
記憶體模型系列(上)- 記憶體一致性模型(Memory Consistency)
Memory Models Series - Memory Consistency (Slides)
日誌:
- [2018-06-19] 完成了本文的 PPT 框架及除 TSO 外的全部文字說明。等閒了再把說明補全。
作者按:記憶體模型系列(上)- 記憶體一致性模型。本文為記憶體模型系列上篇,主要深入淺出地介紹了用於描述訪存順序及訪存原子性的一致性模型。本文主要面對物件為剛接觸併發程式設計的程式設計者,為了方便讀者理解,本文將盡量採用偏口語的文風,並儘量避免有關硬體實現的部分。其實後半部分沒法談也不需要談吧,這個話題太大了,而且作為一名程式設計者,你只需要用把記憶體模型當作一個工具來用就可以了。
1. 簡介
首先介紹一下本文的大綱。本文將嘗試性地採用講 PPT 的形式展開。PPT 的主要內容共計 20 頁,其中 5 頁講了我們為什麼需要了解(記憶體)一致性模型,5 頁講了最嚴格的一致性模型——順序一致性模型,10 頁以 x86 的 TSO 為例講了較為寬鬆的一致性模型,最後 1 頁列出了我所參考的文獻。本文中所有圖片相應的介紹都在圖片上方。

在談到併發程式設計的時候,我們主要有兩種程式設計正規化:訊息傳遞及共享記憶體。前者主要用於分散式系統,通過網路,採用訊息的傳送及接收的方式完成對共享資料的訪問;而後者主要用於單機,通過內部互聯匯流排,採用讀寫共享記憶體的方式完成對共享資料的訪問。一致性模型為後者服務。
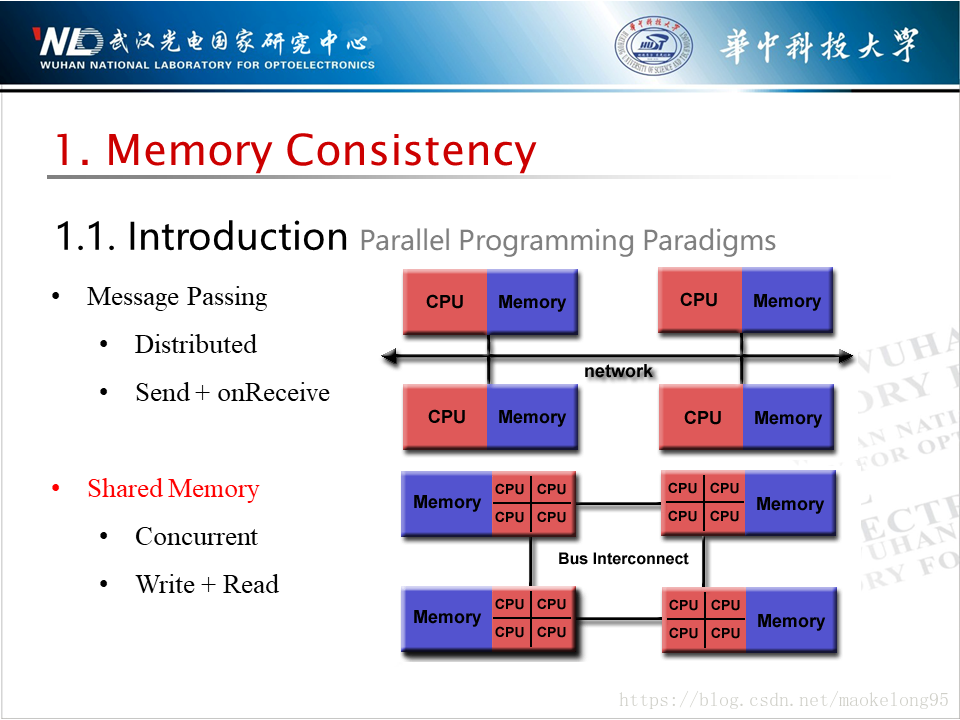
下面考慮一段很簡單的程式。下圖中,三個處理器(P1、P2、P3)依次執行三段程式片段。在執行虛線下部分程式碼之前,三個處理器共享三個初始化為零的變數,ABC。按照你的理解,下例中可能輸出的結果是什麼呢?
你很可能會說,A == 1 && C == 1。是的,這是最符合直覺的結果。但別的結果,包括 A == 0 && C == 1、A == 1 && C == 0 及 A == 1 && C == 0 都是有可能的。這是怎麼回事呢?
以 A == 0 && C == 1 為例,當 P1 上的賦值語句 C = 1 及 A = 1 完成之後,P2 看見
簡而言之,其中的坑在於,你以為 C = 1 執行完之後,所有處理器都應該看到 C 的最新值,但實際可能不是這樣。
注意: 本文會使用「看見」這個詞。當一個處理器(PA)對共享變數(V)的本地副本進行了修改,而另一個處理器(PB)用於儲存相應變數的快取行因此而失效或被更新,則本文稱 PB 看見了 PA 對變數 V 的修改。

所以到底是誰規定著,處理器能否在一個變數為給定處理器可見之前繼續執行呢?就是今天我們要介紹的主角,一致性模型。

首先,讓我們來看看一致性模型的定義。所謂一致性模型,也就是一個用來規定新值啥時候傳播到某一給定處理器的策略。最早 \ 最晚是啥時候嘛,給句亮堂話。這個定義看起來有點像快取一致性協議,這個協議就是一個用來將修改過的快取副本傳播給別的快取的演算法。
倆兄弟看著挺像的,但前者確定的是何時,而後者確定的是如何。另外,還有些系統,雖然它們沒有狹義上的快取,但它們也存在一致性問題。

比如,給定一種系統,它在每個處理器內部都設定一塊寫緩衝區,用以吸收寫指令。後續本處理器在讀取記憶體的時候,如果檢測到寫緩衝區裡已經存在針對同一地址的寫了,那麼它就直接解析這個寫指令要寫入的值並返回。顯然,這樣的系統的優點在於,它能夠很好地增加訪存指令吞吐量。
如果這樣的設計放在單處理器系統上,那麼一點問題都沒有,這很像處理器設計裡常見的重定向設計。但是,在多核系統上就麻煩了。處理器可能會從記憶體裡讀到過期的資料,因為相關的寫操作可能仍然緩衝在緩衝區裡而未執行。也就是說別的處理器可能在一個處理器的寫操作可見之前讀取了過期的資料,這就是一致性問題嘛。
換作採用內部互聯匯流排的系統可能也存在類似的問題,詳情請參考文獻[1],無非是之前資料緩衝在了緩衝區,而現在緩衝在了暫存器上罷了,總之都造成了不同的處理器看見不一致資料的現實情況。
注意:這一段純屬考古,感興趣就看看,沒興趣完全可以跳過。另外本文中的訪存(Memory Access)指令包括讀存指令(Load)及寫存指令(Store)。

2. 順序一致性
一致性模型裡最嚴苛的就是順序一致性了,它的定義很繞口:我們稱一個多處理器系統是「順序一致的」,當該多處理器系統的執行結果看起來好像所有處理器的操作按照某種線性順序執行,且在該線性順序中,各處理器的操作還遵循程式指定順序。
當然,你們勤勞的博主是不會把這麼一大段難消化的東西直接丟給你們的,這樣也太失敗了。其實大家抓住兩個關鍵詞就可以了:程式順序和原子性。

所謂程式順序,也就是說各處理器的操作保持程式指定的順序。
為什麼要約束到程式順序?以下圖程式為例,開發者原本期望通過 Flag1 和 Flag2 來控制兩段程式中的臨界程式碼最多隻有一個可以執行,但是,如果處理器 / 編譯器對執行的執行順序進行了排程,使得 Flag1 和 Flag2 的執行被挪到了臨界程式碼之後,那這樣一來兩段臨界程式碼都會執行,從而違背了開發者的期望。
所以這和一致性有什麼關係嗎?如果一條訪存指令都被挪到別的地方去了,那麼你就可以理解為,甚至連本處理器都將延遲看到本條指令的結果。翻到上面去看看一致性模型的定義,是不是覺得就明白了?

所謂原子性,也就是說各處理器能夠同時看到訪存指令。
為什麼要約束原子性?這是很顯然的事情。拿這個曾經講過的例子來說,如果 A = 1 同時被 P2 和 P3 看見,那麼 register1 的值就不可能是 0 了,因為 register1 能被賦值說明所有處理器都看見 B = 1,說明所有處理器都看見 A = 1。P3 總不能裝瞎不是?

雖然開發者可能很喜歡順序模型,因為真的很容易理解,但編譯器就不開心了。以前我能用的那些基於重排序的優化都不能用了啊!我的程式碼移動啊!我的暫存器染色啊!我的子表示式消除啊!我的別的騷操作啊!統統都涼了啊!

3. 寬鬆一致性
所以說把順序一致性的要求放低一點,讓程式設計者有更多知識學,讓指令優化有更多空間折騰嘛。比順序一致性更寬鬆的記憶體模型就稱之為寬鬆一致性。
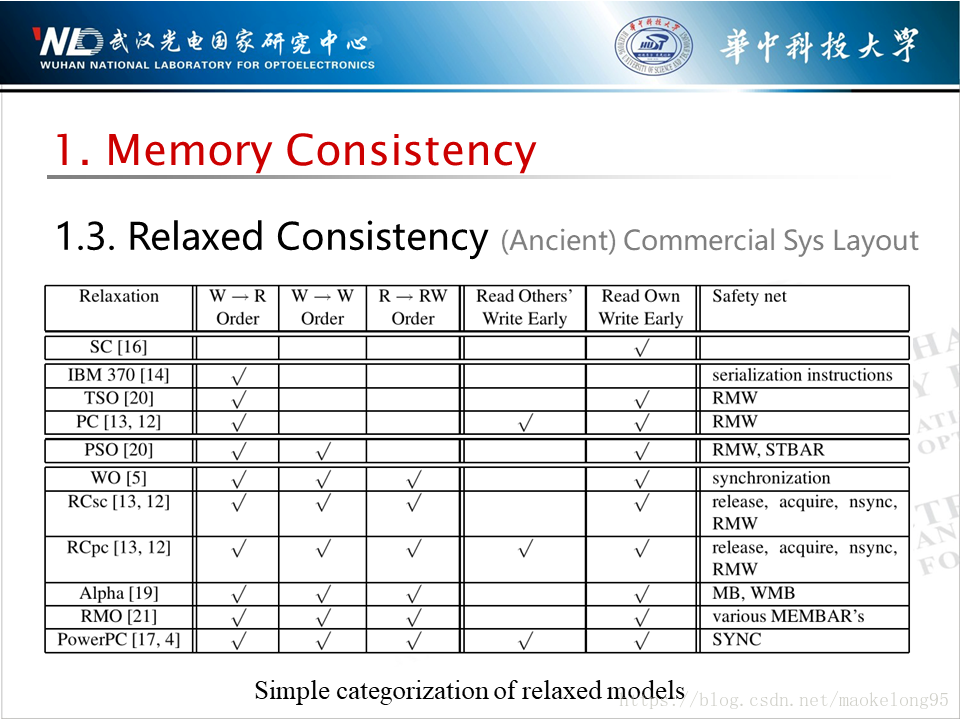
下圖是一張考古圖,裡面放了各大著名記憶體模型的特徵。比較新的可以移步維基百科「Memory Ordering」。實用著想,這裡主要以 Intel 所採用的 TSO 模型為例展開。
圖表中標題的含義將在後面介紹。
注意:1. 最早是 SPARC 採用的 TSO,只是現在 Intel x86 更出名一些;2. 在維基百科上你能看到「x86 oostore」,不用管它,這鬼東西已經滅亡了。
什麼叫做 TSO 呢。當各處理器看見所有寫存指令的執行順序是一樣的時候,我們稱這些寫存指令是 TSO 的。我不喜歡直接丟定義,所以接下來我會很結合大量例子詳細地介紹 TSO 的特性。恩,特性而非定義,才是大家最喜聞樂見的。
在具體講解之前,先給大家打一針預防針。前面我們也談到了,順序模型主要從程式順序及原子性兩個維度上約束了新值為任一處理器可見的時機。自然而然地,我們放鬆一致性模型時也會從這兩方面入手。對應到上張圖中的表,2~4 列就是用來描述是如何放鬆程式順序的,5~6 列就是用來描述如何放鬆原子性的。那麼放鬆的一致性模型怎麼再變得嚴格起來呢?所預留的手段就稱之為安全網(Safety Net)。
另外你應該會很困惑「→」是個什麼鬼,其實這就是 Happened-before 關係的標識,通俗地理解就是,當 A→B 時,B 必須發生在 A 之後。









參考文獻
下圖給出了本文主要參考的文獻,其中本文的內容框架啟發自第一篇文獻,本文中有關 TSO 的介紹主要摳自第二篇文獻,本文中有關鎖指令的描述主要摳自第三篇文獻。
