
第五課:機器學習中的特徵工程
阿新 • • 發佈:2018-12-22
只是總結課程要點,特徵工程內容參見分類《feature engineering for machine learning》!
一、正負樣本不平衡處理方法

二、資料與特徵處理
- 數值型

- 類別型

- 時間型

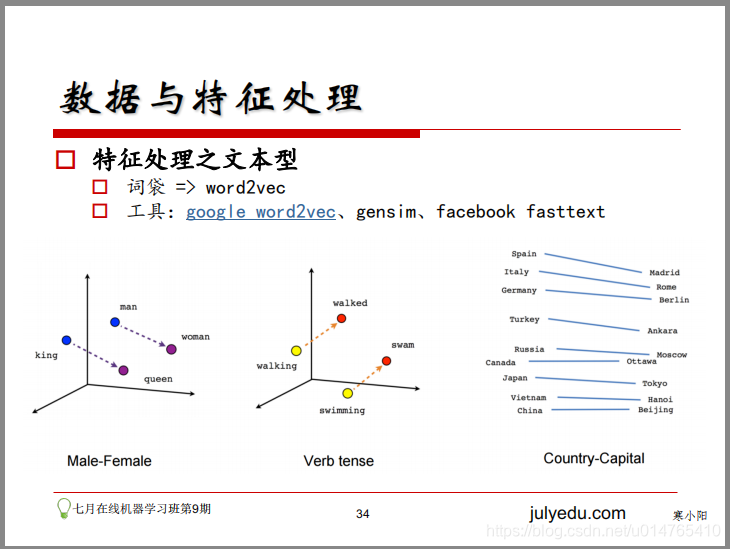
- 文字型
1)詞袋

2)n-gram
3)Tf-idf

4)word2vec
- 統計特徵

- 組合特徵

以下圖為例:利用GBDT得到一棵樹,其中每若干個分枝都可以組合為一個特徵,例如:男-上海(利用2個分支組合了一個特徵,其中“男/上海”分別為各個分支分叉的condition)。類似的,也可以利用3個,或者更多的分支結點,組合為一個特徵。

三、特徵選擇
- 過濾型

- 包裹型

- 嵌入型

四、others
1、歸一化:對行進行處理(single sample);
標準化:對列進行處理(single feature);
2、剔除outlier
利用“分位數”剔除outlier,如:選取1/4 - 3/4的資料,剔除其它資料;
3、missing value的處理
1)利用prediction填充missing value;
2)利用mean 填充missing value;
3)利用median 填充missing value;(median比mean更接近資料正常值?)