
spark多種執行模式【基於原理講述】
1. 本地模式
該模式被稱為Local[N]模式,是用單機的多個執行緒來模擬Spark分散式計算,通常用來驗證開發出來的應用程式邏輯上有沒有問題。
其中N代表可以使用N個執行緒,每個執行緒擁有一個core。如果不指定N,則預設是1個執行緒(該執行緒有1個core)。
如果是local[*],則代表 Run Spark locally with as many worker threads as logical cores on your machine.
如下:
spark-submit 和 spark-submit –master local 效果是一樣的
(同理:spark-shell 和 spark-shell –master local 效果是一樣的)
spark-submit –master local[4] 代表會有4個執行緒(每個執行緒一個core)來併發執行應用程式。
那麼,這些執行緒都執行在什麼程序下呢?後面會說到,請接著往下看。
執行該模式非常簡單,只需要把Spark的安裝包解壓後,改一些常用的配置即可使用,而不用啟動Spark的Master、Worker守護程序( 只有叢集的Standalone方式時,才需要這兩個角色),也不用啟動Hadoop的各服務(除非你要用到HDFS),這是和其他模式的區別哦,要記住才能理解。
那麼,這些執行任務的執行緒,到底是共享在什麼程序中呢?
我們用如下命令提交作業:
spark-submit –class org.apache.spark.examples.JavaWordCount –master local[*] spark-examples_2.11-2.3.1.jar file:///opt/README.md
可以看到,在程式執行過程中,只會生成一個SparkSubmit程序。
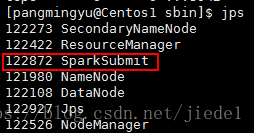
這個SparkSubmit程序又當爹、又當媽,既是客戶提交任務的Client程序、又是Spark的driver程式、還充當著Spark執行Task的Executor角色。(如下圖所示:driver的web ui)

這裡有個小插曲,因為driver程式在應用程式結束後就會終止,那麼如何在web介面看到該應用程式的執行情況呢,需要如此這般:(如下圖所示)
先在spark-env.sh 增加SPARK_HISTORY_OPTS;
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080
-Dspark.history.retainedApplications=3
-Dspark.history.fs.logDirectory=hdfs://192.168.5.60:9000/history"然後啟動start-history-server.sh服務;
就可以看到啟動了HistoryServer程序,且監聽埠是18080。
之後就可以在web上使用http://hostname:18080愉快的玩耍了。
2,測試或實驗性質的本地偽叢集執行模式(單機模擬叢集)
這種執行模式,和Local[N]很像,不同的是,它會在單機啟動多個程序來模擬叢集下的分散式場景,而不像Local[N]這種多個執行緒只能在一個程序下委屈求全的共享資源。通常也是用來驗證開發出來的應用程式邏輯上有沒有問題,或者想使用Spark的計算框架而沒有太多資源。
用法是:提交應用程式時使用local-cluster[x,y,z]引數:x代表要生成的executor數,y和z分別代表每個executor所擁有的core和memory數。
spark-submit –master local-cluster[2, 3, 1024]
(同理:spark-shell –master local-cluster[2, 3, 1024]用法也是一樣的)
上面這條命令代表會使用2個executor程序,每個程序分配3個core和1G的記憶體,來執行應用程式。可以看到,在程式執行過程中,會生成如下幾個程序:
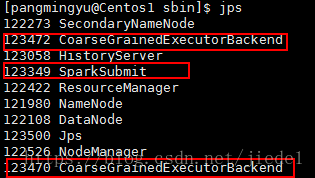
SparkSubmit依然充當全能角色,又是Client程序,又是driver程式,還有點資源管理的作用。生成的兩個CoarseGrainedExecutorBackend,就是用來併發執行程式的程序。它們使用的資源如下:

執行該模式依然非常簡單,只需要把Spark的安裝包解壓後,改一些常用的配置即可使用。而不用啟動Spark的Master、Worker守護程序( 只有叢集的standalone方式時,才需要這兩個角色),也不用啟動Hadoop的各服務(除非你要用到HDFS),這是和其他模式的區別哦,要記住才能理解。下面說說叢集上的執行模式。
3,Spark自帶Cluster Manager的Standalone Client模式(叢集)
終於說到了體現分散式計算價值的地方了!(有了前面的基礎,後面的內容我會稍微說快一點,只講本文的關注點)
和單機執行的模式不同,這裡必須在執行應用程式前,先啟動Spark的Master和Worker守護程序。不用啟動Hadoop服務,除非你用到了HDFS的內容。
start-master.sh
start-slave.sh -h hostname url:master
圖省事,可以在想要做為Master的節點上用start-all.sh一條命令即可,不過這樣做,和上面的分開配置有點差別,以後講到資料本地性如何驗證時會說。
啟動的程序如下:(其他非Master節點上只會有Worker程序)
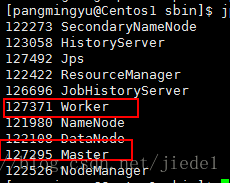
這種執行模式,可以使用Spark的8080 web ui來觀察資源和應用程式的執行情況了。利用8080埠。
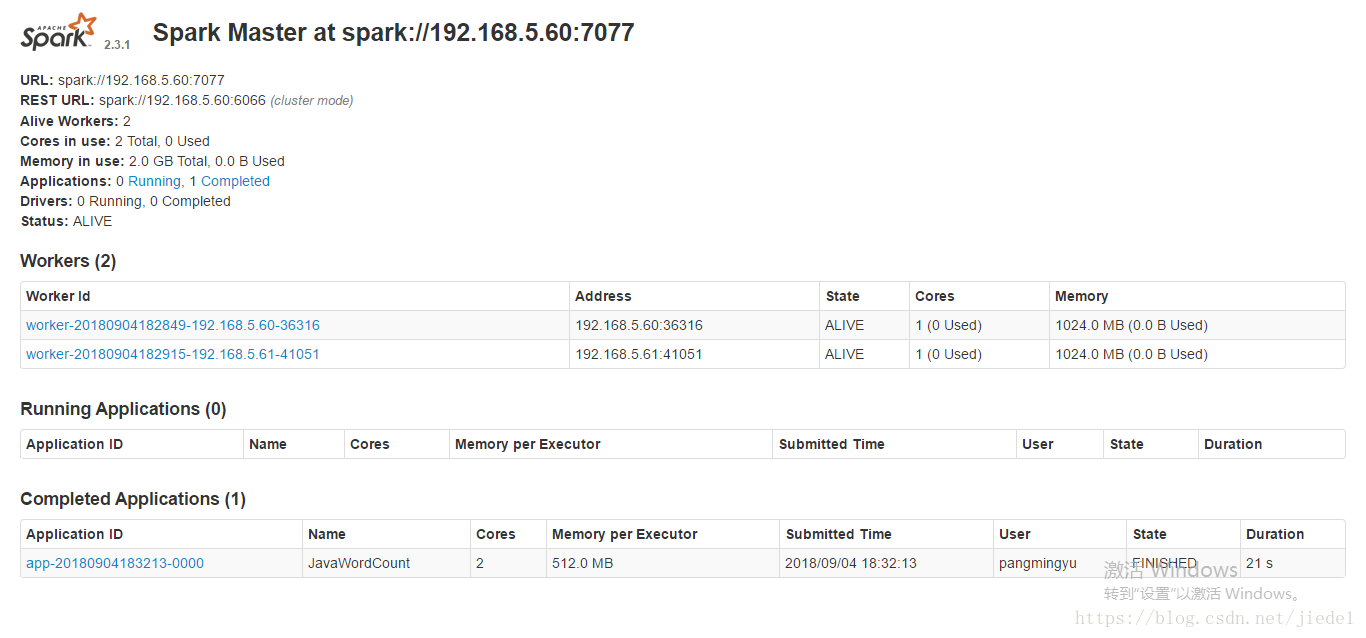
可以看到,當前環境下,我啟動了2個worker程序,每個worker可使用的core是1個,記憶體1024M。
言歸正傳,用如下命令提交應用程式
spark-submit –master spark://wl1:7077
或者 spark-submit –master spark://wl1:7077 –deploy-mode client
代表著會在所有有Worker程序的節點上啟動Executor來執行應用程式,此時產生的JVM程序如下:(非master節點,除了沒有Master、SparkSubmit,其他程序都一樣)
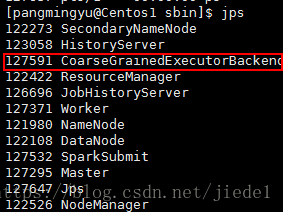
Master程序做為cluster manager,用來對應用程式申請的資源進行管理;
SparkSubmit 做為Client端和執行driver程式;
CoarseGrainedExecutorBackend 用來併發執行應用程式;
注意,Worker程序生成幾個Executor,每個Executor使用幾個core,這些都可以在spark-env.sh裡面配置,此處不在囉嗦。
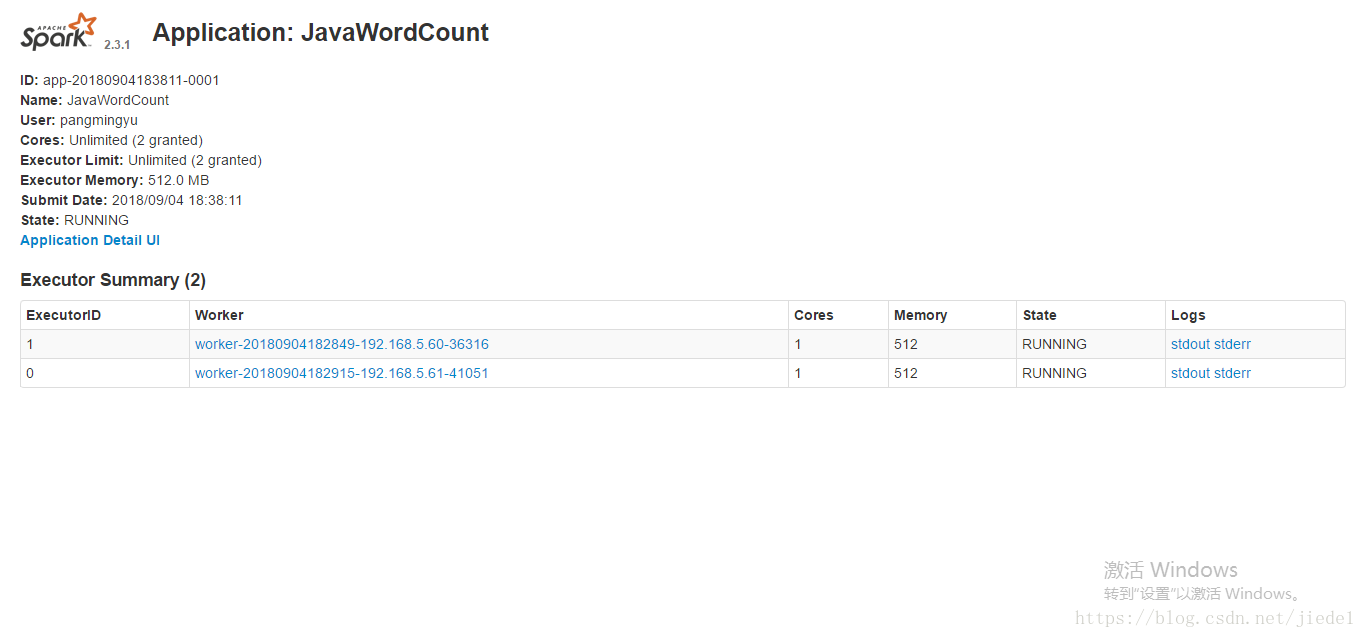
這是driver web ui的顯示,可以看到每個executor的資源使用情況
4,spark自帶cluster manager的standalone cluster模式(叢集)
這種執行模式和上面第3個還是有很大的區別的。使用如下命令執行應用程式(前提是已經啟動了spark的Master、Worker守護程序)不用啟動Hadoop服務,除非你用到了HDFS的內容。
spark-submit –master spark://wl1:6066 –deploy-mode cluster
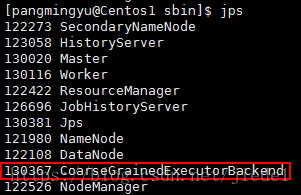
各節點啟動的JVM程序情況如下:
master節點上的程序
提交應用程式的客戶端上的程序
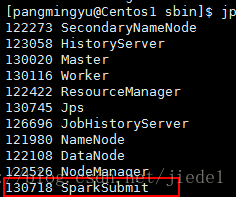
客戶端的SparkSubmit程序會在應用程式提交給叢集之後就退出(區別1)
Master會在叢集中選擇一個Worker程序生成一個子程序DriverWrapper來啟動driver程式(區別2)
而該DriverWrapper 程序會佔用Worker程序的一個core,所以同樣的資源下配置下,會比第3種執行模式,少用1個core來參與計算。
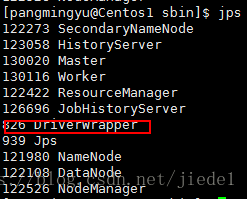

應用程式的結果,會在執行driver程式的節點的stdout中輸出,而不是列印在螢幕上(區別4)
5,基於YARN的Resource Manager的Client模式(叢集)
現在越來越多的場景,都是Spark跑在Hadoop叢集中,所以為了做到資源能夠均衡排程,會使用YARN來做為Spark的Cluster Manager,來為Spark的應用程式分配資源。
在執行Spark應用程式前,要啟動Hadoop的各種服務。由於已經有了資源管理器,所以不需要啟動Spark的Master、Worker守護程序。相關配置的修改,請自行研究。
使用如下命令執行應用程式
spark-submit –master yarn
或者 spark-submit –master yarn –deploy-mode client
提交應用程式後,各節點會啟動相關的JVM程序,如下:
在Resource Manager節點上提交應用程式,會生成SparkSubmit程序,該程序會執行driver程式。
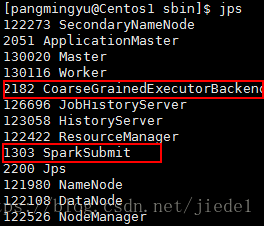
RM會在叢集中的某個NodeManager上,啟動一個ExecutorLauncher程序,來做為
ApplicationMaster。
另外,也會在多個NodeManager上生成CoarseGrainedExecutorBackend程序來併發的執行應用程式
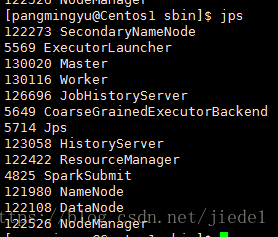
對應的YARN資源管理的單元Container,關係如下:

6,基於YARN的Resource Manager的Custer模式(叢集)
使用如下命令執行應用程式:
spark-submit –master yarn –deploy-mode cluster
和第5種執行模式,區別如下:
在Resource Manager端提交應用程式,會生成SparkSubmit程序,該程序只用來做Client端,應用程式提交給集群后,就會刪除該程序。
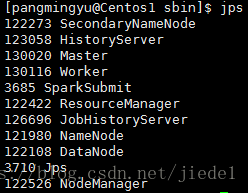
Resource Manager在叢集中的某個NodeManager上執行ApplicationMaster,該AM同時會執行driver程式。緊接著,會在各NodeManager上執行CoarseGrainedExecutorBackend來併發執行應用程式。
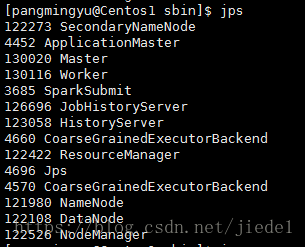
應用程式的結果,會在執行driver程式的節點的stdout中輸出,而不是列印在螢幕上。
對應的YARN資源管理的單元Container,關係如下:
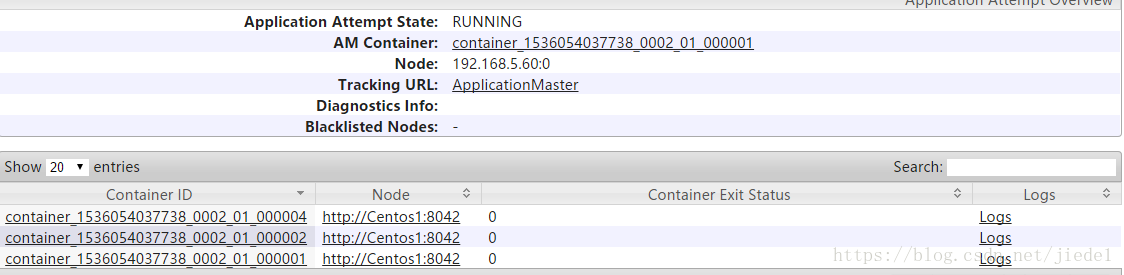
為ApplicationMaster生成了容器 000001
為CoarseGrainedExecutorBackend生成了容器 000004-000002
附spark常見術語:
Application: Appliction都是指使用者編寫的Spark應用程式,其中包括一個Driver功能的程式碼和分佈在叢集中多個節點上執行的Executor程式碼
Driver: Spark中的Driver即執行上述Application的main函式並建立SparkContext,建立SparkContext的目的是為了準備Spark應用程式的執行環境,在Spark中有SparkContext負責與ClusterManager通訊,進行資源申請、任務的分配和監控等,當Executor部分執行完畢後,Driver同時負責將SparkContext關閉,通常用SparkContext代表Driver
Executor: 某個Application執行在worker節點上的一個程序, 該程序負責執行某些Task, 並且負責將資料存到記憶體或磁碟上,每個Application都有各自獨立的一批Executor, 在Spark on Yarn模式下,其程序名稱為CoarseGrainedExecutor Backend。一個CoarseGrainedExecutor Backend有且僅有一個Executor物件, 負責將Task包裝成taskRunner,並從執行緒池中抽取一個空閒執行緒執行Task, 每一個coarseGrainedExecutor Backend能並行執行Task的數量取決與分配給它的cpu個數
Cluster Manager:指的是在叢集上獲取資源的外部服務。目前有三種類型
Standalone: spark原生的資源管理,由Master負責資源的分配
Apache Mesos:與hadoop MR相容性良好的一種資源排程框架
Hadoop Yarn: 主要是指Yarn中的ResourceManager
Worker: 叢集中任何可以執行Application程式碼的節點,在Standalone模式中指的是通過slave檔案配置的Worker節點,在Spark on Yarn模式下就是NoteManager節點
Job: 包含多個Task組成的平行計算,往往由Spark Action觸發生成, 一個Application中往往會產生多個Job
Stage: 每個Job會被拆分成多組Task, 作為一個TaskSet, 其名稱為Stage,Stage的劃分和排程是有DAGScheduler來負責的,Stage有非最終的Stage(Shuffle Map Stage)和最終的Stage(Result Stage)兩種,Stage的邊界就是發生shuffle的地方
DAGScheduler: 根據Job構建基於Stage的DAG(Directed Acyclic Graph有向無環圖),並提交Stage給TASkScheduler。 其劃分Stage的依據是RDD之間的依賴的關係找出開銷最小的排程方法。

TASKSedulter: 將TaskSET提交給worker執行,每個Executor執行什麼Task就是在此處分配的. TaskScheduler維護所有TaskSet,當Executor向Driver發生心跳時,TaskScheduler會根據資源剩餘情況分配相應的Task。另外TaskScheduler還維護著所有Task的執行標籤,重試失敗的Task。下圖展示了TaskScheduler的作用

在不同執行模式中任務排程器具體為:
Spark on Standalone模式為TaskScheduler
YARN-Client模式為YarnClientClusterScheduler
YARN-Cluster模式為YarnClusterScheduler
將這些術語串起來的執行層次圖如下:

Job=多個stage,Stage=多個同種task, Task分為ShuffleMapTask和ResultTask,Dependency分為ShuffleDependency和NarrowDependency