
百億資料入庫elasticsearch生產實踐(二)
一、前言
前情回顧,hive中有三個具有關聯關係的表,依次是一對多的關係,當前歷史資料總量在500億左右,每日增量依次是百萬、千萬、億級的體量。其中,這500億資料只是一個領域,還有另一個塊更大領域的資料第三層日增量在10~25億之間,這塊還沒來得及去啃。這一塊資料,需要對多個業務部門提供資料服務,主要是資料聚合處理和歷史明細查詢。明細查詢這一塊由於查詢條件、範圍的不確定性,需要構建一個層級的全量表提供快速檢索查詢。在mongo的實踐中,我們的瓶頸主要是海量資料高頻次的update操作,導致mongodb承受不了這個壓力。這次我們改用elasticsearch。yes, for search!
二、elasticsearch初遇
2.1 在瞭解elasticsearch之前,我們需要先了解下下面幾點概念。
全文檢索:一種將檔案中所有文字與檢索項匹配的檢索方法。它可以根據需要獲得全文中有關章、節、段、句、詞等資訊。計算機程式通過掃描文章中的每一個詞,對每一個詞建立一個索引,指明該詞在文章中出現的次數和位置,當用戶查詢時根據建立的索引查詢,類似於通過字典的檢索字表查字的過程。經過幾年的發展,全文檢索從最初的字串匹配程式已經演進到能對超大文字、語音、影象、活動影像等非結構化資料進行綜合管理的大型軟體。
全文檢索與資料庫like查詢的區別:資料查詢通常的做法是是通過資料庫模糊匹配即Like '%keyword%'
lucene:最初是由Doug cutting,沒錯,就是那個開發出hadoop的人。lucene是apache下的一個開源全文檢索引擎工具包,提供了完整的查詢引擎和索引引擎。它提供了文件索引、查詢和儲存等多種api,可供開發人員整合到wen專案、搜尋引擎等多種應用場景中。
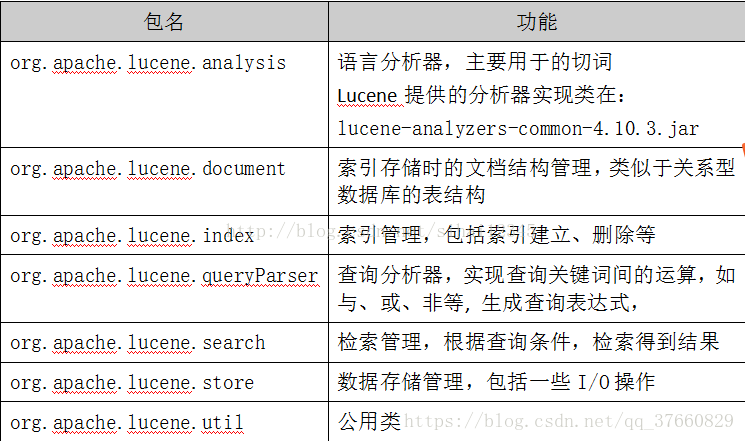
lucene主要包結構:
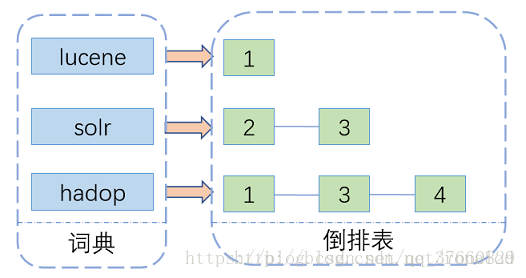
lucene索引的原理:基於倒排索引來實現,主要包含兩部分--詞典和倒排表。
假如現在有一篇文章,一般我們可能會考慮這篇文章裡頭包含了哪些詞哪些關鍵字。而倒排索引則是反著推,有一個關鍵詞,它是在文中哪個位置,出現的次數是多少。然後詞(term)的的集合就形成了詞典,而記錄詞的位置和頻率的資訊就是一個倒排連結串列。如果我們需要索引一篇文章用於後面的關鍵詞檢索,我們需要先對文章進行分詞,形成如圖左邊的單個單詞,在倒排表裡記錄在文中出現的位置,和次數。所有詞(term)處理完後,會對詞典進行排序去重,相應的記錄詞頻的倒排表也會進行整合得到所有的出現位置和一個總頻次。以上是一個簡單的理解,想深入理解下lucene的索引原理,可以參考一下這篇關於lucene底層原理的博文。
2.2 elsticsearch
一系列鋪墊之後,我們瞭解了全文檢索的概念和lucene索引的原理。那elasticsearch是什麼呢?其實主要是基於lucene的一個搜尋伺服器,是一個分散式的檢索引擎,對lucene進行進一步的封裝和更能增強。elasticsearch提供了一個對海量資料檢索的解決方案,大大降低了使用門檻。
使用elasticsearch首先要先建立一個索引,索引類似於資料庫,可以向索引中寫入資料和讀取資料。一個索引可以包含多種型別,每種型別可以建議不同的文件mapping。es還支援分片處理,用於資料負載均衡和分散式查詢。這裡的每一個分片其實就是一個lucene索引,如果查詢時能帶著路由條件查詢將精準命中對應分片,減少無關分片的掃描,大大提供查詢效率和減少查詢效能消耗。更多關於索引、型別、對映、分片、副本等詳細資訊描述更參考這篇博文。
2.3 elsticsearch使用
2.3.1 安裝
參考官方文件進行安裝:https://www.elastic.co/guide/en/elasticsearch/reference/5.4/gs-installation.html
我這裡選擇的是5.3.0版的tar包方式安裝,使用預設配置啟動單節點,正常啟動如下:
安裝並啟動kibana用於介面化操作,配置引數主要更改監聽elasticsearch的http服務埠:

啟動後可選擇 dev tools選項,在console進行dsl操作。

elasticsearch提供的操作api很豐富,常用的主要有操作文件的document api、查詢 api、操作索引的api、查詢常規配置和資訊的api和叢集狀態管理的api。
es基本操作可參考以上幾個api去練手。
三、進入主題--實踐環節
3.1 資料模型構建
按照構建層級結構文件的指導思想,我首先研究在es中如何去實現這個資料模型。這裡,可以推薦一個博主,他寫的文章在初期給了我不少指引。es作為一個nosql型別的資料庫,本身對關係的處理是比較弱的,後文的實踐也有所體現。但是事實資料肯定存在各種關係,關係資料描述中無非是一對一、一對多、多對多,而多對多又能轉化成一對多。由於es對json的完美支援,所以可以將資料間的關係以保準json表現出來,無論巢狀多少層,都能存到es裡。es中處理這種資料有三種方式:
3.1.1 使用object和array[object]進行儲存
這種模式其實使用的就是es的預設的mapping,底層自動做型別對映。這種方式處理起來方便,但是要先將資料的關係用json組織好再寫入。並且資料查詢的時候也有限制,資料檢索時,是整個文件返回,如果文件巢狀太深或者子文件太多而想獲取的只是某部分則佔用了無益的io。
插入資料:
{
"name" : "Zach",
"car" : [
{
"make" : "Saturn",
"model" : "SL"
},
{
"make" : "Subaru",
"model" : "Imprezza"
}
]
}底層儲存結構:
{
"name" : "Zach",
"car.make" : ["Saturn", "Subaru"]
"car.model" : ["SL", "Imprezza"]
}es的底層lucene是多值域儲存,所以上面看起來像陣列結構。檢索資料時,無法獲取單個的內層文件資訊,“Saturn”與“SL”已經沒有關係了。
3.1.2 使用nested[object]型別
要使上述每個汽車的資訊作為一個整體,可以將car對映成nested型別
PUT /my_index
{
"mappings": {
"user": {
"properties": { "car": {
"type": "nested",
"properties": {
"make": { "type": "string" },
"model": { "type": "string" }
}
}
}
}
}
}nested型別在查詢的時候可以單獨對子文件進行查詢,並且查詢效率也很好,因為巢狀文件與上一級文件在同一分片上,查詢時能同一路由進行定位。但是有一個很大的缺點,在子文件更新時需要對整個結構體進行重索引。巢狀文件數量越大,成本越高。同時,返回的文件也是整個文件,不能返回指定文件。
3.1.3 parent-child --父子關係文件
父子關係文件,除了最頂層的文件外,下一級的文件都要指定它的"_parent"屬性定位它的父級文件,第二級的路由預設為"_parent",第三級以後還要指定"_routing"以確定路由到哪個分片上儲存。es管理這種關係,會在每個shard的記憶體中維護一個關係表,檢索時,通過過濾器has_parent和has_child獲取關聯資料。這種模式下,子父文件是壓平儲存的,彼此相互獨立,可自由更新子文件。檢索時能獲取對應的子文件,但是查詢效率會比nested低。
結合資料應用場景和資料體量情況,選擇parent-child 方式能滿足要求。
3.2 歷史資料入庫
3.2.1 mapping構建
PUT /my_index
{
"mappings": {
"r1":{
"_all": {"enabled": false},
"properties": {
"filed1":{
"type":"keyword"
},
"filed2":{
"type":"keyword"
},
"filed3":{
"type":"text"
},
"filed4":{
"type":"text",
"index": false
},
"filed5":{
"type": "date"
}
}
},
"r2":{
"_all": {"enabled": false},
"_parent":{
"type": "r1"
},
"_routing": {
"required": true
},
"properties": {
"filed1":{
"type":"keyword"
},
"filed2":{
"type":"keyword"
},
"filed3":{
"type":"text"
},
"filed4":{
"type":"text",
"index": false
},
"filed5":{
"type": "date"
}
}
},"r3":{
"_all": {"enabled": false},
"_parent":{
"type": "r2"
},
"_routing": {
"required": true
},
"properties": {
"filed1":{
"type":"keyword"
},
"filed2":{
"type":"keyword"
},
"filed3":{
"type":"text"
},
"filed4":{
"type":"text",
"index": false
},
"filed5":{
"type": "date"
}
}
}
},
"settings": {
"number_of_shards": 5,
"number_of_replicas": 0,
"refresh_interval": -1
}
} 3.2.2 基於資料體量,利用spark進行快速入庫es進行索引。
package com.huawei.datalake.elasticsearch
import java.net.InetAddress
import java.sql.Timestamp
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.elasticsearch.client.transport.TransportClient
import org.elasticsearch.common.settings.Settings
import org.elasticsearch.common.transport.InetSocketTransportAddress
import org.elasticsearch.transport.client.PreBuiltTransportClient
import org.elasticsearch.common.xcontent.XContentFactory._
/**
* Created by zhang on 2018/7/5.
*/
object EsTest {
/* bulkwrite每次提交1024,單個EXECUTOR */
private val DefaultMaxBatchSize: Int = 1024
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("integration_to_es").setMaster(args(0))
val sc = new SparkContext(conf)
/**
* 資料來源模擬
*/
val r1 = R("123", "grandfather", "info1", "info1", new Timestamp(System.currentTimeMillis()), "r1")
val r2 = R("123456", "father", "123", "info2", new Timestamp(System.currentTimeMillis()), "r2")
val r3 = R("123456789", "child", "123456", "123", new Timestamp(System.currentTimeMillis()), "r3")
val rdd = sc.parallelize(Seq(r1, r2, r3))
save(rdd)
sc.stop()
}
//通過SPARK並行批量進行索引
def save(rdd: RDD[R]) = {
rdd.foreachPartition(partition=>{
val client = getClient()
partition.grouped(DefaultMaxBatchSize).foreach(batch=>{
val bulkRequest = client.prepareBulk()
batch.foreach(row=>{
try{
val xContentContext = jsonBuilder.startObject()
.field("filed1", row.filed1)
.field("filed2", row.filed2)
.field("filed3", row.filed3)
.field("filed4", row.filed4)
.field("filed5", row.filed5)
.endObject()
val style = row.style
style match {
case "r1" => bulkRequest.add(client.prepareIndex("my_index", "r1", row.filed1).setSource(xContentContext))
case "r2" => bulkRequest.add(client.prepareIndex("my_index", "r2", row.filed1).setParent(row.filed3).setSource(xContentContext))
case "r3" => bulkRequest.add(client.prepareIndex("my_index", "r3", row.filed1).setParent(row.filed3).setRouting(row.filed4).setSource(xContentContext))
case _ =>
}
}catch{
case e: Exception =>{
throw new Exception(e.getMessage)
}
}
})
val response = bulkRequest.execute().actionGet()
if(response.hasFailures){
println("=============="+response.buildFailureMessage())
}
})
if (client!=null) client.close()
})
}
//獲取客戶端
def getClient(): TransportClient = {
val settings = Settings.builder()
.put("transport.type", "netty3")//解決與SPARK中的netty版本不一致的問題
.put("http.type", "netty3").build()
// .put("cluster.name", "myClusterName")//叢集模式需要新增此引數
val client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("localhost"), 9300))
// .addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("host2"), 9300))
client
}
case class R(filed1: String, filed2: String, filed3: String, filed4: String, filed5: Timestamp, style: String)
}
在這裡遇到的問題主要是不同版本的依賴衝突問題,我這裡是由於spark1.6.1引用的netty版本與es的不一致,導致出錯。可參考程式碼裡的引數設定,將es引用的netty也改為netty3。
匯入完成後,在kibana中通過search api: GET my_index/_search查詢資料。(由於前面把refresh關閉裡,要先_flush才能看到資料)。
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "my_index",
"_type": "r1",
"_id": "123",
"_score": 1,
"_source": {
"filed1": "123",
"filed2": "grandfather",
"filed3": "info1",
"filed4": "info1",
"filed5": "2018-07-07T02:14:15.901Z"
}
},
{
"_index": "my_index",
"_type": "r2",
"_id": "123456",
"_score": 1,
"_routing": "123",
"_parent": "123",
"_source": {
"filed1": "123456",
"filed2": "father",
"filed3": "123",
"filed4": "info2",
"filed5": "2018-07-07T02:14:15.901Z"
}
},
{
"_index": "my_index",
"_type": "r3",
"_id": "123456789",
"_score": 1,
"_routing": "123",
"_parent": "123456",
"_source": {
"filed1": "123456789",
"filed2": "child",
"filed3": "123456",
"filed4": "123",
"filed5": "2018-07-07T02:14:15.901Z"
}
}
]
}
}查詢出的資料是壓平儲存的,父子關係通過_parent值進行連線。
3.3 父子關係關聯查詢
在實際查詢場景中,每一層可能都有查詢條件。同時,對於每層返回的欄位也有要求。
GET my_index/r1/_search
{
"_source": {
"includes": ["filed1","filed2","filed5"]
},
"query": {
"bool": {
"must": [
{"match": {
"filed1": "123"
}},
{
"has_child": {
"type": "r2",
"query": {
"bool": {
"must": [
{"match": {
"filed2": "father"
}},
{"has_child": {
"type": "r3",
"query": {
"bool": {
"must": [
{"range": {
"filed5": {
"gte": "2018-07-07T01:14:15.901Z",
"lte": "2018-07-07T03:14:15.901Z"
}
}}
]
}
},
"inner_hits":{
"_source":{
"includes":["filed1","filed2","filed3","filed4","filed5"]
}
}
}}
]
}
},
"inner_hits":{
"_source":{
"includes":["filed1","filed2","filed3","filed5"]
}
}
}
}
]
}
}
}result:
{
"took": 22,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1.9808292,
"hits": [
{
"_index": "my_index",
"_type": "r1",
"_id": "123",
"_score": 1.9808292,
"_source": {
"filed1": "123",
"filed2": "grandfather",
"filed5": "2018-07-07T02:14:15.901Z"
},
"inner_hits": {
"r2": {
"hits": {
"total": 1,
"max_score": 1.9808292,
"hits": [
{
"_type": "r2",
"_id": "123456",
"_score": 1.9808292,
"_routing": "123",
"_parent": "123",
"_source": {
"filed1": "123456",
"filed2": "father",
"filed3": "123",
"filed5": "2018-07-07T02:14:15.901Z"
},
"inner_hits": {
"r3": {
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_type": "r3",
"_id": "123456789",
"_score": 1,
"_routing": "123",
"_parent": "123456",
"_source": {
"filed1": "123456789",
"filed2": "child",
"filed3": "123456",
"filed4": "123",
"filed5": "2018-07-07T02:14:15.901Z"
}
}
]
}
}
}
}
]
}
}
}
}
]
}
}這裡對子文件的獲取主要用了"inner_hits",可以對has_child中的子文件的欄位取出來。
關聯查詢在資料量少的時候問題不是很大,但是隨著資料量的增長,達到百億級,查詢直接無響應。多代文件的聯合查詢(檢視 祖輩與孫輩關係)雖然看起來很吸引人,但必須考慮如下的代價:
- 聯合越多,效能越差。
- 每一代的父文件都要將其字串型別的
_id欄位儲存在記憶體中,這會佔用大量記憶體。
當你考慮父子關係是否適合你現有關係模型時,請考慮下面這些建議 :
- 儘量少地使用父子關係,僅在子文件遠多於父文件時使用。
- 避免在一個查詢中使用多個父子聯合語句。
- 在 has_child 查詢中使用 filter 上下文,或者設定 score_mode 為 none 來避免計算文件得分。
- 保證父 IDs 儘量短,以便在 doc values 中更好地壓縮,被臨時載入時佔用更少的記憶體。
3.4 優化
3.4.1 索引優化
驢之所以倔,是因為它不知變通。
樹挪死,人挪活。關聯處理不了,我把幾個表分開索引了。分開索引,檢索時分別查詢也能一定程度上滿足業務需求,只是單次查詢量有上限。這是查詢效率與查詢量的取捨。分開索引後有兩條重要的原則:
(1)shard數建議為叢集節點數的1.5到3倍之間
(2)每個分片資料量應在30gb到50gb為宜
按照這個原則,對每個單表資料也需要分索引。這裡需要引入index api的另一個功能,索引模版。可以預先建立一個模版,模版可定義索引的萬用字元和對應mapping和settings。動態建立索引時,如果索引名匹配了該模版定義的索引命名規則,則引用模版預設的引數設定。模版可基於型別和基於時間進行匹配,比較通用的一個例子是:logstash整合日誌到es中,可根據"logstash-*"去匹配"logstash-2018-07-07","logstash-2018-07-08","logstash-2018-07-09"等,同時每天新建一個索引。從而把資料分散到多個索引裡。在查詢時也可通過規則匹配進行一個類索引進行查詢。
index template:
PUT _template/template_1
{
"template": "logstash*",
"settings": {
"number_of_shards": 1
},
"mappings": {
"type1": {
"_source": {
"enabled": false
},
"properties": {
"host_name": {
"type": "keyword"
},
"created_at": {
"type": "date",
"format": "EEE MMM dd HH:mm:ss Z YYYY"
}
}
}
}
}3.4.2 查詢優化
要使查詢效率提升,應儘量保證多的副本和少的分片。這一點與資料索引是相反的,所以要均衡處理。前文中提到歷史資料初始化時把副本和refresh都關閉了,在資料入庫完畢後可以恢復需要值,以保證資料查詢效率。資料分片數要結合資料大小和分索引情況一起考慮,按照分索引的兩個原則去處理。此外,這也不是完全貼合實際情況的一個最佳配置,需要在業務使用場景中一段時間應用才能確定最佳值,跟機器效能關係比較大。
我在實踐之處沒有做分索引處理,直接把單分片index到了lucene的最大值:2^31,大概是21億多個,這是lucene的上限。到達上限的lucene索引無法進行查詢,該分片處於unassigned狀態,但是其他分片也接近最大值,檢索效率依然很好。這可能是因為是新機器,並且沒有其他業務線在使用 。
。
常規優化:
1. segment合併,可通過相關引數配置segment合併頻率,基於段大小和每次合併個數。
2. 執行緒池配置,包括merge執行緒池,search執行緒池,index執行緒池,執行緒池作用主要是提高響應操作的併發量。比如預設的merge只有一個執行緒,合併segment的時候會比較慢一些,增加執行緒數可加快合併速率。
3. _forcemerge api 設定 max_num_segments為1進行強制合併,這個針對歷史資料更更新情況
4. 用過濾器對query進行替換使用,query與filter的區別可以參考這裡。簡而言之,可以歸結為query需要計算匹配相似得分,而filter是精確匹配,不計算得分並且對經常查詢的過濾器會有快取,查詢更快。
5. 帶路由條件查詢,我的2,3表的資料中有上級的主外建資訊,可以將與上一級的關聯id作為_routing。查詢時帶路由查詢直接定位分片位置,從而減少無關分片查詢。
四、總結
萬事開頭難,回憶卻也平淡。
由於個人對架構的認知和多樣的功能框架的瞭解還很少,所以生產實踐中還是免不了踩很多坑。必須認識到的一點,走過一段沼澤後,前面不一定就是美麗新世界,可能是--懸崖!接觸新事物的時候,充滿陌生、驚奇,在摸索中遇到問題有時也苦惱,在榨乾腦汁找出解決方法時會莫名的愉悅。不管過程怎麼樣,在得到結果後再去回憶,並沒有感覺有什麼值得興奮的東西,這大概就是成長吧。
批量理解,持續學習!