,檢視使用者請求 top IP、top URL;發現存在大量黃牛的惡意搶購行為,導致服務後端處理延時。
因此,我們通過降低高防產品、Nginx 限流配置中相關介面防攻擊閾值,及時攔截了對系統負載造成壓力的刷單行為,保障了新品促銷活動順利開展。
案例 2:Nginx 錯誤狀態碼警示服務異常
問題:某平臺進行後端伺服器調整,某個 Nginx 的 upstream 指向的後端伺服器配置錯誤,指向了一個非預期的後端服務。
當錯誤的配置被髮布到線上後,網站開始出現概率性的異常,並伴有 500 和 302 錯誤狀態碼數量的飆升。

圖 12:302 錯誤碼統計
解決:Nginx 錯誤狀態碼告警後,通過 ELK 平臺過濾 302 錯誤碼下使用者請求的 URL,發現請求錯誤的 URL 均與後端的某個模組相關,該請求都被重定向到了網站首頁。
進一步定位發現,某臺 Nginx 指向了錯誤的後端伺服器,導致伺服器返回大量 500 錯誤,但因 Nginx 配置中對 500 錯誤做了重定向,並因此產生了很多 302 狀態碼。

圖 13:配置 upstream 健康監測
在後續改進中,我們通過升級 Nginx,採用 openresty+lua 方式來對後端伺服器進行健康監測(圖 13),以動態更新 upstream 中的 server,可以快速摘除異常的後端伺服器,達到快速止損的目的。
案例 3:Nginx 伺服器磁碟空間耗盡導致服務異常
問題:Nginx 作為圖片伺服器前端,某天其中一例項在生產環境無任何變更的情況下收到報警提示:500 狀態碼在整體流量中佔比過高。
解決:快速將此機器從生產環境中摘除,不再提供服務,經排查 Nginx 錯誤日誌發現如下報錯:
open() "/home/work/upload/client_body_temp/0000030704" failed (28: No space left on device)
Nginx 處理請求時,會將客戶端 POST 長度超過 client_body_buffer_size 請求的部分或者全部內容暫存到 client_body_temp_path 目錄,當磁碟空間被佔滿時,產生了以上的報錯。
最終,我們確認了本次異常是產品升級後支援上傳的圖片大小由 15MB 改為 50MB,並且運營方進行了新產品推廣活動,使用者上傳圖片量激增快速打滿磁碟空間所致。