
Redis使用總結(二、快取和資料庫雙寫一致性問題)
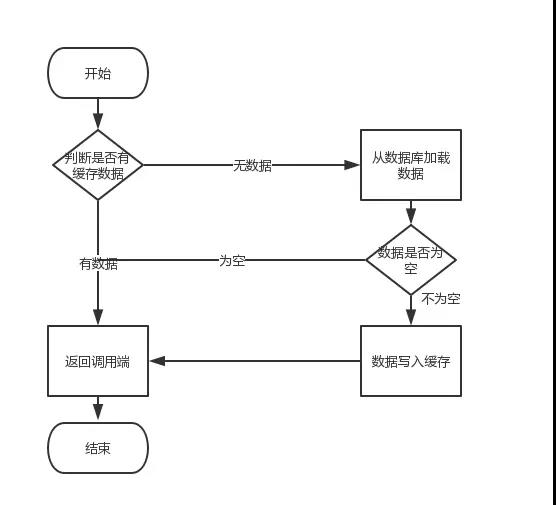
首先,快取由於其高併發和高效能的特性,已經在專案中被廣泛使用。在讀取快取方面,大家沒啥疑問,都是按照下圖的流程來進行業務操作。
但是在更新快取方面,對於更新完資料庫,是更新快取呢,還是刪除快取。又或者是先刪除快取,再更新資料庫,其實大家存在很大的爭議。目前沒有一篇全面的部落格,對這幾種方案進行解析。於是博主戰戰兢兢,頂著被大家噴的風險,寫了這篇文章。
文章結構
本文由以下三個部分組成
1、講解快取更新策略
2、對每種策略進行缺點分析
3、針對缺點給出改進方案
正文
先做一個說明,從理論上來說,給快取設定過期時間,是保證最終一致性的解決方案。這種方案下,我們可以對存入快取的資料設定過期時間,所有的寫操作以資料庫為準,對快取操作只是盡最大努力即可。也就是說如果資料庫寫成功,快取更新失敗,那麼只要到達過期時間,則後面的讀請求自然會從資料庫中讀取新值然後回填快取。因此,接下來討論的思路不依賴於給快取設定過期時間這個方案。
在這裡,我們討論三種更新策略:
先更新資料庫,再更新快取
先刪除快取,再更新資料庫
先更新資料庫,再刪除快取
應該沒人問我,為什麼沒有先更新快取,再更新資料庫這種策略。
(1)先更新資料庫,再更新快取
這套方案,大家是普遍反對的。為什麼呢?有如下兩點原因。
- 原因一(執行緒安全形度)
同時有請求A和請求B進行更新操作,那麼會出現
(1)執行緒A更新了資料庫
(2)執行緒B更新了資料庫
(3)執行緒B更新了快取
(4)執行緒A更新了快取
這就出現請求A更新快取應該比請求B更新快取早才對,但是因為網路等原因,B卻比A更早更新了快取。這就導致了髒資料,因此不考慮。
- 原因二(業務場景角度)
有如下兩點:
(1)如果你是一個寫資料庫場景比較多,而讀資料場景比較少的業務需求,採用這種方案就會導致,資料壓根還沒讀到,快取就被頻繁的更新,浪費效能。
(2)如果你寫入資料庫的值,並不是直接寫入快取的,而是要經過一系列複雜的計算再寫入快取。那麼,每次寫入資料庫後,都再次計算寫入快取的值,無疑是浪費效能的。顯然,刪除快取更為適合。
接下來討論的就是爭議最大的,先刪快取,再更新資料庫。還是先更新資料庫,再刪快取的問題。
(2)先刪快取,再更新資料庫
該方案會導致不一致的原因是。同時有一個請求A進行更新操作,另一個請求B進行查詢操作。那麼會出現如下情形:
(1)請求A進行寫操作,刪除快取
(2)請求B查詢發現快取不存在
(3)請求B去資料庫查詢得到舊值
(4)請求B將舊值寫入快取
(5)請求A將新值寫入資料庫
上述情況就會導致不一致的情形出現。而且,如果不採用給快取設定過期時間策略,該資料永遠都是髒資料。
那麼,如何解決呢?採用延時雙刪策略
虛擬碼如下
publicvoidwrite(Stringkey,Objectdata){
redis.delKey(key);
db.updateData(data);
Thread.sleep(1000);
redis.delKey(key);
}
轉化為中文描述就是
(1)先淘汰快取
(2)再寫資料庫(這兩步和原來一樣)
(3)休眠1秒,再次淘汰快取
這麼做,可以將1秒內所造成的快取髒資料,再次刪除。
那麼,這個1秒怎麼確定的,具體該休眠多久呢?
針對上面的情形,讀者應該自行評估自己的專案的讀資料業務邏輯的耗時。然後寫資料的休眠時間則在讀資料業務邏輯的耗時基礎上,加幾百ms即可。這麼做的目的,就是確保讀請求結束,寫請求可以刪除讀請求造成的快取髒資料。
如果你用了mysql的讀寫分離架構怎麼辦?
ok,在這種情況下,造成資料不一致的原因如下,還是兩個請求,一個請求A進行更新操作,另一個請求B進行查詢操作。
(1)請求A進行寫操作,刪除快取
(2)請求A將資料寫入資料庫了,
(3)請求B查詢快取發現,快取沒有值
(4)請求B去從庫查詢,這時,還沒有完成主從同步,因此查詢到的是舊值
(5)請求B將舊值寫入快取
(6)資料庫完成主從同步,從庫變為新值
上述情形,就是資料不一致的原因。還是使用雙刪延時策略。只是,睡眠時間修改為在主從同步的延時時間基礎上,加幾百ms。
採用這種同步淘汰策略,吞吐量降低怎麼辦?
ok,那就將第二次刪除作為非同步的。自己起一個執行緒,非同步刪除。這樣,寫的請求就不用沉睡一段時間後了,再返回。這麼做,加大吞吐量。
第二次刪除,如果刪除失敗怎麼辦?
這是個非常好的問題,因為第二次刪除失敗,就會出現如下情形。還是有兩個請求,一個請求A進行更新操作,另一個請求B進行查詢操作,為了方便,假設是單庫:
(1)請求A進行寫操作,刪除快取
(2)請求B查詢發現快取不存在
(3)請求B去資料庫查詢得到舊值
(4)請求B將舊值寫入快取
(5)請求A將新值寫入資料庫
(6)請求A試圖去刪除請求B寫入對快取值,結果失敗了。
ok,這也就是說。如果第二次刪除快取失敗,會再次出現快取和資料庫不一致的問題。
如何解決呢?
具體解決方案,且看博主對第(3)種更新策略的解析。
(3)先更新資料庫,再刪快取
首先,先說一下。老外提出了一個快取更新套路,名為《Cache-Aside pattern》。其中就指出
失效:應用程式先從cache取資料,沒有得到,則從資料庫中取資料,成功後,放到快取中。
命中:應用程式從cache中取資料,取到後返回。
更新:先把資料存到資料庫中,成功後,再讓快取失效。
另外,知名社交網站facebook也在論文《Scaling Memcache at Facebook》中提出,他們用的也是先更新資料庫,再刪快取的策略。
這種情況不存在併發問題麼?
不是的。假設這會有兩個請求,一個請求A做查詢操作,一個請求B做更新操作,那麼會有如下情形產生
(1)快取剛好失效
(2)請求A查詢資料庫,得一箇舊值
(3)請求B將新值寫入資料庫
(4)請求B刪除快取
(5)請求A將查到的舊值寫入快取
ok,如果發生上述情況,確實是會發生髒資料。
然而,發生這種情況的概率又有多少呢?
發生上述情況有一個先天性條件,就是步驟(3)的寫資料庫操作比步驟(2)的讀資料庫操作耗時更短,才有可能使得步驟(4)先於步驟(5)。可是,大家想想,資料庫的讀操作的速度遠快於寫操作的(不然做讀寫分離幹嘛,做讀寫分離的意義就是因為讀操作比較快,耗資源少),因此步驟(3)耗時比步驟(2)更短,這一情形很難出現。
假設,有人非要擡槓,有強迫症,一定要解決怎麼辦?
如何解決上述併發問題?
首先,給快取設有效時間是一種方案。其次,採用策略(2)裡給出的非同步延時刪除策略,保證讀請求完成以後,再進行刪除操作。
還有其他造成不一致的原因麼?
有的,這也是快取更新策略(2)和快取更新策略(3)都存在的一個問題,如果刪快取失敗了怎麼辦,那不是會有不一致的情況出現麼。比如一個寫資料請求,然後寫入資料庫了,刪快取失敗了,這會就出現不一致的情況了。這也是快取更新策略(2)裡留下的最後一個疑問。
如何解決?
提供一個保障的重試機制即可,這裡給出兩套方案。
方案一:
如下圖所示
流程如下所示
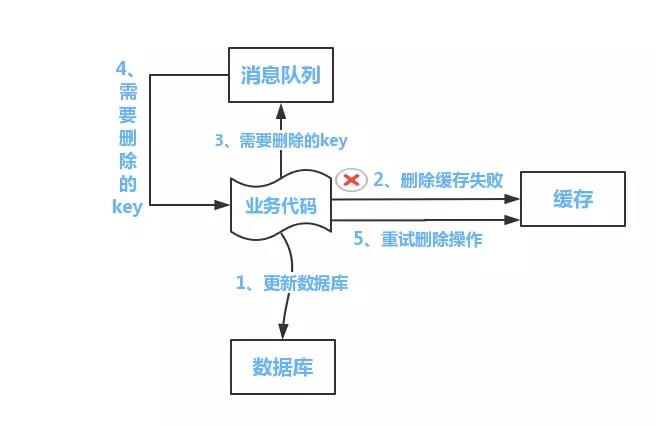
(1)更新資料庫資料;
(2)快取因為種種問題刪除失敗
(3)將需要刪除的key傳送至訊息佇列
(4)自己消費訊息,獲得需要刪除的key
(5)繼續重試刪除操作,直到成功
然而,該方案有一個缺點,對業務線程式碼造成大量的侵入。於是有了方案二,在方案二中,啟動一個訂閱程式去訂閱資料庫的binlog,獲得需要操作的資料。在應用程式中,另起一段程式,獲得這個訂閱程式傳來的資訊,進行刪除快取操作。
方案二:
流程如下圖所示:
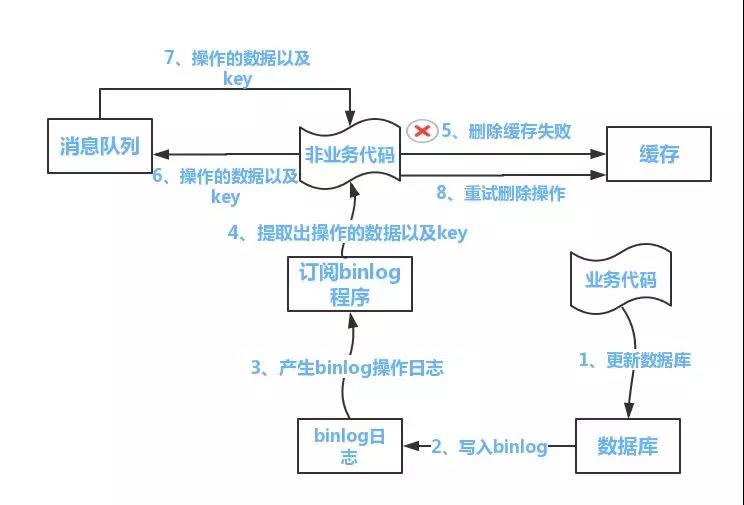
(1)更新資料庫資料
(2)資料庫會將操作資訊寫入binlog日誌當中
(3)訂閱程式提取出所需要的資料以及key
(4)另起一段非業務程式碼,獲得該資訊
(5)嘗試刪除快取操作,發現刪除失敗
(6)將這些資訊傳送至訊息佇列
(7)重新從訊息佇列中獲得該資料,重試操作。
備註說明:上述的訂閱binlog程式在mysql中有現成的中介軟體叫canal,可以完成訂閱binlog日誌的功能。至於oracle中,博主目前不知道有沒有現成中介軟體可以使用。另外,重試機制,博主是採用的是訊息佇列的方式。如果對一致性要求不是很高,直接在程式中另起一個執行緒,每隔一段時間去重試即可,這些大家可以靈活自由發揮,只是提供一個思路。
總結
本文其實是對目前網際網路中已有的一致性方案,進行了一個總結。對於先刪快取,再更新資料庫的更新策略,還有方案提出維護一個記憶體佇列的方式,博主看了一下,覺得實現異常複雜,沒有必要,因此沒有必要在文中給出。最後,希望大家有所收穫。