
CI/CD的利器k8s+docker
首先docker它具有以下的優勢
- 標準化:所有環境一個映象,解決環境差異性。避免因為開發環境和測試環境不一致帶來的問題。
- 快速化:啟動時間短,秒級。
- 隔離性:namesapce,cgroups,聯合檔案系統提供除核心外完整的隔離性,解決互相影響的問題。
- 易擴充套件:使用映象迅速搭建N套環境,無間隙。 版本管理--映象的版本管理對應測試環境的版本管理,易操作。
- 易用性:Dockerfile編寫簡單,會寫shell的人就會製作映象
而k8s也有很多的優勢:
- 天然的解決方案:玩過k8s的都知道,使用k8s你幾乎可以不用太擔心負載均衡,彈性伸縮,服務發現,路由轉發等等令人頭疼的問題。 它的service和deployment自動幫你做負載均衡,HPA自動的彈性伸縮,kubedns為你提供域名解析,實現服務發現。 官方的ingress直接為你實現好了7層路由。
- 自動化運維:k8s的自動化運維能力也是讓人津津樂道的。它的健康檢查能全方位的檢測容器狀態和程序狀態。出現問題的時候自動銷燬,自動修復。 容器出錯重啟容器,節點宕機漂移到其他可用節點重新部署。期間負載均衡模組自動導流。
- 強大的排程能力:在k8s中實現多租戶是很方便的。 quota可以隔離資源,namespace可以隔離應用。 node selector和節點親和性更是可以細粒度的控制應用部署在何處。 強大的排程能力使我們的維護成本降到最低。
- 簡單易用的橫向擴充套件能力:一個命令既可擴容,建立應用的時候排程系統動態分配資源。
- 強大的社群:google支援,強大的社群陣容,不用擔心沒有解決方案
那麼K8S在實際的場景中能為我們帶來什麼呢? 我舉幾個場景吧。
橫向擴充套件提升效能與容量
剛才我們說過面對大規模的持續整合與測試環境時。 面對的每日數以千計甚至數以萬計的構建次數。上面還要執行著很多的測試環境。 所以一臺機器搞這事鐵定是沒戲的。如果是以前,我們基本都是在jenkins上加入大量的slave節點並用shell指令碼來維護。 但是當節點越來越多的時候,維護這些節點和環境的成本就越來越高了。 所以如果我們能讓k8s來搞定這些事情,擴容與排程都交給k8s來做。 jenkins只負責pipline,這就解決了我們自己開發和維護這些節點程式的成本。k8s的擴容是很簡單的。並且它給你一個統一的介面,讓你對所有節點和容器的操作只有一個入口。 不會像以前shell指令碼那樣滿天飛的節點配置和邏輯判斷。 而且k8s能夠對自我管理這些節點,自動決定把容器排程到哪個合適的節點上,不必我們操心。
精準的按需排程
在一個複雜的場景中,我們不僅需要叢集的排程系統能按照當前節點的資源使用情況進行排程,也就是儘量把任務分配到較為空閒的節點上進行負載均衡。 我們還需要更精準的按需排程。 K8S中有一種策略叫node selector, 我們通過給叢集打上不同的label給節點分類,在提交任務的時候可以選擇不同類別的節點進行執行。 比如我的資料庫是需要存放資料的,而這些資料只存在那一個特定的節點上, 這樣我們能通過這樣的機制把資料庫容器排程到固定的節點上。 當然我們還可以有更強大的排程。比如GPU資源再哪裡都是稀缺的,我們並不希望大量的普通任務排程到擁有GPU的節點上,免得它們把資源佔滿後會導致真正有GPU需求的任務無法排程上來。 k8s有一種策略叫汙點,任務除非在特別指定的情況下,否則是無法排程到這個加了這個汙點的GPU節點上的。 但這樣也有問題,因為這個策略太排他了,實際上如果我的GPU任務沒有那麼多,站不滿資源。 那這些剩下的資源還不能被其他任務排程,這個資源利用率是無法忍受的。 所以k8s也有第三種排程,叫親和性和反親和性。 這個有點複雜,但是它能達到一種效果。 就是它可以優先把普通任務排程到其他節點上,其他的節點不夠用的時候,才把這些任務排程到GPU節點上。 這樣能最大程度的保證其他任務不會影響GPU任務還能最大化增加資源率用率。
資源治理
上一點說按需排程的時候,也講過資源利用率的問題。 我們面臨大規模的測試環境的時候, 資源治理是一個非常重要的問題。 公司不是土豪, 我們的資源永遠是有限的, 在有限的資源中支撐更多的環境是我們的目標。 我們總在計算著一個節點上能抗多少任務,什麼型別的任務。服務起少了,資源利用率低,服務起多了,可能直接把節點撐爆了。 這是一個挺兩難的事。所以k8s中有quota的概念,是一個非常重要的特性。首先啟動k8s的時候可以設定為系統預留多少資源,這些資源是k8s不會使用的,專門留給linux系統,以免過多的使用撐爆叢集。而且k8s把每一個資源都分為兩種申請方式。 request和limit, request代表著預留資源,也就是說如果我們為一個設定為request memory為2G。 那麼k8s就會為它預留2個G的資源,即便這個任務只用了1個G,但其他任務也無法使用另外一個G的資源。 這種策略保證了服務絕對擁有啟動服務的最小資源,因為只要申請了,系統就會為你預留這些資源使用。 但是這樣的策略有個缺點,就是我們一般無法準確預估出一個服務會用到多少資源,也許他只用了申請資源的一半。 所以我們還有一箇中申請資源叫limit, 他跟requeset配合著使用,request是系統預留的資源,是給任務獨佔的資源,即便任務根本是用不了這麼多的資源,但他也會預留出這些資源給他使用,給一個任務設定過多的這種預留資源肯定是不利於資源利用率的, 但是預留資源少了,也可能造成其他任務搶佔資源導致本任務無法執行。 所以request一般都是設定成需要執行任務的最小資源。 但是最小資源不代表著他永遠都使用這麼小的資源,在服務的高峰期的時候他會使用更多的資源。 所以我們有limit這種資源申請的方式, 如果說request設定的是資源的下限,是任務申請的最小資源, 而limit就是任務申請資源的上限,代表著不論如何,任務使用的資源都不可以超過此上限,超過了就會被k8s kill掉。確保一個任務不會超出它的預期佔用過多的資源。 這樣, request和limit相互配合,就會產生更彈性的資源治理方式。 尤其由於他們這兩種申請資源的方式存在,我們的系統才會擁有超賣的能力。 超賣是一個在叢集管理中常見的詞彙。 意思是一個服務本來申請了固定的資源保持平時的開銷 (request方式),但是在服務高峰期的時候,准許分配給他更多的資源,也就是超賣給他更多的資源來抗住高峰期的壓力(limit方式)。這樣就給了我們更加彈性的資源利用方式。
健康檢查
之前說過k8s有自動化運維的能力, 其中一個重要的能力就是健康檢查和故障恢復。 一般來說,在我們面對數量龐大的部署例項的時候, 最頭疼的就是如果環境不穩定,比如節點故障,或者程序本身故障的時候,我們該如何維護這些部署例項。 在部署例項還比較少的時候這些都不是問題,我們人肉維護都是可以接受的。 但是當我們有微服務的時候,有多套測試環境的時候,數以百計的部署例項會讓所有維護人員都瘋掉。 尤其是有些服務的故障可能是很臨時性的,比如僅僅是程序oom了,或者部署的當前節點發生了什麼故障。 並不是程序本身的問題。可能只需要重啟或者換個節點重新部署就能解決的問題。那這時候k8s的排程能力就起到了很大的作用。 首先k8s能夠自動監控每個節點的健康狀況, 如果A節點發生了故障,k8s會監控到A節點是不健康的狀態, 那麼原來啟動在A節點上的服務,都會自動的漂移到其他的可用節點上重新啟動,來保證我們環境的可用性。 這是節點上的健康檢查 。 同時我們也有用服務的健康檢查, 在k8s中,沒啟動一個服務都可以為它配置相應的健康檢查策略,包括資源的和程序的本身。當任務服務出現異常退出的時候,k8s都會自動的檢測到並在合適的節點上重啟該服務,這其中不會有任何的人工操作。這種故障恢復能力,是在我們面對大規模測試環境中要擁有的重要能力。
k8s還有很多有助於維護我們測試環境的特性,比如驅逐策略,負載均衡,彈性伸縮,init container等等。這裡就不多做介紹了。
下面介紹一下k8s最簡單的玩法。

-
在k8s中,我們使用1個或多個master節點來控制叢集,之後啟動多個node節點接入叢集。 叢集中所有的節點都共享公共的映象倉庫。這樣我們把所有需要部署的服務都製作成映象,就可以為團隊提供穩定的測試環境和測試服務的基礎PAAS平臺。 重要的是我們從此擁有了相應的自動化運維和橫向擴充套件的能力。 通過統一的入口可以維護多套測試環境,資源不夠了就加節點。 說白了,我們就是在拿錢砸效率。我們在推行微服務之前,在高峰時期曾支撐過70套左右的測試環境。 其中包括了各種版本以及對接各個團隊的需求。 當然了為了能夠維護這種量級的測試環境。 我們需要一些機制上的支撐。
-
跨主機通訊:weave或flannel, 玩過docker的人都知道網路是第一個要克服的難題。 每個docker程序都會自己維護一個私有網路,那麼在叢集中不同節點上的docker 容器如何互相通訊是一個問題。 所幸目前已經有一些外掛支援k8s元件一個overlay網路。 比如我們曾經使用的weave和現在正在使用的flannel。 它會在叢集的每一個節點上都安裝一個路由容器,幫助我們轉發網路請求。 通過這樣構建一個overlay網路的形式達到跨節點通訊的目的。 而且這些組建都已經有成熟的容器化部署方案,我們直接拿來用就可以
-
服務發現:kube-dns,docker 容器的另一個特點是容器的ip也是隨機分配。我們在啟動前無法獲取ip,並且在容器重啟後ip也會發生變化。 所以個成熟的服務發現的機制就比較重要了。 k8s官方提供的kubedns是滿足我們的需求的。 在k8s中有service的概念,我們只要建立一個service,k8s叢集就會在kubedns上建立一個域名指定到這個service 上。 而每個service,最後都會轉發到我們的容器裡面。
-
7層路由:ingress, 我們可以通過dns和flannel這種網路組建解決服務發現和跨主機通訊的問題。 但是從叢集外部訪問叢集內部還沒有解決。 因為即便是k8s的overlay網路也只是一個私有的虛擬網路。 如果我們想要從外部訪問叢集的服務,還需要做一些處理。 最簡單的方式是nodeport,這是一種埠對映規則, 利用iptables建立轉發規則,把叢集節點的埠和容器埠繫結, 這樣使用者使用ip+埠的方式就可以訪問叢集服務了。 但是這種方式有一個缺點是需要維護大量的埠對映列表。使用者使用起來也很麻煩,起碼要記住每一個服務埠號是什麼。 所以在這個前提下我們引入了7層路由的概念。 其實這個7層路由就是一個nignx, 只不過不同的是它是使用k8s中的hostnetwork模式啟動的,它的特點是直接使用宿主機的網路,而不是使用叢集的overlay網路,所以這個nignx容器是可以和叢集外部網路通訊的。 同時由於我們安裝的weave或者flannel會在每一個叢集節點上安裝一個路由容器,它會幫助這個nginx容器做轉發,所以它也能夠訪問叢集網路。 所以這個使用hostnetwork的容器就變成了一個可以同時和叢集網路以及外部網路通訊的容器。 它也就變成了一個7層的路由。 這時候我們在公司內部的DNS上配置一個泛域名解析, 凡是以固定域名結尾的請求都解析到這個容器的ip上。通過nignx識別不同的service轉發到不同的容器中。就實現了這個7層路由的功能。 比如,我們在nignx中建立的規則是解析一個域名的service部分,然後講請求轉發到對應的k8s的service上。 一個名字叫test01.n1.com的域名和test02.n1.com的service部分是test01和test02。 nignx會解析出來然後轉發到不同的k8s service上。 這塊我就不具體詳細說明怎麼實現的了,大家在網上搜一下ingress就可以了。 這是官方的7曾路由的解決方案,除了這個nginx外還要建立單獨的ingress規則。 而我們使用的是自研的,省略了這些步驟。
監控:官方的解決方案是Heapster+grafana+InfluxDB。 可以在github上找到現成的映象使用。我們一開始也是使用這種方式。後來我們慢慢演進到了使用filebeat來收集容器日誌,灌入es中做更精細的日誌監控的機制。最近我們已經遷移到另外的一套架構了,不過監控這塊不是我負責的,我就不說了。
上面這些都是偏運維的東西,我就不再細講下去了,
總之我們通過docker+k8s就有用了很強大的測試服務能力。 一般我們使用這種機制做一下3種事情。
- 搭建測試環境(其中包括了CI,CD的構成搭建)
- 搭建測試服務,比如jira,jenkins,testlink等
- 搭建測試執行環境,比如UI自動化,介面自動化,線上線下一致性對比測試的執行環境。
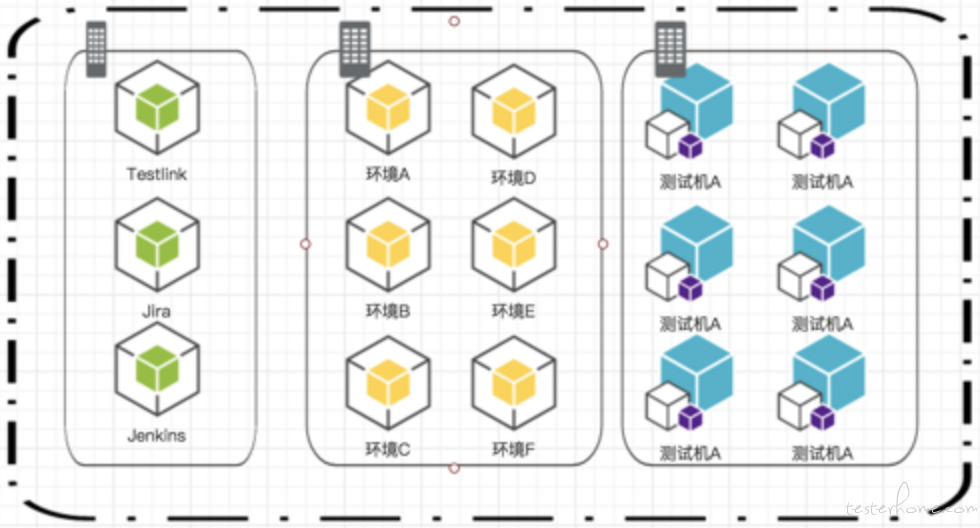
這些是我們對於測試的基礎PAAS平臺的架構設計, 對於像機器學習這種複雜度如此之高的系統來說, 我們對這方面有著很高的要求。尤其是在後期我們的產品引入微服務的架構以後,它的複雜度到達了一種空前恐怖的程度。 所以這就需要我們的測試人員能夠支撐住這樣的基礎設施。
CICD
一個高度工程化的團隊離不開CICD,但是面對機器學習平臺和微服務架構,我們的CICD又有了不一樣的難度。 之前說過我們在微服務架構下每日大量的構建次數對CICD的效能和自動化流程的要求是很高的。這裡我們使用的是k8s+bamboo+jenkins的架構。 當然了,所有的構建都是基於k8s來做的,使用k8s的分散式排程來做橫向擴充套件,解決環境對效能的要求。 利用bamboo和jenkins的pipeline銜接整個CICD自動化流程。整個的流程如圖:

- 研發人員任何的提交程式碼行為都會觸發bamboo上的plan,plan會拉取程式碼執行單元測試和整合測試,執行成功後會打出一個包作為產物上傳到倉庫中。如果執行失敗,將中斷流程,該模組自動報警。
- 上傳成功後觸發bamboo的deployment任務去製作映象並push到映象倉庫中。 這裡有一點,如果這裡有CD的需求,如果這個分支是聯調分支,或者是穩定環境。就會觸發CD任務,利用最新的映象升級環境。
- 同時jenkins上的pipeline每日或觸發或定時, 在k8s叢集上拉取最新的映象,部署環境,執行UI自動化測試,API自動化測試。並彙總測試報告。
通過這樣的cicd流程加上k8s強大的排程能力,我們支撐著每日千量級別的構建次數的同時,保證了最快的響應速度。 託了k8s的自動化運維能力,我們也能夠用最少的人去維護這樣一個龐大的系統。
機器學習平臺下的自動化測試
我們說機器學習平臺已經是一個產品了。 所以一個產品該有的東西都會有,我們測試人員關心的UI和API都會有。 該有的模組也都會有, 比如使用者,許可權,quota,專案,計劃,監控,資料管理等等等。 所以除了機器學習特有的一些特性外,他跟我們普通的測試策略也比較像。 構建測試體系的時候,也符合金字塔原理。 但在這裡我們的CICD流程中就有了
另一個挑戰,那就是測試執行的速度。做機器學習的研發也好,測試也好。 都要面對一個無法避免的問題。 那就是任務執行很慢。 在大資料的情況下,一個模型要用幾個小時甚至幾天的情況也是不奇怪的。即便我們用一個很小的資料走通業務流程,一般也需要數分鐘甚至數十分鐘。 所以如果我們像以前一樣,使用一個瀏覽器執行的話,在海量的case面前,我們的自動化測試會跑到天荒地老的。 所以在我們早期的時候就會使用多瀏覽器的方式來為我們的自動化測試加速。 我們使用的技術棧是java+testng+selenide。 testng的併發測試模式大家可以瞭解一下,調整併發的執行緒數我們就可以在一臺機器上啟動多個瀏覽器進行測試。

通過類似上面這樣的配置,我們把測試分成了兩個組並且併發的去測試他們。 這樣在初期的時候還是可以接受的。 但是隨著case慢慢的增長, 演算法越來越多。 我們又出現了一個問題, 那就是單臺機器已經無法支撐更多的瀏覽器了。我們說架構擴容有縱向擴充套件和橫向擴充套件兩種,縱向擴充套件是通過提高節點的硬體配置來提高效能,但是即便是再優秀的機器它的縱向擴充套件也是有極限的。 而橫向擴充套件是通過增加節點的方式分擔壓力。那麼目前我們面對的就是在縱向擴充套件遇到極限的時候,引入橫向擴充套件的能力。 而testng本身是不支援跨越多臺機器進行分散式執行的。 所以後來我們引入了selenium gird。 這是一種基於selenium的分散式UI自動化測試解決方案。 它通過啟動一個grid hub作為master節點,負責接收測試請求以及分發任務。 再通過啟動多個node 節點向hub 進行註冊。 這樣grid hub會接收到我們的測試請求,並適當的把測試任務均勻的傳送到各個node上去。 在測試結束後彙總結果返回給testng。 它的架構是下面這個樣子的。

通過這樣的架構,我們的自動化測試就擁有了橫向擴充套件的能力。 支援更多的瀏覽器幫助我們進行併發測試。當然大家可以看到在這個圖裡我們各個節點上都帶有docker的標記, 為了方便管理和節省資源。 我們也使用容器管理的方式來建設自動化設施。 我們講grid hub製作成映象,可以執行在k8s中當做一個服務。 然後將不同的瀏覽器製作成不同的映象。 比如把chrome和Firefox做成不同的node映象,也通過k8s啟動服務,註冊到grid hub中。 當然大家可以發現我們在上面的這個圖裡在IE的映象那裡畫一個叉,因為目前docker還是無法制作ie的映象的,這涉及到docker的原理,docker使用的是宿主機的核心也就是linux系統的核心。 還是無法驅動windows的GUI的。 所以這部分沒有辦法,只能夠通過在外面啟動虛擬機器的方式接入ie瀏覽器了。 不過其他兩種瀏覽器還是可以很簡單的使用的。 並且通過k8s的自動分片的功能,我們可以很方便的啟動多個node來支援自動化測試。 k8s強大的排程能力也會在資源上做權衡,做到資源利用最大化,而不會把這些node都啟動到一個節點上。 同時健康檢查機器可以監控到每個node和hub的狀態,如果出現異常會自動的找到可用的節點重新部署。 資源管理能力也可以限制和申請適當的資源,很方便實現的超賣功能。 這樣通過k8s的自動化運維的能力,我們可以很好的管理我們的瀏覽器叢集。 當然也許會有同學問都是使用docker啟動的瀏覽器,那麼我們怎麼樣能夠實時的看到瀏覽器在發生什麼呢?以前使用windows的時候我們是可以通過介面看到發生的所有事情,方便除錯。 其實我們在這裡也是可以做到的。 我們在一個node映象中都安裝vnc服務,並向外暴露埠。 我們在自己的本機上使用vnc viewer就可以看到瀏覽器上發生的一切。
這時候我們的整體工作流程就是下面這個樣子的了。

這裡我們有兩種做法, 一種是jenkins直接呼叫k8s的job,job執行自動化測試,執行完畢後jenkins拉取report。 另一種做法是直接利用的jenkins的slave機制,把slave直接用k8s中的容器的形式啟動起來。 這樣j8s中的一個容器就是jenkins的slave了。 如果為了簡單,我們可以選擇後者,利用k8s的自動化運維能力,提供穩定的服務。 在jenkins上的job上繫結測試的repo,jenkings觸發測試的時候,jenkins的salve會到git上拉取程式碼,並執行自動化測試, 由於我們的slave就是啟動在k8s裡的容器,所以他們的訪問是無障礙的,甚至完全不需要埠對映和7層路由。 slave的測試請求會發送到同樣是啟動在k8s中的grid hub上,gird hub會把任務傳送到同樣在k8s中作為容器啟動的node上面去執行。 之後將測試結果一層層的返回,彙總到jenkins的job中。 這裡使用k8s的優勢就是完全的自動化運維管理,出現任何異常k8s都會幫我們處理,這比搭建多個虛擬機器來管理要方便便捷很多。 通過這樣的架構,在我們的公司的日常測試中使用40個瀏覽器併發測試的方式,可以在30分鐘內結束戰鬥。 極大的提升了測試效率。這裡在安利一波selenide,這是一個github上面的開源專案, 基於selenium做了一層封裝。 可以很好的支援我們的這種架構。我們只需要兩行程式碼,就可以對接這種分散式架構了。 如下:

上面的第一個配置指定使用的瀏覽器型別,第二個配置指定grid hub的地址。 這樣就可以讓我們的程式碼測試程式碼遷移到這個分散式架構上了。 其他的任何程式碼都不需要改變。 之後的工作只需要在testng的配置檔案中指定併發數量就可以了。