Hive-shell指令碼形式執行HSQL
阿新 • • 發佈:2018-12-22
Hive-指令碼形式提交hive查詢
接上文Mac-單機Hive安裝與測試,文中最後將本地檔案load到了hive 表中,下面對該表清洗,以shell指令碼形式提交,清洗所用的HSQL指令碼。
建立目標表
例如要清洗出的欄位如下表
use hive_test;
CREATE EXTERNAL TABLE fact_XXX_log(
time_stamp string COMMENT '時間戳',
dim1 string COMMENT 'dim1',
type string COMMENT '型別',
query_id string COMMENT 'query_id' 清洗SQL指令碼
hive_test.sh
#!/bin/sh
echo "---- start exec hive sql"
hive -e "SET hive.exec.dynamic.partition.mode = nonstrict;
INSERT OVERWRITE TABLE hive_test.fact_XXX_log
PARTITION (dt)
select
xxxxxx 這裡省略了
from
hive_test.system_log
;
echo "---- end hive sql"本地命令列提交SQL指令碼
本地執行指令碼
/shell$ ls hive_test.sh @localhost:~/Documents/book/shell$ sh hive_test.sh
執行日誌如下
---- start exec hive sql
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding
。。。。
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:
Query ID = xxxx_20180104111556_9381fc76-f0ba-4420-8207-bd4ca3cec77a
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
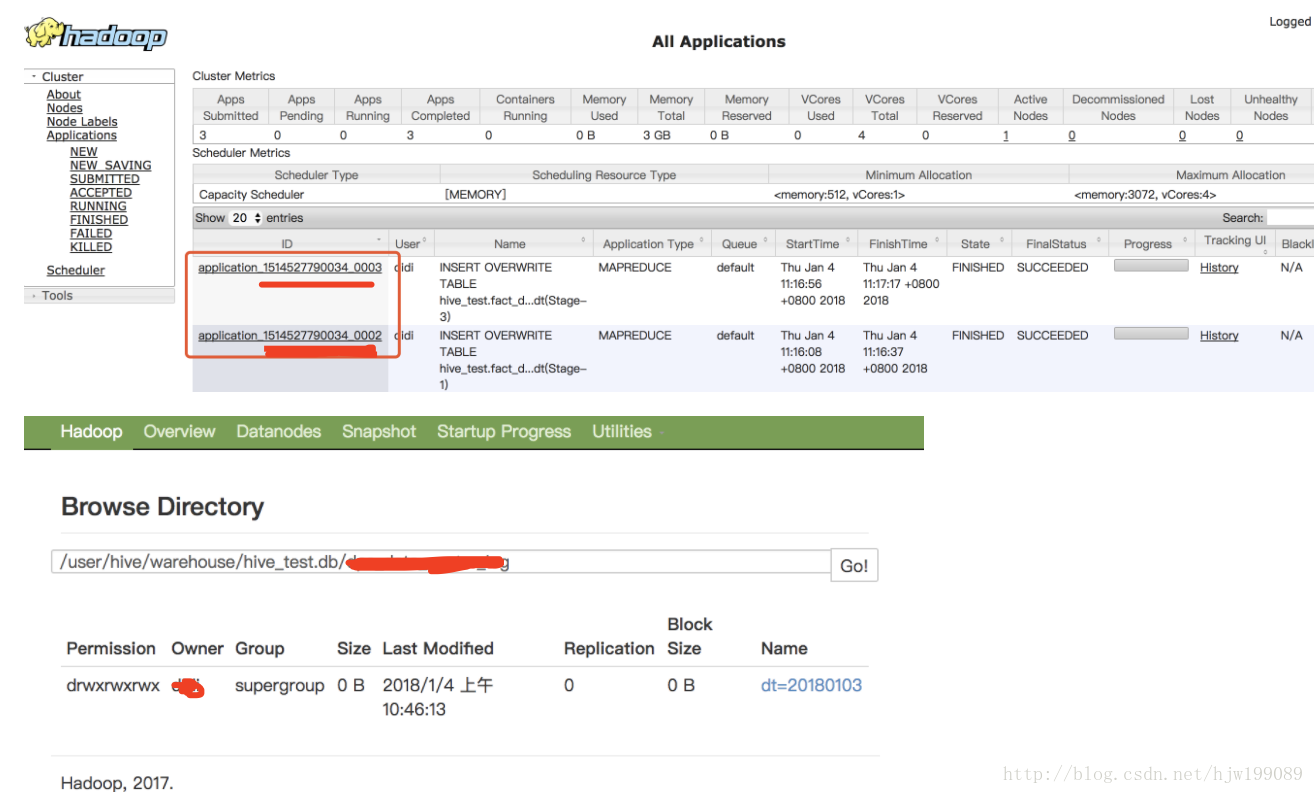
Starting Job = job_1514527790034_0002, Tracking URL = http://localhost:8088/proxy/application_1514527790034_0002/
Kill Command = xxxxxxxp job -kill job_1514527790034_0002
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 0
2018-01-04 11:16:26,465 Stage-1 map = 0%, reduce = 0%
2018-01-04 11:16:33,038 Stage-1 map = 50%, reduce = 0%
2018-01-04 11:16:37,179 Stage-1 map = 100%, reduce = 0%
Ended Job = job_1514527790034_0002
Stage-4 is filtered out by condition resolver.
Stage-3 is selected by condition resolver.
Stage-5 is filtered out by condition resolver.
Launching Job 3 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1514527790034_0003, Tracking URL = http://localhost:8088/proxy/application_1514527790034_0003/
Kill Command = xxxxxxxxadoop-2.7.4/bin/hadoop job -kill job_1514527790034_0003
Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
2018-01-04 11:17:10,803 Stage-3 map = 0%, reduce = 0%
2018-01-04 11:17:17,681 Stage-3 map = 100%, reduce = 0%
Ended Job = job_1514527790034_0003
Loading data to table hive_test.fact_XXX_log partition (dt=null)
Loaded : 1/1 partitions.
Time taken to load dynamic partitions: 0.2 seconds
Time taken for adding to write entity : 0.001 seconds
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 HDFS Read: 30906 HDFS Write: 6438 SUCCESS
Stage-Stage-3: Map: 1 HDFS Read: 10016 HDFS Write: 6240 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
Time taken: 82.54 seconds
---- end hive sql