BigData_A_A_01-hdfs分散式檔案系統(2)高可用
阿新 • • 發佈:2018-12-22
楔子
Hadoop 3 高可用搭建記錄
1 zookeeper叢集
zoo.cfg 檔案配置資料檔案位置等資訊
#其他使用預設
dataDir=/opt/data/zk
server.1=had2:2888:3888
server.2=had3:2888:3888
server.3=had4:2888:3888
分發到其他機器
scp -r zookeeper-3.4.6/ had4:`pwd`
# 使用`pwd` 會把 檔案傳送到其他機器的相同位置
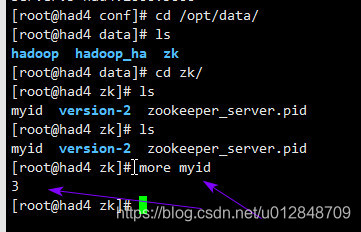
dataDir目錄 放置id
zkServer.sh start 啟動(我配置了環境變數)
2 Hadoop配置檔案
需要的都可以參考 官方文件
2.1 hadoop-env.sh
export JAVA_HOME=/usr/local/soft/jdk
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
#export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=root
2.2 hdfs-site.xml
<configuration> 2.3 core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop_ha</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>had2:2181,had3:2181,had4:2181</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
</configuration>
3 啟動叢集
# 1 啟動JournalNode守護程式(在各個機器依次啟動)
hdfs --daemon start journalnode
# 2 應首先在其中一個NameNode上執行format命令(hdfs namenode -format)
hdfs namenode -format
# 2_2 格式化後繼續在本機器啟動namenode
hdfs --daemon start namenode
# 3 應該通過執行命令將NameNode元資料目錄的內容複製到其他未格式化的NameNode上
hdfs namenode -bootstrapStandby
3.2 在ZooKeeper中初始化HA狀態
在ZooKeeper中初始化所需的狀態。可以通過從其中
一個NameNode主機執行以下命令來執行此操作。
hdfs zkfc -formatZK

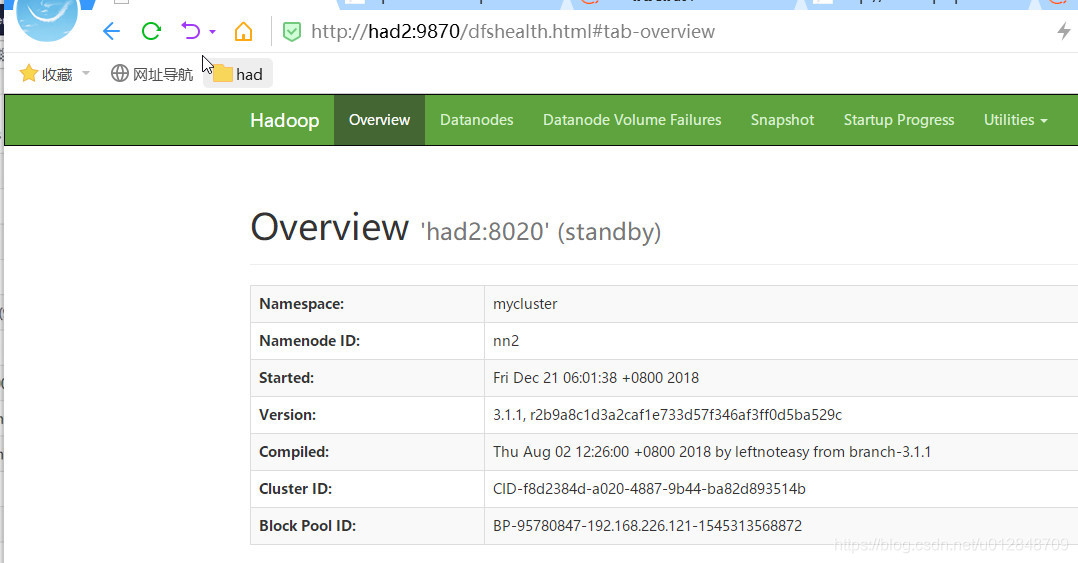
3.3 啟動叢集
使用start-dfs.sh啟動叢集
由於配置中已啟用自動故障轉移,因此start-dfs.sh指令碼現在將在執行NameNode的任何計算機上自動啟動ZKFC守護程式。當ZKFC啟動時,它們將自動選擇其中一個NameNode變為活動狀態。
start-dfs.sh