
Spark底層原理簡化版
目錄
Spark SQL/DF的執行過程
將上層的SQL語句對映為底層的RDD模型。

- 寫程式碼(DF/Dataset/SQL)並提交
- Parser解析後得到unresolved logical plan(程式碼合法但未判斷data是否存在、資料型別)
- Analyzer分析對比Catalog(裡面綁定了資料資訊)後得到 analyzed logical plan(有資料型別的計劃)。
- Optimizer根據預定的邏輯優化得到optimized logical plan。這些邏輯為Rule,例如PushdownPredicate(即提前filter,需要storage支援,如mysql)、ConstantFolding(將常量合併,如1+1直接變為2)、ColumnPruning(減少讀取的列,根據select判斷,同樣需要storage支援,如Parquet、ORC)等
- Query Planner從optimized locical plan中得出不同的物理執行策略
Iterator[PhysicalPlan] - CBO利用Cost Model得出最優physical plan(截止2.2還沒實現),它包含一系列RDDs和transformation,即UI顯示的DAG。
- 提交前準備,如確保分割槽操作正確、物理運算元樹節點重用、Code Generation等,得到Prepared SparkPlan
- 得到QueryExecution
- 在叢集執行(執行過程通過生成本地Java位元組碼去除整個tasks或者stages來進一步優化)。Adaptive Execution還會根據資訊動態調整執行計劃。
上述除了第一步和最後一步,其他都在driver中完成。
Catalog主要用於各種函式資源資訊和元資料資訊的統一管理,包括全域性的臨時檢視管理、函式資源載入器、函式註冊介面、外部系統Catalog(資料庫)、配置。
叢集執行部分
- Driver程序執行程式碼,當發現action時,會呼叫sc.runJob() -> dagScheduler.runJob()。
- DAGScheduler通過submitJob將job提交到任務佇列eventProcessLoop中。然後DAGScheduler通過doOnReceive對任務佇列中的資訊進行模式匹配,如果匹配到JobSubmitted,就通過handleJobSubmitted,從job中建立ResultStage,然後呼叫submitStage。這個函式會通過getMissingParentStages,從ResultStage的rdd開始沿著rdd的依賴遍歷,遇到ShuffleDependency,則建立ShuffleMapStage。然後對這些MissingParentStages呼叫submitMissingTasks。裡面會根據Stage的型別建立相應的Task並放進一個taskSet中。然後呼叫taskScheduler.submitTasks(taskSet)
- taskScheduler的這個函式根據taskSet新建TaskSetManager(包含taskset),並將manager放入schedulableQueue。然後呼叫CoarseGrainedSchedulerBackend的reviveOffers,傳送ReviveOffers給自己。
- 當CoarseGrainedSchedulerBackend接收到這個資訊後就會呼叫makeOffers,篩選出activeExecutors,然後呼叫TaskScheduler的resourceOffers獲取TaskDescription,記錄task要被髮送給哪個executor、jar包地址等資訊。接著把TaskDescription作為引數呼叫launchTasks。這個函式會根據將序列化後的task建立LaunchTask,並send到相應的executor。這樣,任務就被髮送到叢集。各個方法後續都有獲取結果的程式碼返回給runJob。在任務執行期間,Driver繼續執行程式碼,遇到action就重複上述步驟。
一個job結束後會進行checkpoint。
- ExecutorBackend呼叫receive,如果匹配到LaunchTask,就會呼叫executor的launchtask,該函式根據任務建立taskrunner,並放入執行緒池中執行。
Aggregation
AggregateFunction抽象類,它有兩個子抽象類:ImperativeAggregate命令式和DeclarativeAggregate宣告式。AggregateExpression是AggregateFunction的封裝。
聚合緩衝區(AggregateBuffer)與聚合模式(AggregateMode)
AggregateBuffer每個key一個,儲存中間結果
聚合模式有4種:
- Final模式和Partial模式一般都是組合使用。Partial模式可以看作是區域性資料的聚合,返回的是聚合緩衝區中的中間資料。而Final模式所起到的作用是將聚合緩衝區的資料進行合併,然後返回最終的結果。
- Complete模式不進行區域性聚合計算
- PartialMerge:對聚合緩衝區進行合併,但還不是最終結果,主要用於distinct語句中。
執行
由執行框架AggregationIterator的子類TungstenAggregationIterator、SortBasedAggregationIterator和ObjectAggregationIterator分別執行HashAggregateExec、SortAggregateExec和ObjectHashAggregateExec。在一些情況下會將HashAggregate變為SortAggregate:
- 查詢中存在不支援Partial方式的聚合函式
- 聚合函式結果不支援Bufer方式,例如collect_set和collect_list函式
- 記憶體不足
Join
Join策略:廣播、ShuffledHashJoinExec、SortMergeJoinExec(最常見)、其他不包含join條件的語句。
廣播:當一個大表和一個小表進行Join操作時,為了避免資料的Shuffle,可以將小表的全部資料分發到每個節點上。
在Outer型別的Join中,基表不能被廣播,例如當A left outer join B時,只能廣播右表B。
ShuffledHashJoinExec:先對兩個表進行hash shuffle,然後把小表變成map完全儲存到記憶體,最後進行join。
開啟條件:spark.sql.join.preferSortMergeJoin為false;小表的大小 小於 廣播閾值 * 預設分割槽數;小表3倍小於另一個表。不適合兩個表都很大的情況,因為其中一個表的hash部分要全部放到記憶體。
SortMergeJoinExec:先hash shuffle將兩表資料資料相同key的分到同一個分割槽,然後sort,最後join。由於排序的特性,每次處理完一條記錄後只需要從上一次結束的位置開始繼續查詢。適合大表join大表。
Shuffle
shuffle是根據partitioner(key或ranger)將不同節點上的資料移動到其對應的(同hash劃分或range範圍)節點上,便於同類資料的聚合或join等計算。這個過程中,map side組織資料,如果shuffle的資料過大,會把資料溢位到磁碟,reduce side拉取資料。ByKey類shuffle的效能消耗更大,它們會在兩端為每類key建立聚合物件(同樣記憶體不夠進磁碟,等GC刪除)。
以上為官網內容,下面為底層實現部分。
從2.0開始,Spark就只有Tungsten Sort Shuffle。在實現層面,Spark在啟動時會建立ShuffleManager來管理Shuffle,預設情況下SortShuffleManger(tungstensort對應)是ShuffleManager的具體實現。ShuffleMapTask從SortShuffleManger中獲得ShuffleWriter。下游的task獲取ShuffleReader。
ShuffleWriter的具體實現:
當ShuffleDependency註冊一個Shuffle時就會得到一個ShuffleHandle物件,根據它獲取相應的writer。
- BypassMergeSortShuffleHandle(可以獲得BypassMergeSortShuffleWriter),即可以忽略掉聚合排序的Shuffle過程(從Shuffle資料讀取任務看來,資料檔案和索引檔案的格式和內部是否做過聚合排序是完全相同的。),直接將每個分割槽寫入單獨的檔案,並在最後做一個合併處理,並建立一個index索引檔案來標記不同分割槽的位置資訊。適合資料量少的情況。
- SerializedShuffleHandle(可以獲得UnsafeShuffleWriter),對應Tungsten方式的Shuffle過程,這種情況下ShuffleMapTask的輸出資料能夠先序列化為二進位制資料儲存在記憶體中,再執行相關的操作,在記憶體使用上是一種更高效的方式。
- BaseShuffleHandle(可以獲得SortShuffleWriter),在不滿足上面兩種handle條件時獲得BaseShuffleHandle物件,意味著以反序列化的格式處理Shuffle輸出資料。過程是建立ExternalSorter物件,將全部資料插入該物件,生成Shuffle資料檔案和索引檔案,最後建立MapStatus物件,將資料和索引進行傳輸。關鍵實現在於外部排序器,根據是否需要聚合採用不同的map資料結構,當資料量過大,便會溢位到磁碟。
ShuffleReader的具體實現
BlockStoreShuffleReader方面,根據上述map資訊對ShuffleBlockFetcherIterator進行不同的封裝,得到相應的iterator。
writer和reader都會根據是否有aggregator、ordering進行相應的處理。writer還有partitioner引數。這些對於shuffle都是optional。
Tungsten
記憶體管理機制
Executor中物件的處理實際由JVM執行,Spark的統計資料無法準確計算資料量的大小,所以無法避免OOM。
Tungsten的記憶體管理(需要設定ofHeap.enabled和ofHeap.size)讓Spark直接操作二進位制資料而不是JVM物件,從而提升記憶體使用率。
記憶體管理器
記憶體管理由MemoryManager通過MemoryPool管理。MP根據heap和ofheap分為兩大類。每類再分為execration和storage。
MemoryManager的具體實現有1.6之前的StaticMemoryManager和之後的UnifiedMemoryManager。任務通過這些manager來完成記憶體申請或釋放操作。下圖為統一記憶體管理器的所管理的記憶體結構。其中Reserved用於Spark系統內部,應用記憶體為使用者程式中的資料結構。
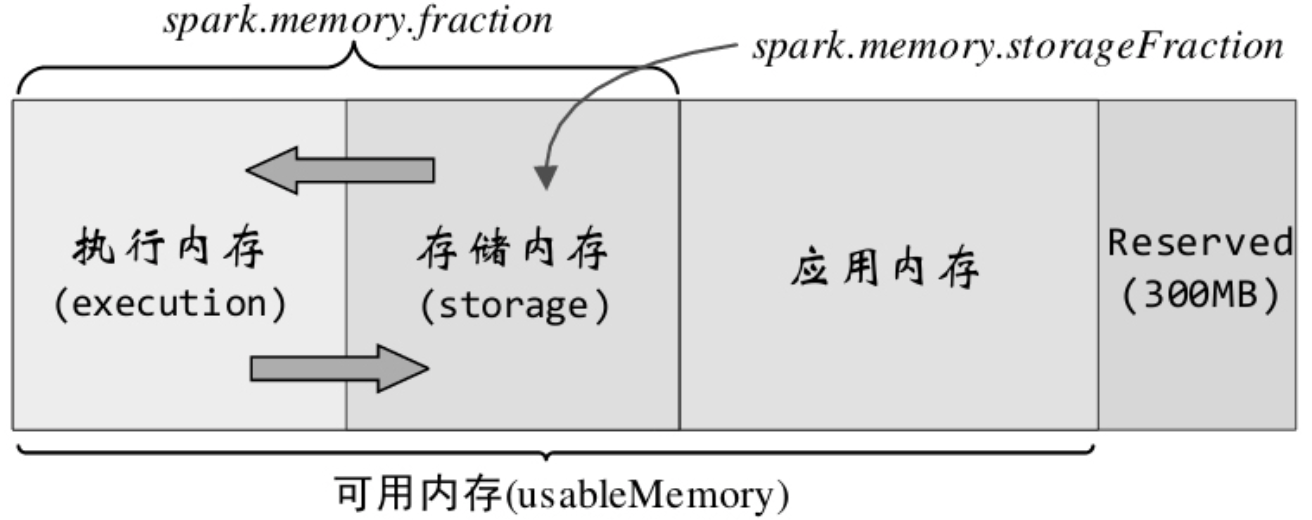
執行記憶體和儲存記憶體之間能互相借用(當空間不足,即放不下一個完整的block,且對方有空餘時。),歸還時可讓對方多佔用的部分轉到磁碟,但有些複雜的因素會導致無法歸還。
儲存記憶體
如上面所說,儲存記憶體管理器為StorageMemoryPool,它的使用者是儲存模組,具體實現是BlockManager。它負責管理計算過程中產生的各種資料,可以看作是一個獨立的分散式儲存管理系統。Driver端的為主BlockManagerMaster,負責對全部資料塊的元資料資訊進行管理和維護,Executor端將資料塊的狀態上報到driver端,並接收住節點的相關操作命令。
在rdd被快取到儲存記憶體之前,它是屬於應用記憶體部分的,而且是不連續的,上層通過迭代器訪問。持久化後才到儲存記憶體,且連續。而根據持久化的級別,是否序列化,會採用不同的資料結構。如果有新的block需要快取而沒有足夠的儲存記憶體,BlockManager會分局LRU淘汰Block,這個淘汰要麼刪除,要麼溢位到磁碟,看被淘汰的block是否設定了usedisk的持久化。
執行記憶體
主要用於滿足shuffle、join、sort、agg等計算過程對記憶體的需求。
記憶體管理最底層實現
記憶體分配管理的基礎是MemoryAllocator,manager通過它來申請和釋放記憶體。其實現包括HeapMemoryAllocator和UnsafeMemoryAllocator。
Tungsten使用另外的一些資料結構和方法來實現其計算。例如重新實現的ByteArray、LongArray、UTF8String、BytesToMap等。
快取敏感計算(Cacheaware computation)
通過設計快取友好的資料結構來提高快取命中率和本地化的特性。
動態程式碼生成(Code generation)
程式碼生成能夠去掉原始資料型別的封裝和多型函式排程。
參考
Spark 2.2.2 原始碼
Spark SQL 核心剖析