
python_scrapy爬蟲_jieba分詞_資料視覺化 階段總結報告
第一次寫於 20170328 23:36 寢室
序言
關鍵詞:
python scrapy爬蟲 搜狗微信 jieba分詞 資料視覺化 wordcloud_plotly
我完成的完整工程檔案:
正文
這段時間學習的內容就是python爬蟲、分詞、以及資料視覺化;以爬取‘搜狗微信’中的微信熱門文章為例分析;這個小工程我將其分成三個部分:
- 獲取資料:使用python scrapy框架定製爬蟲,爬取網站資料 並存入Mysql資料庫
- 處理資料:使用python jieba分詞模組,處理Mysql資料庫中儲存的微信文字並存入Mysql
- 資料視覺化:使用plotly 和 wordcloud 將分詞資料視覺化
- 寫總結
第一步中:scrapy資料比較多,勉強能做個能用的爬蟲,程式碼模組化目前寫的很亂,由於前個星期寫的這個python檔案,當時遇到的問題沒有記錄,在此就不多說;
部分程式碼 weixin_TextSpider類
# -*- coding: utf-8 -*-
# @Time : 2017/03/21 10:54
# @Author : RenjiaLu
import time
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from scrapy.selector import Selector
from 爬蟲運行了十幾次,每次爬一遍‘搜狗微信 http://weixin.sogou.com/’,只能得到5k左右的文章,而且每隔兩小時文章更新數量只有幾百篇;所以我在三天的時間裡共執行十幾次,獲取文章 89990篇文章;去重後剩下15667篇
基於這15k篇原始資料開始分析;
資料庫建表如下:

四個檢視:

第一個檢視棄用;
第二個檢視:從 t_splitwords,和 weixin_text 兩個表中按weixinText分類板塊分組,並按frequency大小排序;可以檢視每個分類板塊 最多重複出現的詞
第三個檢視:weixin_Text 去重後的檢視,去重條件如下:weixin_text.classifyKind, weixin_text.title, weixin_text.name_GZH, weixin_text.summary 根據這四個欄位選出 不重複獨一無二的 weixinText
第四個檢視:表 t_splitwords(100w 條資料) 去重 並統計重複次數 以t_splitwords.value, t_splitwords.titleOrSummary, t_splitwords.partOfSpeech三個欄位分組
其中 t_splitwords表資料量達到 100w ,一條簡單的查詢語句要執行幾十秒,第一次接觸這個量級,不得不開始注意資料庫的查詢優化
#encoding=utf-8
import jieba
seg_list = jieba.cut("我來到北京清華大學",cut_all=True)
print "Full Mode:", "/ ".join(seg_list) #全模式
seg_list = jieba.cut("我來到北京清華大學",cut_all=False)
print "Default Mode:", "/ ".join(seg_list) #精確模式
seg_list = jieba.cut("他來到了網易杭研大廈") #預設是精確模式
print ", ".join(seg_list)
seg_list = jieba.cut_for_search("小明碩士畢業於中國科學院計算所,後在日本京都大學深造") #搜尋引擎模式
print ", ".join(seg_list)輸出
【全模式】: 我/ 來到/ 北京/ 清華/ 清華大學/ 華大/ 大學
【精確模式】: 我/ 來到/ 北京/ 清華大學
【新詞識別】:他, 來到, 了, 網易, 杭研, 大廈 (此處,“杭研”並沒有在詞典中,但是也被Viterbi演算法識別出來了)
【搜尋引擎模式】: 小明, 碩士, 畢業, 於, 中國, 科學, 學院, 科學院, 中國科學院, 計算, 計算所, 後, 在, 日本, 京都, 大學, 日本京都大學, 深造部分程式碼:utils_parseString.py 解析從mysql獲取的微信文字並再次存入mysql
# -*- coding: utf-8 -*-
# @Time : 2017/03/22 15:54
# @Author : RenjiaLu
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import jieba
import jieba.posseg
from utils_mysql import *
def parseAndSaveString(string,titleOrSummary,stringId,db):
"""parse"""
try:
seg_list = jieba.cut(string,cut_all=True)
except Exception as e:
myException("###1全模式分詞","stringId:%d titleOrSummary:%s string:%s"%(stringId,titleOrSummary,string),e)
return
else:
"""第一次分詞成功"""
for a_seg in seg_list:
if '' == a_seg:
continue
try:
# posseg_list = jieba.posseg.cut(a_seg)
posseg_list = a_seg
except Exception as e:
myException("###2詞性分詞","stringId:%d titleOrSummary:%s string:%s a_seg:%s"%(stringId,titleOrSummary,string,a_seg),e)
continue
else:
"""第二次分詞成功"""
for posseg_word in posseg_list:
if '' == posseg_word:
continue
# print posseg_word.word,posseg_word.flag
print posseg_word
try:
# indexOfString = string.find(posseg_word.word)
# partOfSpeech = posseg_word.flag
indexOfString = string.find(posseg_word)
partOfSpeech = "-"
"""save"""
# SQLsttmnt = "INSERT INTO t_splitwords VALUE (\'%s\',\'%s\',%d,%d,\'%s\',\'%s\') ;" \
# %("NULL",posseg_word.word,stringId,indexOfString,titleOrSummary,partOfSpeech)
SQLsttmnt = "INSERT INTO t_splitwords VALUE (\'%s\',\'%s\',%d,%d,\'%s\',\'%s\') ;" \
%("NULL",posseg_word,stringId,indexOfString,titleOrSummary,partOfSpeech)
cursor = executeMysqlSttmnt(db,SQLsttmnt)
except Exception as e:
myException("###構造資料並儲存","stringId:%d titleOrSummary:%s string:%s posseg_word" \
":%s"%(stringId,titleOrSummary,string,posseg_word),e)
continue
else:
pass
finally:
pass
部分程式碼:utils_mysql.py 連線資料庫工具函式集合
# -*- coding: utf-8 -*-
# @Time : 2017/03/22 16:54
# @Author : RenjiaLu
import time
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import MySQLdb
str = time.strftime('%Y_%m_%d__%H_%M_%S',time.localtime(time.time()))
outputfile = open("log/log_%s.txt"%str, "a+")
def cnnctMysql(pHost="localhost",pUser="root",pPasswd="",pDb="db_weixin",pPort=3306,pCharset='utf8'):
"""連線 mysql 資料庫"""
try:
db = MySQLdb.connect(host=pHost,user= pUser,passwd=pPasswd,db=pDb,port=pPort,charset=pCharset)
db.autocommit(1)
return db
except Exception as e:
myException("###連線資料庫","",e)
else:
print '操作成功'
finally:
pass
def executeMysqlSttmnt(db,sqlSttmnt):
"""執行 mysql 語句
返回 cursor
"""
try:
cursor = db.cursor()
cursor.execute(sqlSttmnt)
return cursor
except Exception as e:
myException("###執行Mysql語句",sqlSttmnt,e)
db.rollback() # 回滾事件
else:
print '操作成功'
finally:
pass
def closeMysql(db):
"""關閉資料庫"""
try:
db.close()
except Exception as e:
myException("###關閉資料庫","",e)
else:
print '操作成功'
finally:
pass
def myException(whichStep,log,e):
str = "###myException whichstep:%s log:%s e:%s\n"%(whichStep,log,e)
print str
try:
outputfile.write(str)
except Exception as e:
print e使用很簡單,我先全模式分詞再對其做詞性分析,這裡有重複分詞的問題,這也是資料量這麼大的原因,重複次數最多的都是單字,所以後面的視覺化操作我略去了單字詞條,只分析兩個字元及以上的詞
第三步: 資料視覺化,
plotly資料視覺化效果真不錯,雖然看了官網也沒有找到詳細的屬性介紹,目前只使用了其中bar類圖
# -*- coding: utf-8 -*-
# @Time : 2017/03/26 08:54
# @Author : RenjiaLu
import plotly.plotly as py
import plotly.graph_objs as go
import plotly.offline
from plotly.graph_objs import *
# Generate the figure
import plotly.plotly as py
import plotly.graph_objs as go
list_articalClssfy= ['熱門', '推薦', '段子手','養身堂','私房話',\
'八卦精','愛生活','財經迷','汽車迷','科技咖',\
'潮人幫','辣媽幫','點贊黨','旅行家','職場人',\
'美食家','古今通','學霸族','星座控','體育迷']
list_articalNum = [904,854,842,907,639,\
1041,676,966,773,1011,\
1005,850,720,624,540,\
720,729,586,377,903]
# frequency >= 5
list_articalWordsNum=[1584,1645,1182,1810,1006,\
1877,1241,1983,1525,1957,\
1708,1477,1180,1169,1086,\
1358,1347,1261,627,1751]
trace_articalNum = go.Bar(
x=list_articalClssfy,
y=list_articalNum,
name='爬取文章數'
)
trace__articalWordsNum = go.Bar(
x=list_articalClssfy,
y=list_articalWordsNum,
name='文章分詞數'
)
data = [trace_articalNum, trace__articalWordsNum]
layout = go.Layout(
barmode='stack',
title="data_to_view_1 爬取文章數量與分詞數量(frequency>=5)"
)
fig = go.Figure(data=data, layout=layout)
plotly.offline.plot(fig, filename = 'view_html/data_to_view_1.html')
#py.iplot(fig, filename='grouped-bar')然後抽取這二十個分類板塊中頻度前十的詞分析
這裡取其中的三個分類,如圖

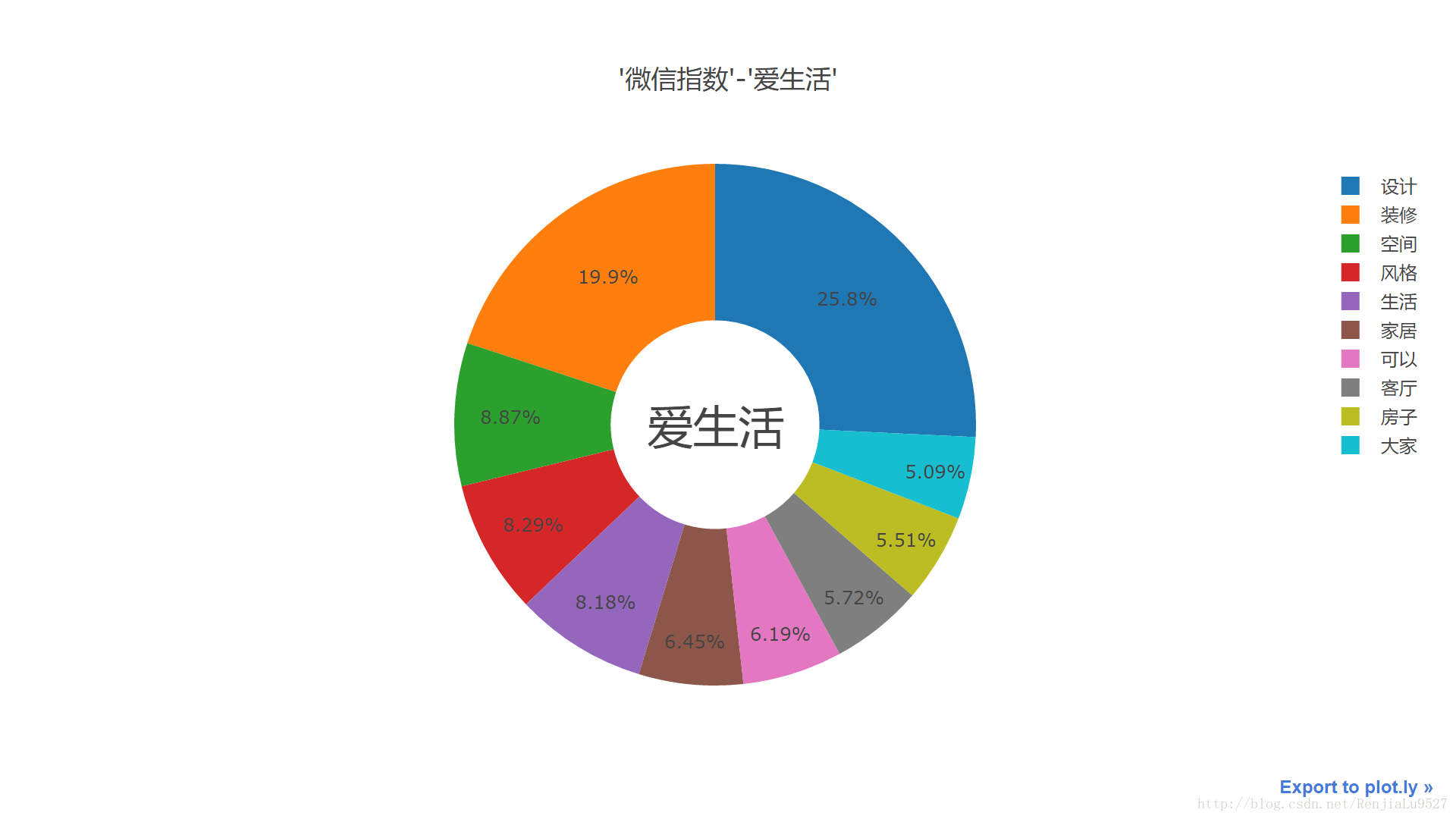

程式碼已上傳 github,見文章開頭
詞雲 wordcloud 模組 genWordCloud.py
# -*- coding: utf-8 -*-
# @Time : 2017/03/25 19:54
# @Author : RenjiaLu
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import os
import matplotlib.pyplot as plt
from os import path
from scipy.misc import imread
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import locale
def genWordCloud(dict_data,rootPath = path.dirname(__file__),imgName="ico1.jpg",saveFileName="wordcloud_init.png"):
#設定語言
locale.setlocale(locale.LC_ALL, 'chs')
#字型檔案路徑
fontPath = "H:/Python27/python_workplace/dataToview/font/msyh.ttc"
#當前工程檔案目錄
d = rootPath
# 設定背景圖片
alice_coloring = imread(path.join(d, imgName))
#構建詞雲框架 並載入資料
wc = WordCloud(font_path = fontPath,#字型
background_color="white", #背景顏色
max_words=10000,# 詞雲顯示的最大詞數
mask=alice_coloring,#設定背景圖片
#stopwords=STOPWORDS.add("said"),
width=900,
height=600,
scale=4.0,
max_font_size=200, #字型最大值
random_state=42).fit_words(dict_data)
#載入 DICT 資料
#wc.generate_from_frequencies(dict_data)
#從背景圖片生成顏色值
image_colors = ImageColorGenerator(alice_coloring)
# 以下程式碼顯示圖片
plt.imshow(wc)
plt.axis("off")
plt.show()
#儲存圖片
wc.to_file(path.join(d,saveFileName))
pass最後
熟悉了一遍流程:
爬蟲找資料-mysql建表建檢視優化存取資料-python分析資料視覺化操作
20170329 11:39
end