Python+Selenium練習篇之1-摘取網頁上全部郵箱
前面已經介紹了Python+Selenium基礎篇,通過前面幾篇文章的介紹和練習,Selenium+Python的webUI自動化測試算是入門了。接下來,我計劃寫第二個系列:練習篇,通過一些練習,瞭解和掌握一些Selenium常用的介面或者方法。
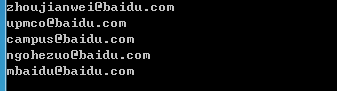
練習場景:在某一個網頁上有些欄位是我們感興趣的,我們希望摘取出來,進行其他操作。但是這些欄位可能在一個網頁的不同地方。例如,我們需要在關於百度頁面-聯絡我們,摘取全部的郵箱。
思路拆分:
1. 首先,需要得到當前頁面的source內容,就像,開啟一個頁面,右鍵-檢視頁面原始碼。
2. 找出規律,通過正則表示式去摘取匹配的欄位,儲存到一個字典或者列表。
3. 迴圈列印字典或列表中內容,Python中用 for 語句實現。
技術角度實現相關方法:
1. 檢視頁面的原始碼,在Selenium中有driver.page_source 這個方法得到
2. Python中利用正則,需要匯入re模組
3. for email in emails :
print email
想法技術角度方法都找到,我們新建一個extract_email.py 檔案,輸入如下程式碼:
# coding=utf-8
from selenium import webdriver
import re
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(6)
driver.get("http://home.baidu.com/contact.html")
# 得到頁面原始碼
doc = driver.page_source
emails = re.findall(r'[\w][email protected][\w\.-]+',doc) # 利用正則,找出 [email protected]
# 迴圈列印匹配的郵箱
for email in emails:
print (email)
解釋:
在python正則表示式語法中,Python中字串前面加上 r 表示原生字串,用\w表示匹配字母數字及下劃線。re模組下findall方法返回的是一個匹配子字串的列表。
執行結果: