
Real-Time Rendering-第二章 The Graphics Rendering Pipeline
第二章 The Graphics Rendering Pipeline(圖形渲染管線)
“A chain is no stronger than its weakest link.”
—Anonymous
本章主要介紹實時圖形學中公認為最核心的部分,稱為graphics rendering pipeline,也可以簡稱為管線。管線的主要功能是根據場景中給定的虛擬相機,三維物體,光源,陰影計算公式,紋理以及更多的元素,生成一幅二維的影象。因此渲染管線是實時渲染的底層核心工具。使用管線執行渲染影象的過程如圖2.1所示。在該影象中,物體所處的位置和形狀由物體的幾何圖形,環境特徵以及環境中相機的位置共同決定。物體最終呈現的外觀受材質屬性,光源,紋理以及陰影模型的影響。
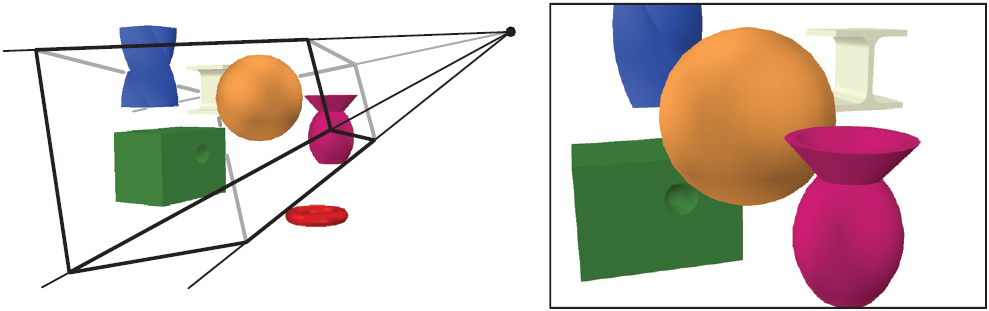
圖2.1 左圖中有一個虛擬相機位於金字塔的頂端(也就是四條線的交集)。只有位於視域體內部的圖元才會被渲染。對於透視渲染的影象(即圖中所示的情況),視域體是一個frustum(平截頭體),即一個矩形基底的被截斷的金字塔。右圖中顯示了相機“看到”的內容。其中左圖中的紅色圓圈形狀的物體沒有被渲染到右圖中,因為該物體位於視域體之外。同樣,左圖中藍色的彎曲稜柱體也被截頭體的上平面剪裁了。
現在開始討論渲染管線的各個不同階段,我們重點講解每個階段的功能,而不是具體的實現細節。這些實現細節中的部分會在後面的章節進行講解,要麼就是屬於程式開發人員無法控制元件的部分。例如,對於使用直線的開發人員來說,重要的是關注一些如頂點資料格式,顏色和模式型別的特點,以及depth cueing是否可用,而不是考慮直線是通過Bresenham直線繪製演算法還是通過一種對稱的兩步演算法實現的。通常管線中的部分階段是使用不可程式設計的硬體實現的,因為無法對這些階段的實現過程進行優化或改進。關於幾何圖形的基本繪製和填充演算法的細節,在其他的書籍如Rogers中進行了深入的講解。雖然我們無法控制底層硬體的部分實現,但是應用層的演算法和編碼方法也會對生成影象的速度和質量產生重大的影響。
2.1 Architecture(管線的體系結構)
在實際的物理世界中,管線的概念具有多種不同的表現形式,從工廠裝配線到滑雪運送機都是一種管線形式。另外,管線的概念還應用於描述圖形渲染。
管線由多個階段組成。例如,在石油管線中,石油無法從管線的第一個階段流動到第二個階段直到第二階段的石油已經流到了第三個階段,依此類推。這種流動過程意味著管線的速度由最慢的階段決定,而不管其他階段的速度有多快。
理想情況下,把一個非管線系統劃分成 n 個管線階段可以使管線的執行速度提高 n 倍。這種方法帶來的效能提升是使用管線的主要原因。例如,一輛滑雪纜車只包含一個座位是非常低效的,增加更多的座位可以成比例的快速增載入上山的滑雪人數。雖然管線的每一個階段是並行執行的,但是它們需要停頓以等待最慢的管線階段執行完成。例如,在一輛汽車的組成生產線上如果方向盤安裝階段需要執行3分鐘,而其他的階段都只用兩分鐘,那麼組裝完成一輛車的最快速度是3分鐘;在執行過程中,其他階段會有1分鐘的空閒狀態以等待方向盤安裝完成。對於這種管線,方向盤階段就是管線的瓶頸,因為這個階段決定了整個生產過程的速度。
這種管線結構也用於表示實時計算機圖形的執行過程。實時渲染管線可以粗略的劃分為三個conceptual stages——application,geometry以及rasterizer,如圖2.2所示。這種劃分結構是實時計算機圖形應用程式的核心,即渲染管線的引擎,因此是討論後續章節必不可少的基礎。此外,這三個階段本身還是一個管線,即每一個階段又包括一些子階段。 根據功能的不同,我們可以把conceptual階段(application,geometry,rasterizer)區分為functional階段和pipeline階段。在一個functional階段執行某個具體的任務,但是不會指定在管線中該任務的執行方式。另一方面,一個pipeline階段會與其他的pipeline階段同步執行。另外,為了滿足高效能需求,一個pipeline階段還可能會並行執行。例如,geometry階段可能會被劃分為5個functional階段,但是這是一個圖形系統確定管線劃分階段的實現方式。一種給定的實現方法是把兩個耗時較少的functional階段合併為一個pipeline階段,而把一個耗時的functional階段劃分為多個pipeline階段,甚至對該階段並行執行。
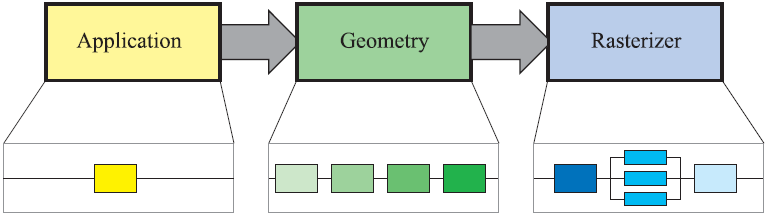
圖2.2 渲染管線的基本結構,由三個階段組成:application,geometry以及rasterizer。每一個階段本身又可以是一個管線結構,如geometry階段下面描述了這種子階段的情況,或者一個階段可以是(部分)並行的,如rasterizer階段的下面所示。在該圖中,application階段是單個程序,但是該階段也可以進行管線劃分或並行執行。
管線中速度最慢的階段決定了渲染速度,即影象的重新整理速率。可以使用單位frames per second(fps)進行表示,即每秒鐘渲染的影象數量。另外,也可以使用單位Hertz(Hz)表示,簡單地記為
EXAMPLE:RENDERING SPEED。假設輸出裝置的最大重新整理頻率為60Hz,並且已經找到了渲染管線的瓶頸。通過計時得到該階段執行時間為62.5ms。那麼可以使用以下方法計算渲染速度。首先,在不考慮輸出裝置重新整理頻率的情況下,可以得到最大的渲染速度為
顧名思義,application階段是由應用程式驅動的,以軟體的實現方式執行在通用CPUs中。這些CPUs通常含有多個核心單元支援以並行的方式處理多個執行緒的執行。因此CPUs可以高效地處理需要由application階段完成的多個不同的任務。一般地,在CPU中執行的任務主要包括碰撞檢測,全域性加速演算法,動畫,物理模擬,以及根據應用程式型別對應的大量其他的任務。下一步是geometry階段,主要處理變換,投影等運算。在這個階段主要計算將要繪製的內容,如何繪製,以及要儲存繪製資料的載體。Geometry階段通常是在一個圖形處理單元(GPU)中進行處理的,與固定管線功能的顯示卡一樣,GPU中包含大量的可程式設計核心。最後在rasterizer階段,使用前面階段產生的資料繪製(渲染)一幅影象,與任何per-pixel(針對每個畫素)進行計算所期望的結果一致。另外,rasterizer階段完成在GPU中處理。在接下來的三節中,我們將分別討論這三個階段以及每個階段的內部管線。在第3章會更詳細地詳解GPU如何處理每一個階段。
2.2 The Application Stage
由於application階段是在CPU端執行的,因此開發人員可以完全控制該階段的執行過程。於是,開發人員可以確定application階段的完整實現,並在以後對其進行修改以提高程式的效能。對這個階段的修改也會影響後續階段的效能。例如,application階段的演算法或設定可以減少要渲染的三角形數量。
在application階段的最後,需要把要渲染的幾何圖形傳遞給geometry階段。這些幾何圖形也就是rendering primitives(圖元),即points,lines和triangles,最終會顯示到螢幕上(或者任何其他的輸出裝置)。這一過程是application階段最重要的任務。
由於application階段是基於軟體實現的,因此不需要像geometry和rasterizer階段那樣把該階段劃分為多個子階段。但是這個階段通常會在多個處理器核心中並行執行,以提高程式效能。在CPU設計中,這種方式稱為superscalar(超標量)架構,支援在同一個階段同時執行多個指令。在第15章的15.5節講述了多個處理器核心的各種不同的使用方法。
注:由於CPU本身就是一種規模非常小的流水線,因此說application階段可以進一步劃分為多個流水線階段,但是這種流水線與本章所討論的管線是毫不相干的。
在application階段最常用實現的一種操作過程是collision detection(碰撞檢測)。與一種壓力反饋的裝置一樣,一旦在兩個物體之間檢測到了碰撞,就會產生一種響應並反饋給相互碰撞的物體。另外,在該階段還會處理一些其他的輸入源,比如鍵盤,滑鼠,頭盔等。根據不同的輸入,需要採取不同種類的處理措施。最後,在這個階段實現的其他計算過程包括紋理動畫,通過變換得到的動畫,或者任何只在該階段執行的運算。一些常用的加速演算法,如分層視域體剔除(見14章),也會在這一階段執行。
2.3 The Geometry Stage
在geometry階段主要處理大多數的per-polygon和per-vertex(針對每個多邊形和每個頂點)的操作運算。該階段會被進一步劃分為以下幾個functional階段:model和view transform(模型和檢視變換),vertex shading(頂點著色),projection(投影),clipping(裁剪),以及screen mapping(螢幕對映)(如圖2.3所示)。需要再次提醒的是,根據這些functional階段的實現方式,這些階段可能等同於pipeline階段,也可能不同。在某些情況下,一連串的functional階段形成單個pipeline階段(與其他的pipeline階段保持並行執行)。在另一些情況下,functional階段可能會被劃分為多個規模較小的pipeline階段。

圖2.3把Geometry階段劃分為由多個functinal階段組成的管線。
例如,在某種極端情況下,整個渲染管線的所有階段都可能以軟體的方式執行在單個處理器上,這時你可以認為整個渲染管線只有一個pipeline階段組成。這正是在獨立的加速晶片和主機板出現之前,所有顯示卡的生成方式。在另一種極端情況下,每一個functional階段都可以被劃分為多個小的pipeline階段,並且每一個小的pipeline階段可以在一個指定的處理器核心單元上執行。
2.3.1 Model and View Transform
在一個模型顯示到最終螢幕的過程中,需要把該模型變換到到多個不同的空間或座標系中。一開始,模型位於自身的model space中,意味著還沒有進行任何變換。每一個模型可以與一個model transform進行關聯,用於設定模型的位置和方向。另外,一個模型還可能與多個model transforms進行關聯。這種方法允許同一個模型的多個副本(稱為instances例項)在同一個場景中具有不同的座標位置,方向和大小,而不需要複製多個基本的幾何圖形。
模型的變換主要是指使用與模型關聯的model transform對模型的頂點和法線進行變換。最開始一個物體所在的座標稱為model coordinates,把model transform應用於這些座標之後,就稱模型位於world coordinates或處於world space中。對於所有的模型來說,world space是唯一的,在所有的模型使用各自的model transforms進行變換之後,這些模型都位於同一個空間中。
如前文所述,只有相機(或觀察者)能夠看到的模型才會被渲染。相機在world space中有一個位置和方向表示,用於放置相機並指定相機的觀察目標。為了方便計算投影和裁剪,需要使用view transform對相機和所有的模型進行變換。View transform的目的是把相機放置在座標原點,並設定觀察方向,使得相機向前的方向為座標的負z軸,y軸指向向上的方向,x軸指向向右的方向。
在這裡我們約定使用-z軸表示正向,在有些資料中更偏向於使用+z軸。這兩種表示方法主要是語義的不同,因為從一種表示變換到另一種是非常簡單的。
使用view transform進行變換之後的實際位置和方向依賴於底層的圖形應用程式設計介面(API)。因此使用這種方式劃分的空間稱為camera space,或更通用的,稱為eye space。在圖2.4中顯示了一個使用view transform如何影響相機和模型的位置和方向的示例。Model transform和view tansform都是使用
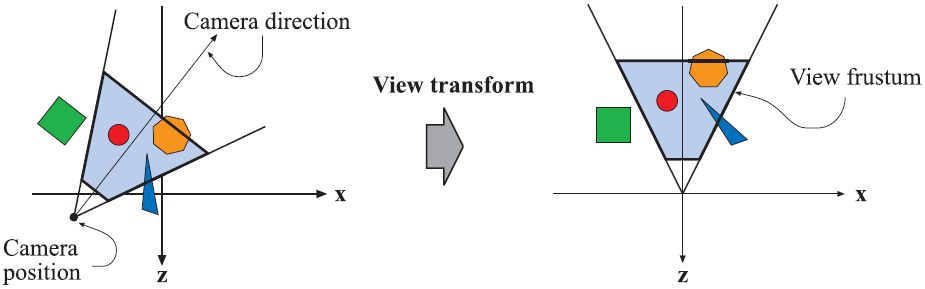
圖2.4 在左圖中,相機位於使用者指定的位置並朝向使用者指定的方向。在右圖中,使用view transform把相機轉移到原點,並指向負z軸。這種變換是為了更簡單,更快速的執行裁剪和投影操作。其中淺灰色區域是相機的視域體。在這裡,我們假設使用透視投影,因為視域體是一個錐體。同樣的技術可以用於處理任意型別的投影。
2.3.2 Vertex Shading
要生成一個逼真的場景,僅僅渲染場景中物體的幾何形狀和座標位置是遠遠不夠的,還需要模擬物體的顯示外觀。這種描述包括每一個物體的材質,以及任意光源照射在物體上呈現的效果。模擬材質和光源的方法多種多樣,從設定簡單的顏色到精心設計物體的外觀描述的表示形式。
這種確定一種光源照射到某種材質上的呈現效果的操作過程稱為shading(著色)。該過程涉及到計算物體上各個點的shading equation(著色公式)。通常情況,一部分計算是在geometry階段針對一個物體的頂點進行處理的,其他部分的計算在per-pixel(逐點)光柵化時處理的。每一個頂點中可以儲存多種不同的材質資料,比如點座標位置,法向量,顏色值或者任何其他的用於計算著色公式的資料資訊。然後,把頂點著色的結果值(包括顏色值,向量,紋理座標或任何其他型別的著色資料)傳送到光柵化階段進行插值運算。
通常我們認為在world space中執行著色計算。在實際操作中,有時把相關實體(比如相機和光源)變換到其他的座標空間中(比如model或eye space)執行這些計算。之所以可以在這些空間中進行計算是因為只要把著色計算中所有實體變換到同一個空間中,就可以使光源,相機和模型物體的相對關係保持不變。
在本書上將會深入討論著色計算,特別是在第3章和第5章。
2.3.3 Projection
完成頂點著色之後,渲染系統就開始處理projection(投影),投影是指把視域體變換成一個極值點為(-1,-1,-1)和(1,1,1)的單位立方體。這種單位立方體稱為canonical view volume(規範視域體)。有兩種常用的投影方法,分別稱為orthographic(正交)(也稱為平行)投影和perspective(透視)投影。如圖2.5所示。
注1:規範視域體可以使用不同的極值點,比如
0≤z≤1 。Blinn在一篇文章中[102]討論其他的間隔值。
注2:實際上正交投影只是平行投影的一種型別。例如,還有一種不常用的斜平行投影方法[516]。
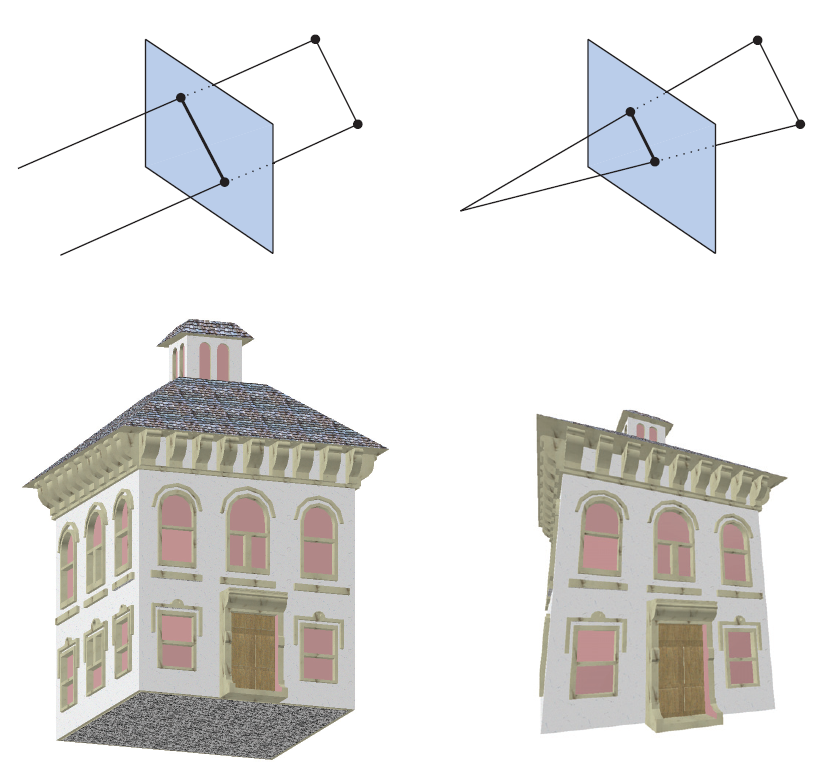
圖2.5 左邊是一個正交(或平行)投影的示例,右邊是透視投影的示例。
正交觀察檢視的視域體通常為長方盒,正交投影把該矩陣視域體變換為單位立方體。正交投影的主要特點是平行線經過投影變換之後依然是平行的。這種變換是由平移和縮放變換組合得到的。
透視投影比正交投影更復雜一點。在透視投影情況下,離相機距離越遠的物體,在投影之後看起來越小。另外,平行線經過投影后可能會在地平線端點相交。通過這種方法,透視投影可以模擬我們感知物體大小的方式。從幾何意義上來說,透視投影的視域體稱為錐體,是一種以矩陣為基底頂部被截斷的金字塔。正交投影和透視投影變換都可以使用
儘管這些矩陣把一種包圍體變換為另一種包圍,但是我們把這個過程稱為投影是因為在變換之後生成的影象中不會儲存 z 座標值。通過這種方式,模型由三維表示投影成二維表示。
注:不是完全不儲存 z 座標值,而是儲存到了一個Z-buffer中。見2.4節。
2.3.4 Clipping
只有全部或部分被包含在視域體之後的圖元才需要傳遞下光柵化階段,然後在顯示器上繪製這些圖元。完全位於視域體之內的圖元可以直接傳遞到下一個階段。而完全在視域體之外的圖元就不會再傳遞到下一階段,因為不會渲染這些圖元。只有部分位於視域體之內的圖元才需要clipping(裁剪)。例如,對於一條直接其中一個頂點位於視域體外,另一個頂點在視域體內部,需要根據視域體邊緣對其進行裁剪,使用線段與視域體相交得到的新頂點替換位於視域體外部的頂點。使用了投影矩陣就意味著經過投影變換後的圖元針對單位立方體進行裁剪。在執行裁剪操作之前先進行檢視變換和投影變換的好處是可以使得裁剪操作保持一致;因為圖元總是會針對單位立方體進行裁剪。裁剪操作的過程如圖2.6所示。除了視域體的6個裁剪面之外,使用者還可以增加自定義的裁剪面用於根據可見性剔除物體。在本書646頁的圖14.1中描述了這種視覺化型別,稱為sectioning(區域劃分)。在前面的geometry階段,通常使用可程式設計的處理單元執行,與此不同的是在clipping階段(還有接下來要討論的screen mapping階段)通常使用固定功能的硬體進行處理。
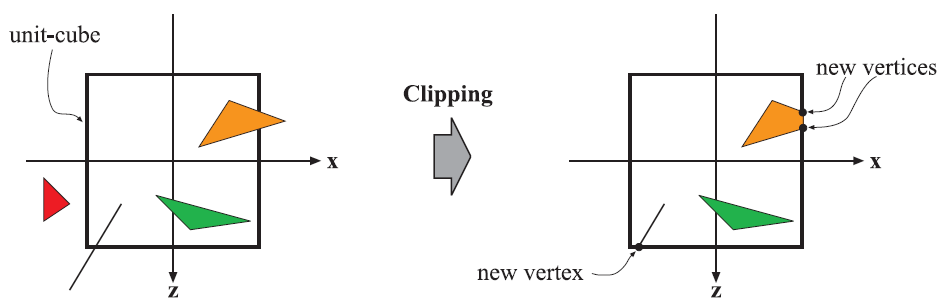
圖2.6 經過投影變換之後,只有位於單位立方體內部的(對應的位於視域體內部)圖元才需要進一步繼續處理。因此,位於單位立方體外部的圖元直接被丟棄,整個位於內部的圖元都被保留。對於那些與立方體相交的圖元,則針對立方體進行裁剪,最終生成新的頂點並丟棄裁剪之前舊的頂點。
2.3.5 Screen Mapping
只有位於視域體內部的(裁剪後)圖元會被傳遞到screen mapping階段,在進入這個階段的過程中依然是三維座標。每一個圖元的 x 和 y 座標會被經過變換以形成screen coordinates(螢幕座標)。螢幕座標與 z 座標結合一起也稱為window coordinates(視窗座標)。假設要把場景渲染到一個視窗中,該視窗最小座標位置為
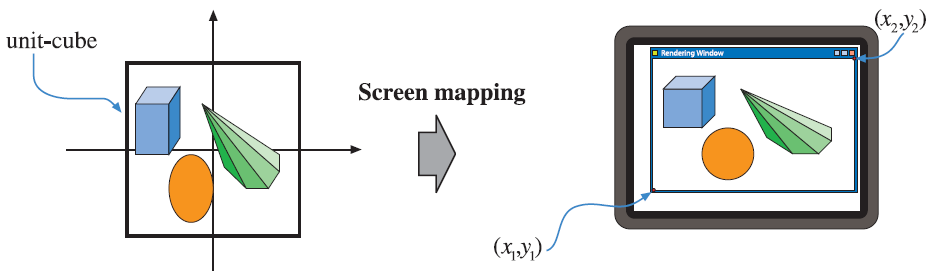
圖2.7 經過投影變換之後的圖元位於單位立方體中,screen mapping階段通過計算確定螢幕上的座標值。
關於screen mapping主要令人疑惑的是,如何把整數值和浮點值與畫素(紋理)座標進行關聯。在DirectX 9以及之前的版本中,使用一種以 0.0 作為畫素中心的座標系,這種情況下位於範圍[0,9]的一系列畫素會覆蓋[-0.5,9.5)的範圍跨度。Heckbert[520]提出了一種在邏輯上更一致的方案。給定一個水平的畫素陣列並使用笛卡兒座標,定義浮點數座標中最左邊畫素的左邊界為0.0。OpenGL中總是使用這種方案,在DirectX 10以及後續版本中也使用了這種方案。在這種情況下,畫素的中心為0.5。因為處於範圍[0,9]內的畫素覆蓋的範圍座標範圍為[0.0,10.0)。這種變換方法可以簡單地表示為
其中
雖然在所有APIs中,畫素的位置值都是從左向右進行遞增的,但是在OpenGL和DirectX的某些情況下,表示頂邊和底邊的 0 點值是不一致的。
“Direct3D”是DirectX的三維圖形API元件。DirectX還包括其他的API元件,如輸入和音訊控制組件。在本書中我們不區分針對其他的元件使用“DirectX”,而對這裡特定的API使用“Direct3D”表示,而是遵行通用的表示,統一使用“DirectX”。
OpenGL中傾向於在整個座標表示中都使用笛卡爾座標,把左下角作為最小值座標,而DirectX則會根據實際情況使用左上角表示最小值。對於每種API這只是一種邏輯的不同,對於具體的不同點沒有確切的答案。例如,在OpenGL中(0,0)位於影象的左下角,而在DirectX中則是左上角。DirectX之所以使用這種表示,是因為有大量的螢幕座標表示是從頂部到底部:Microsoft Windows就是使用這種座標系統,我們閱讀的時候也是這種方向,還有大量的影象檔案格式使用這種方式儲存畫素資料。當從一種API遷移到另一種API時,關鍵是要知道存在這些差異,並重點考慮這些問題。
2.4 The Rasterizer Stage
給定了變換和投影后的頂點,以及與頂點對應的著色資料(全部來自geometry階段),rasterizer階段的主要目的是計算並設定物體涵蓋的全部畫素(圖片元素的簡稱)的顏色值。這個過程稱為raterization(光柵處理)或scan conversion(掃描轉換),主要是把screen space中的二維頂點—每一個頂點包含一個 z 值(深度值)以及對應的各種各樣的著色資訊—轉換為螢幕上的畫素點。

圖2.8 把rasterizer階段劃分為多個functional階段的管線。
類似於geometry階段,rasterizer階段也被劃分為多個functional階段:triangle setup(組裝三角形),triangle traversal(遍歷三角形),pixel shading(pixel著色),以及merging(合併)(如圖2.8所示)。
2.4.1 Traingle Setup
在這個階段主要計算三角表面的差異以及其他資料。然後使用該資料執行掃描轉換,同時還用於執行由geometry階段產生的各種著色資料的插值運算。這個過程是由固定功能的硬體處理的,固定功能的硬體正是用於完成這些計算任務。
2.4.2 Triangle Traversal
在這個階段,檢查每一箇中心(或採樣)座標被三角形覆蓋的畫素點,並生成一個fragment(片段)用於表示覆蓋三角形的部分畫素點。查詢哪些畫素點或畫素點位於三角形內部的操作過程稱為triangle traversal或scan conversion。每一個三角形片段的屬性值是通過在三角形三個頂點之間執行插值運算生成的(見第5章)。這些屬性值主要包括片段的深度值,以及從geometry階段傳遞過來的任意著色資料。Akeley和Jermoluk[7]和Rogers[1077]提供了有關三角形遍歷的更多詳細的資訊。
2.4.3 Pixel Shading
在pixel shading階段使用作為輸入的插值後的shading資料處理任意的per-pixel shading(針對每一個畫素進行著色)計算。最終計算的結果是一種或多種顏色值,並被傳遞到下一個階段。Triangle setup和traversal階段通常是使用特定的硬體晶體矽進行處理,與此不同地是,pixel shading階段是在可程式設計的GPU核心上執行。在這個階段可以使用多種技術,其中最重要的一種是texturing(紋理貼圖)。在第6章我們將會詳細講解texturing。簡單來講,對一種物體進行紋理貼圖就是把一張圖片“貼上”到物體上。圖2.9描述了這個過程。紋理圖片可以是一維、二維或者三維的,其中二維圖片是最常用的一種。

圖2.9 左上角顯示了一個dragon模型沒有進行紋理貼圖的情況。把右邊的紋理圖片一塊塊“貼上”到該模型上,可以得到左下角所示的結果。
2.4.4 Merging
每一個畫素的資訊都儲存在color buffer(顏色值快取)中,該buffer是一個顏色值(每一個顏色值由紅,綠,藍分量組成)的矩陣陣列。在merging階段主要負責把shading階段產生的片段顏色值與color buffer中當前儲存的顏色值進行合併。與shading階段不同的是,通常用於執行merging階段的GPU子單元不是完全可程式設計的。但是,該階段是高度可配置的,允許實現各種各樣的效果。
另外,在merging階段還要解決可見性問題。這意味著,當整個場景都被渲染了,從相機的觀察角度,color buffer中需要包含場景中可見圖元部分的顏色值。對於大多數的顯示卡,這個過程是由Z-buffer(也稱為depth buffer,深度快取)演算法實現的[162]。Z-buffer是一種與color buffer具有相同大小的形狀的快取,對於每一個畫素儲存了從相機到當前最近的圖元之間的z-value(距離)。意思是當把一個圖元渲染到某個畫素點時,需要計算位於該畫素點的圖元的z-value,並與Z-buffer中位於同一個畫素點的z-value進行比較。如果新的z-value小於Z-buffer中的z-value,那麼要進行渲染的圖元比之前該畫素點上距離相機最近的圖元到相機的距離更近。因此,該畫素點的z-value和color值會被更新為當前正在繪製的圖元的z-value和color值。如果計算的z-value大於Z-buffer中的z-value值,那麼color buffer和Z-buffer保持不變。Z-buffer演算法非常簡單,演算法的複雜度趨近於
在無法使用Z-buffer的情況下,可以使用BSP tree以back-to-front(距離相機由遠及近)的順序繪製場景。關於BSP trees的詳細資訊見第14章14.1.2節。
前面我們已經討論過color buffer用於儲存顏色值,Z-buffer用於儲存每一個畫素點的z-value。除此之外還有其他的channels和buffers,可以用於篩選和捕獲片段的資訊。比如,在color buffer中除了紅,綠,藍通道值,還有alpha channel(通道),用於儲存每一個畫素點的相對透明度(見第5章5.7節)。在對傳入的片段執行深度測試之前可以先執行一次alpha test。片段的alpha測試是把片段的alpha值通過一些特定的測試(相等,大於等等)與一個參考值進行比較。如果片段無法測試通過,就在下一步的處理過程中移除。這種測試通常用於保證完全透明的片段不會影響Z-buffer(見第6章6.6節)。
在DirectX 10中,alpha測試不再是merging階段的一部分,而是pixel shader的其中一個function階段。
Stencil buffer(模板快取)是一個離屏快取,用於記錄渲染圖元的位置資訊,該buffer中每個畫素點通常包含8-bits。可以使用多種functions把圖元渲染到stencil buffer中,然後就可以使用該buffer中的資料控制渲染到color buffer和Z-buffer中的圖元。比如,假設有一個實心圓圈被渲染到stencil buffer中,只有在該圓圈可見的位置對應的圖元才會被渲染到color buffer中,結合這種方法我們能夠控制繪製到color buffer中的圖元了。另外,stencil buffer還是一種用於生成特殊效果的強有力的工具。在管線最後階段的所有functions都稱為raster operations(ROP)或blend operations。
Frame buffer(幀快取)通常包括一個渲染系統中的所有buffers,但有時候也會僅使用frame buffer表示color buffer和Z-buffer的集合。1990年,Haeberli和Akeley[474]提出了frame buffer的另一個補集,稱為accumulation buffer(累加快取)。在該buffer中,可以使用一組操作對影象進行累加處理。例如,可以把用於顯示一個運動中的物體的一組影象進行累加,再計算平均值,以生成運動模糊的效果。此外,還可以生成其他的效果,比如depth of field(景深),antialiasing(抗鋸齒),soft shadows(軟陰影)等等。
當基本圖元到達並傳遞到rasterizer階段,那些從相機的觀察角度來說是可見的圖元就會被顯示到螢幕上。螢幕顯示了color buffer中的儲存的內容。為了避免讓人眼看到圖元被渲染併發送到螢幕上的過程,需要使用double buffering(雙快取技術)。意思是說場景渲染的過程發生在離屏階段,在一個back buffer(後備快取)中。一旦場景被渲染到back buffer中,位於back buffer中的資料內容就會與front buffer(前置快取)進行交換,front buffer是螢幕上顯示的之前的場景。這兩個buffers的交換髮生在vertical retrace(垂直回掃)期間,這是安全處理buffers交換的時間段。
關於不同的buffers以及各種buffering方法的更多資訊,請閱讀第5章5.6.2節以及第18章18.1節。
2.5 Through the Pipeline
點、線和三角形是構建一個模型或物體的基本渲染圖元。設想使用者正在使用一個互動式的computer aided design(計算機輔助設計)應用程式設計一部手機。在這裡我們將會通過整個圖形渲染管線討論該模型,管線由三個主要的階段組成:application,geometry和rasterizer。通過透視投影到螢幕上的一個視窗對場景進行渲染。在這個簡單的示例中,手機模型同時包含圖元lines(顯示手機的邊緣部分)和triangles(顯示手機的表面)。通過一個二維的影象對部分三角形進行紋理貼圖,以顯示手機的鍵盤和螢幕。對於這種示例,shading計算全部在geoemtry階段執行,但是紋理的計算例外,該過程發生在rasterization階段。
Application
CAD應用程式允許使用者選中模型的部分並移動。例如,使用者可能會選擇手機的頂部,然後移動滑鼠翻轉蓋子並開啟手機。在application階段必須把滑鼠的移動轉化為一個對應的旋轉矩陣,然後在渲染時把該矩陣正確地應用到手機蓋的翻轉操作中。示例二,通過把相機沿著預設的路線進行移動,從不同的觀察角度顯示手機可以形成一種動畫的播放效果。其中相機的引數,如位置和觀察方向,必須在application階段根據執行的時間段進行更新。對於每個要渲染的幀,application階段把相機的位置,光照,以及模型的基本圖元傳遞到管線的下一個主要階段—geometry階段。
Geometry
在application階段計算了view transform,同時還計算了一個model matrix用於指定每一個物體的位置和方向。對於每一個傳遞到geometry階段的物體,通常把這兩個矩陣相乘以得到一個單一的矩陣。在geometry階段,首先使用這個concatenated matrix(由一系列矩陣相乘得到的連線矩陣)對物體的頂點和法向量執行變換。然後使用材質和光源屬性計算在頂點上的著色。接著執行投影運算,把物體變換到一個單位立方體空間中,該空間表示眼睛能看到的範圍。所有處於該立方體之外的圖元都會被丟棄。所有與該立方體相交的圖元都會被裁剪,以得到一組完全位於單位立方體內部的基本圖元。然後把頂點一一對映到螢幕上的視窗中。在執行完所有per-polygon(針對單個多邊形)的操作之後,就把處理的結果傳遞到rasterizer階段—管線中的最後一個主要的階段。
Rasterizer
在這個階段,所有基本圖元都被光柵化,即把圖元轉換為視窗中的畫素點。進入到rasterizer階段的每一個物體的可見的line和triangles都位於sceen space,以便於光柵化的轉換。對於那些關聯到紋理的triangles,使用應用到triangles上的紋理(圖片)進行渲染。關於圖元的可見性問題,可以使用Z-buffer演算法處理,以及可選的alpha測試和stencil測試。依次處理每一個物體,然後把最終的影象顯示到螢幕上。
Conclusion
這種管線由API和圖形硬體幾十年的演化而產生,致力於實時渲染應用程式。需要重點注意的是,這並不是唯一的渲染管線;離線渲染管線經歷了不同的發展路線。用於電影製作的渲染管線最常用的是micropolygon管線[196,1236]。此外,在學術研究和predictive rendering的應用中,如建築的視覺化預覽通常使用ray tracing(光線追蹤)渲染器(見第9章9.8.2節)。
多年來,應用程式開發人員使用本書描述的處理方法的唯一途徑是,使用圖形API定義的一種fixed-function pipeline(固定功能的管線)。之前稱為fixed-function pipeline是因為在圖形硬體中該管線的實現包含一些不能進行靈活程式設計的部件。在該管線中,各個部分可以被設定成不同的階段,比如Z-buffer測試可以開啟或關閉,但是無法編寫程式來控制把functions應用於各個階段的順序。最新的(也可能是最後一個)使用fixed-function的硬體機器是Nintendo(任天堂)的Wii。可程式設計GPUs的誕生,使得確定在整個管線的各個子階段到底執行什麼操作成為可能。雖然fixed-function pipeline的學習提供了對一些基本原理的合理介紹,但是大部分新的發展都是針對可程式設計GPUs。這種可程式設計性是本書第三版預設採用的方法,因為這是充分利用GPU的現代程式設計方法。
Further Reading and Resources
Blinn編寫的A Trip Down the Graphics Pipeline[105]是一本講解從頭開始編寫軟體渲染器的書,雖然這本書已經比較舊了,但不失為學習一種渲染管線的的部分精妙之處,較好的參考資料。對於fixed-function pipeline,經典書籍(但是不斷更新)OpenGL Programming Guide(又稱為紅寶書)[969]完整的講述了fixed-function pipeline以及用到的相關演算法。在本書的配套網站,http://www.realtimerendering.com,給出了多種渲染引擎實現的連結。