
SparkStreaming 解析Kafka JSON格式資料
SparkStreaming 解析Kafka JSON格式資料
專案記錄:在專案中,SparkStreaming整合Kafka時,通常Kafka傳送的資料是以JSON字串形式傳送的,這裡總結了五種SparkStreaming解析Kafka中JSON格式資料並轉為DataFrame進行資料分析的方法。
需求:將如下JSON格式的資料

轉成如下所示的DataFrame

1 使用Python指令碼建立造數器
隨機生成如上圖所示的JSON格式的資料,並將它傳送到Kafka。造數器指令碼程式碼如下所示:
kafka_data_generator.py
"""
造數器:向kafka傳送json格式資料
資料格式如下所示:
{
"namespace":"000001",
"region":"Beijing",
"id":"9d58f83e-fb3b-45d8-b7e4-13d33b0dd832",
"valueType":"Float",
"value":"48.5",
"time":"2018-11-05 15:04:47"
}
"""
import uuid
import time
import random
from pykafka import KafkaClient
import json
sample_type = 檢視kafka topic 中是否包含資料:
sh kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic spark_streaming_kafka_json --from-beginning

2 Spark Streaming 處理JSON格式資料
2.1 方法一:處理JSON字串為case class 生成RDD[case class] 然後直接轉成DataFrame
思路:Spark Streaming從Kafka讀到資料後,先通過自定義的handleMessage2CaseClass方法進行一次轉換,將JSON字串轉換成指定格式的case class:[KafkaMessage],然後通過foreachRDD拿到RDD[KafkaMessage]型別的的rdd,最後直接通過spark.createDataFrame(RDD[KafkaMessage])。思路來源如下圖所示:
核心程式碼:
/**
* 方法一:處理JSON字串為case class 生成RDD[case class] 然後直接轉成DataFrame
*/
stream.map(record => handleMessage2CaseClass(record.value())).foreachRDD(rdd => {
val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
val df = spark.createDataFrame(rdd)
df.show()
})
handleMessage2CaseClass方法:
def handleMessage2CaseClass(jsonStr: String): KafkaMessage = {
val gson = new Gson()
gson.fromJson(jsonStr, classOf[KafkaMessage])
}
Case Class:
case class KafkaMessage(time: String, namespace: String, id: String, region: String, value: String, valueType: String)
依賴:
<!-- https://mvnrepository.com/artifact/com.google.code.gson/gson -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.5</version>
</dependency>
2.2 方法二:處理JSON字串為Tuple 生成RDD[Tuple] 然後轉成DataFrame
思路:此方法的思路與方法一的思路相同,只不過不轉為Case Class 而是轉為Tuple,思路來源如下圖所示:

核心程式碼:
/**
* 方法二:處理JSON字串為Tuple 生成RDD[Tuple] 然後轉成DataFrame
*/
stream.map(record => handleMessage2Tuples(record.value())).foreachRDD(rdd => {
val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
val df = rdd.toDF("id", "value", "time", "valueType", "region", "namespace")
df.show()
})
handleMessage2Tuples方法:
def handleMessage2Tuples(jsonStr: String): (String, String, String, String, String, String) = {
import scala.collection.JavaConverters._
val list = JSON.parseObject(jsonStr, classOf[JLinkedHashMap[String, Object]]).asScala.values.map(x => String.valueOf(x)).toList
list match {
case List(v1, v2, v3, v4, v5, v6) => (v1, v2, v3, v4, v5, v6)
}
}
2.3 方法三:處理JSON字串為Row 生成RDD[Row] 然後通過schema建立DataFrame
思路:SparkStreaming從kafka讀到資料之後,先通過handlerMessage2Row自定義的方法,將JSON字串轉成Row型別,然後通過foreachRDD拿到RDD[Row]型別的RDD,最後通過Spark.createDataFrame(RDD[Row],Schema)生成DataFrame,思路來源:

核心程式碼:
/**
* 方法三:處理JSON字串為Row 生成RDD[Row] 然後通過schema建立DataFrame
*/
val schema = StructType(List(
StructField("id", StringType),
StructField("value", StringType),
StructField("time", StringType),
StructField("valueType", StringType),
StructField("region", StringType),
StructField("namespace", StringType))
)
stream.map(record => handlerMessage2Row(record.value())).foreachRDD(rdd => {
val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
val df = spark.createDataFrame(rdd, schema)
df.show()
})
handlerMessage2Row方法:
def handlerMessage2Row(jsonStr: String): Row = {
import scala.collection.JavaConverters._
val array = JSON.parseObject(jsonStr, classOf[JLinkedHashMap[String, Object]]).asScala.values.map(x => String.valueOf(x)).toArray
Row(array: _*)
}
2.4 方法四:直接將 RDD[String] 轉成DataSet 然後通過schema轉換
思路:直接通過foreachRDD拿到RDD[String]型別的RDD,然後通過spark.createDataSet(RDD[String])方法生成只含有一列value列的DataSet,然後通過Spark SQL 內建函式 from_json格式化json字串,然後取每一列的值生成DataFrame。思路來源:


核心程式碼:
/**
* 方法四:直接將 RDD[String] 轉成DataSet 然後通過schema轉換
*/
val schema = StructType(List(
StructField("namespace", StringType),
StructField("id", StringType),
StructField("region", StringType),
StructField("time", StringType),
StructField("value", StringType),
StructField("valueType", StringType))
)
stream.map(record => record.value()).foreachRDD(rdd => {
val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
val ds = spark.createDataset(rdd)
ds.select(from_json('value.cast("string"), schema) as "value").select($"value.*").show()
})
2.5 方法五:直接將 RDD[String] 轉成DataSet 然後通過read.json轉成DataFrame
思路:直接通過foreachRDD拿到RDD[String]型別的RDD,然後通過spark.createDataSet建立DataSet,最後通過spark.read.json(DataSet[String])方法來建立DataFrame。此方法程式碼量最小,不需要指定schema,不需要進行json轉換。思路來源:

核心程式碼:
/**
* 方法五:直接將 RDD[String] 轉成DataSet 然後通過read.json轉成DataFrame
*/
stream.map(record => record.value()).foreachRDD(rdd => {
val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
val df = spark.read.json(spark.createDataset(rdd))
df.show()
})
3 對生成的DataFrame進行分析
通過上面方法我們已經可以拿到一個如期所欲的DataFrame了,接下來就是使用Spark SQL 對資料進行分析處理。
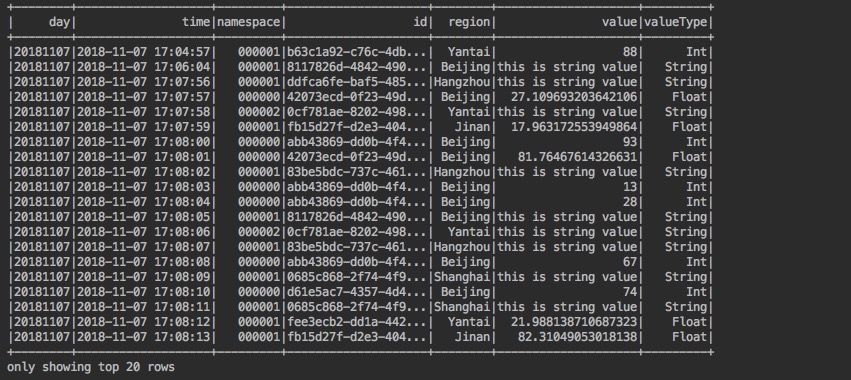
3.1 需求1:將time列的時間由原來的2018-11-07 17:08:43字串格式,轉成:yyyyMMdd這種格式,生成新的列,並命名為day列。
實現程式碼:
import org.apache.spark.sql.functions._
import spark.implicits._
df.select(date_format($"time".cast(DateType), "yyyyMMdd").as("day"), $"*").show()
結果:
3.2 需求2:按照Day列和namespae列進行分割槽,並儲存到檔案。
實現程式碼:
df.write.mode(SaveMode.Append)
.partitionBy("namespace", "time")
.parquet("/Users/shirukai/Desktop/HollySys/Repository/learn-demo-spark/data/Streaming")
結果:

4 一些思考?
4.1 思考1:如果json格式為[]陣列該如何處理?
上面我們處理的json字串都是{}都是物件格式的,那麼如果Kafka裡的資料是以[]陣列字串的格式儲存的,那麼我們該如何處理呢?
這裡暫且提供兩種方法:
4.1.1 第一種:通過handleMessage自定義方法處理JSON字串為Array[case class],然後通過flatmap展開,再通過foreachRDD拿到RDD[case class]格式的RDD,最後直接轉成DataFrame。
handleMessage方法:
def handleMessage(jsonStr: String): Array[KafkaMessage] = {
val gson = new Gson()
gson.fromJson(jsonStr, classOf[Array[KafkaMessage]])
}
核心程式碼:
/**
* 補充:處理[]陣列格式的json字串,方法一:通過handleMessage自定義方法處理JSON字串為Array[case class],
* 然後通過flatmap展開,再通過foreachRDD拿到RDD[case class]格式的RDD,最後直接轉成DataFrame。
*/
stream.map(record => handleMessage(record.value())).flatMap(_).foreachRDD(rdd => {
val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
val df = spark.createDataFrame(rdd)
df.show()
})
4.1.2 第二種:直接處理RDD[String],建立DataSet,然後通過Spark SQL 內建函式from_json和指定的schema格式化json資料,然後再通過內建函式explode展開陣列格式的json資料,最後通過select json中的每一個key,獲得最終的DataFrame
核心程式碼:
/**
* 補充:處理[]陣列格式的json字串,方法二:第二種:直接處理RDD[String],建立DataSet,
* 然後通過Spark SQL 內建函式from_json和指定的schema格式化json資料,
* 再通過內建函式explode展開陣列格式的json資料,最後通過select json中的每一個key,獲得最終的DataFrame
*/
val schema = StructType(List(
StructField("namespace", StringType),
StructField("id", StringType),
StructField("region", StringType),
StructField("time", StringType),
StructField("value", StringType),
StructField("valueType", StringType))
)
stream.map(record => record.value()).foreachRDD(rdd => {
val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
val ds = spark.createDataset(rdd)
import org.apache.spark.sql.functions._
val df = ds.select(from_json('value, ArrayType(schema)) as "value").select(explode('value)).select($"col.*")
df.show()
})
4.2 思考2:如果使用StructStreaming該如何處理json資料?
StructStreaming是一個結構式流,實際拿到的就是一個DataFrame,所以可以使用上面的第四種方法來解析json資料。
package com.hollysys.spark.streaming.kafkajson
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.{date_format, from_json, struct}
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.types._
/**
* Created by shirukai on 2018/11/8
* 使用Struct Streaming 處理 kafka中json格式的資料
*/
object HandleJSONDataByStructStreaming {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName(this.getClass.getSimpleName)
.master("local[2]")
.getOrCreate()
val source = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "spark_streaming_kafka_json")
.option("startingOffsets", "earliest")
.option("failOnDataLoss", "false")
.load()
import spark.implicits._
val schema = StructType(List(
StructField("id", StringType),
StructField("value", StringType),
StructField("time", StringType),
StructField("valueType", StringType),
StructField("region", StringType),
StructField("namespace", StringType))
)
val data = source.select(from_json('value.cast("string"), schema) as "value").select($"value.*")
.select(date_format($"time".cast(DateType), "yyyyMMdd").as("day"), $"*")
val query = data
.writeStream
.format("parquet")
.outputMode("Append")
.option("checkpointLocation", "/Users/shirukai/Desktop/HollySys/Repository/learn-demo-spark/data/checkpoint")
.option("path", "/Users/shirukai/Desktop/HollySys/Repository/learn-demo-spark/data/structstreaming")
.trigger(Trigger.ProcessingTime(3000)).partitionBy("namespace", "day")
.start()
query.awaitTermination()
}
}
結果:

完整程式碼:
package com.hollysys.spark.streaming.kafkajson
import com.alibaba.fastjson.JSON
import com.google.gson.Gson
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Row, SaveMode, SparkSession}
import org.apache.spark.sql.types._
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.{Seconds, StreamingContext}
import java.util.{LinkedHashMap => JLinkedHashMap}
/**
* Created by shirukai on 2018/11/7
* Spark Streaming 處理 kafka json格式資料,並轉成DataFrame
*/
object JSONDataHandler {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("JSONDataHandler")
val ssc = new StreamingContext(conf, Seconds(2))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "spark_streaming",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("spark_streaming_kafka_json")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
/**
* 方法一:處理JSON字串為case class 生成RDD[case class] 然後直接轉成DataFrame
*/
stream.map(record => handleMessage2CaseClass(record.value())).foreachRDD(rdd => {
val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
val df = spark.createDataFrame(rdd)
import org.apache.spark.sql.functions._
import spark.implicits._
df.select(date_format($"time".cast(DateType), "yyyyMMdd").as("day"), $"*")
.write.mode(SaveMode.Append)
.partitionBy("namespace", "day")
.parquet("/Users/shirukai/Desktop/HollySys/Repository/learn-demo-spark/data/Streaming")
})
/**
* 方法二:處理JSON字串為Tuple 生成RDD[Tuple] 然後轉成DataFrame
*/
// stream.map(record => handleMessage2Tuples(record.value())).foreachRDD(rdd => {
// val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
// import spark.implicits._
// val df = rdd.toDF("id", "value", "time", "valueType", "region", "namespace")
// df.show()
// })
/**
* 方法三:處理JSON字串為Row 生成RDD[Row] 然後通過schema建立DataFrame
*/
// val schema = StructType(List(
// StructField("id", StringType),
// StructField("value", StringType),
// StructField("time", StringType),
// StructField("valueType", StringType),
// StructField("region", StringType),
// StructField("namespace", StringType))
// )
// stream.map(record => handlerMessage2Row(record.value())).foreachRDD(rdd => {
// val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
// val df = spark.createDataFrame(rdd, schema)
// df.show()
// })
/**
* 方法四:直接將 RDD[String] 轉成DataSet 然後通過schema轉換
*/
// val schema = StructType(List(
// StructField("namespace", StringType),
// StructField("id", StringType),
// StructField("region", StringType),
// StructField("time", StringType),
// StructField("value", StringType),
// StructField("valueType", StringType))
// )
// stream.map(record => record.value()).foreachRDD(rdd => {
// val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
// import spark.implicits._
// val ds = spark.createDataset(rdd)
// ds.select(from_json('value.cast("string"), schema) as "value").select($"value.*").show()
// })
/**
* 方法五:直接將 RDD[String] 轉成DataSet 然後通過read.json轉成DataFrame
*/
// stream.map(record => record.value()).foreachRDD(rdd => {
// val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
// import spark.implicits._
// val df = spark.read.json(spark.createDataset(rdd))
// df.show()
// })
/**
* 補充:處理[]陣列格式的json字串,方法一:通過handleMessage自定義方法處理JSON字串為Array[case class],
* 然後通過flatmap展開,再通過foreachRDD拿到RDD[case class]格式的RDD,最後直接轉成DataFrame。
*/
// stream.map(record => handleMessage(record.value())).flatMap(_).foreachRDD(rdd => {
// val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
// val df = spark.createDataFrame(rdd)
// df.show()
// })
/**
* 補充:處理[]陣列格式的json字串,方法二:第二種:直接處理RDD[String],建立DataSet,
* 然後通過Spark SQL 內建函式from_json和指定的schema格式化json資料,
* 再通過內建函式explode展開陣列格式的json資料,最後通過select json中的每一個key,獲得最終的DataFrame
*/
// val schema = StructType(List(
// StructField("namespace", StringType),
// StructField("id", StringType),
// StructField("region", StringType),
// StructField("time", StringType),
// StructField("value", StringType),
// StructField("valueType", StringType))
// )
// stream.map(record => record.value()).foreachRDD(rdd => {
// val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
// import spark.implicits._
// val ds = spark.createDataset(rdd)
// import org.apache.spark.sql.functions._
// val df = ds.select(from_json('value, ArrayType(schema)) as "value").select(explode('value)).select($"col.*")
// df.show()
// })
ssc.start()
ssc.awaitTermination()
}
def handleMessage(jsonStr: String): Array[KafkaMessage] = {
val gson = new Gson()
gson.fromJson(jsonStr, classOf[Array[KafkaMessage]])
}
def handleMessage2CaseClass(jsonStr: String): KafkaMessage = {
val gson = new Gson()
gson.fromJson(jsonStr, classOf[KafkaMessage])
}
def handleMessage2Tuples(jsonStr: String): (String, String, String, String, String, String) = {
import scala.collection.JavaConverters._
val list = JSON.parseObject(jsonStr, classOf[JLinkedHashMap[String, Object]]).asScala.values.map(x => String.valueOf(x)).toList
list match {
case List(v1, v2, v3, v4, v5, v6) => (v1, v2, v3, v4, v5, v6)
}
}
def handlerMessage2Row(jsonStr: String): Row = {
import scala.collection.JavaConverters._
val array = JSON.parseObject(jsonStr, classOf[JLinkedHashMap[String, Object]]).asScala.values.map(x => String.valueOf(x)).toArray
Row(array: _*)
}
}
case class KafkaMessage(time: String, namespace: String, id: String, region: String, value: String, valueType: String)
總結
目前只想到了上面五種方法,如果有其它思路後續會補上。對比這五種方法,不考慮效能問題,從程式碼量和靈活度來看,第五種方法是比較好的,因為不需要我們指定schema資訊。其次是第一種,不過需要事先定義好case class。另外,在上面的前三種方法中,我們都用到了將json轉換成不同物件的方法,但是第一種用的是谷歌的gson後兩種用的是阿里的fastjson。是因為,建立DataFrame的時候只支援case class,而當我們使用fastjson的JSON.pares(jsonStr,classOf[KafkaMessage])時會報錯,因為fastjson無法將json字串轉成case class物件。所以這裡選用的gson。