
Spark On Hive配置
Spark On Hive 配置步驟
- 在Spark客戶端安裝包下的conf目錄中建立檔案hive-site.xml,配置hive的metastore路徑
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node01:9083</value>
</property>
</configuration>
- 啟動Hive的metastore服務
hive --service metastore
- 啟動zookeeper叢集,啟動Hadoop叢集
- 啟動SparkShell 讀取Hive中的表總數,對比hive中查詢同一表查詢總數測試時間
注意
如果使用Spark on Hive 查詢資料時,出現錯誤:

找不到Hadoop叢集路徑,要在客戶端機器conf/spark-env.sh中設定Hadoop的路徑:
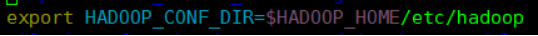
總結
上面寫了一大堆,其實總體就兩步:
- 配置hive的metastore路徑
- 設定Hadoop路徑
相關推薦
Spark On Hive配置
檢視Spark叢集的搭建 Spark On Hive 配置步驟 在Spark客戶端安裝包下的conf目錄中建立檔案hive-site.xml,配置hive的metastore路徑 <configuration> <property>
spark學習記錄(十一、Spark on Hive配置)
新增依賴 <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.12</artifa
SparkSQL建立RDD:建立DataFrame的方式,配置Spark on Hive【文字說明+關鍵程式碼】
建立DataFrame的方式 建立DataFrame的方式 1).讀取json格式的檔案 a).json檔案不能巢狀 b).讀取的兩種方式: DataFrame df = sqlContext.read().format("json").load(
Spark on hive編譯以及簡單使用
com nbsp http imp 列表 需要 -a rift usr 分別下載了spark 和hive 配置好 發現在元數據庫裏面 這2個是不通的 是需要編譯spark的源碼以支持hive的 在這裏我用的是一臺centos7的虛擬機 準備工作: jdk的安裝配置 hado
SparkSQL & Spark on Hive & Hive on Spark
單獨 bmi 查詢 數據信息 mar src detail ado 序列 剛開始接觸Spark被Hive在Spark中的作用搞得雲裏霧裏,這裏簡要介紹下,備忘。 參考:https://blog.csdn.net/zuochang_liu/article/details/
spark on hive原理與環境搭建 spark研習第三季
SparkSQL前身是Shark,Shark強烈依賴於Hive。Spark原來沒有做SQL多維度資料查詢工具,後來開發了Shark,Shark依賴於Hive的解釋引擎,部分在Spark中執行,還有一部分在Hadoop中執行。所以講SparkSQL必須講Hive。 一、
hive on tez配置
adc 6.0 不能 access argument misc t權限 tez nag 1、Tez簡介 Tez是Hontonworks開源的支持DAG作業的計算框架,它可以將多個有依賴的作業轉換為一個作業從而大幅提升MapReduce作業的性能。Tez並不直接面向最終用戶—
Spark on Yarn with Hive實戰案例與常見問題解決
ast spa dfs img 運維 base kcon 運維人員 來看 [TOC] 1 場景 在實際過程中,遇到這樣的場景: 日誌數據打到HDFS中,運維人員將HDFS的數據做ETL之後加載到hive中,之後需要使用Spark來對日誌做分析處理,Spark的部署方式是
大資料之Spark(八)--- Spark閉包處理,Spark的應用的部署模式,Spark叢集的模式,啟動Spark On Yarn模式,Spark的高可用配置
一、Spark閉包處理 ------------------------------------------------------------ RDD,resilient distributed dataset,彈性(容錯)分散式資料集。 分割槽列表,fun
Spark on Yarn:任務提交引數配置
當在YARN上執行Spark作業,每個Spark executor作為一個YARN容器執行。Spark可以使得多個Tasks在同一個容器裡面執行。 以下引數配置為例子 spark-submit --master yarn-cluster / yarn-client
首頁 Hadoop Spark Hive Kafka Flume 大資料平臺 Kylin 專題文章 Spark運算元 一起學Hive Hive儲存過程 Hive分析函式 Spark On Yarn 資料
關鍵字: orc、index、row group index、bloom filter index之前的文章《更高的壓縮比,更好的效能–使用ORC檔案格式優化Hive》中介紹了Hive的ORC檔案格式,它不但有著很高的壓縮比,節省儲存和計算資源之外,還通過一個內建的輕量級索引
SparkSQL On Hive和spark的記憶體分配問題
Spark On Hive 1.SparkSQL整合Hive,需將hive-site.xml複製到{SAPRK_HOME/conf}目錄下,即可!! a.將hive-site.xml複製到{SAPRK_HOME/conf}目錄下; b.將hi
CDH安裝配置zeppelin-0.7.3以及配置spark查詢hive表
1.下載zeppelin http://zeppelin.apache.org/download.html 我下載的是796MB的那個已經編譯好的,如果需要自己按照環境編譯也可以,但是要很長時間編譯,這個版本包含了很多外掛,我雖然是CDH環境但是這個也可以使用。 2.修改
Hadoop 分散式配置及Spark on yarn部署
配置Hadoop Hadoop的叢集部署模式需要修改Hadoop資料夾中/etc/hadoop/中的配置檔案,更多設定項可見官方說明,這裡只設置了常見的設定項:hadoop-env.sh,yarn-env.sh、core-site.xml、hdfs-site.xml、mapred-site.
Spark On Yarn 詳細配置流程
1、系統與軟體準備 系統:centos7軟體: hadoop-2.7.2.tar.gz,請勿選擇src版本,否則需要自行編譯 jdk-7u79-linux-x64.tar.gz scala-2.10.3.tgz spark-1.6.1-bin-hadoop2.6.t
Mark :Hive使用Spark on Yarn作為執行引擎
原文:http://lxw1234.com/archives/2016/05/673.htmHive從1.1之後,支援使用Spark作為執行引擎,配置使用Spark On Yarn作為Hive的執行引擎,首先需要注意以下兩個問題:Hive的版本和Spark的版本要匹配;具體來
Hive on Spark and Spark sql on Hive
<!--Thrift JDBC/ODBC server--> <property> <name>hive.server2.thrift.min.worker.threads</name> <value>5</valu
自己的HADOOP平臺(三):Mysql+hive遠端模式+Spark on Yarn
Spark和hive配置較為簡單,為了方便Spark對資料的使用與測試,因此在搭建Spark on Yarn模式的同時,也把Mysql + Hive一起搭建完成,並且配置Hive對Spark的支援,讓Spark也能像Hive一樣操作資料。 前期準備
Hive配置文件hive-site.xml
use pan 如果 meta ted span tex config exist <configuration> <property> <name>hive.metastore.warehouse.dir
Spark on Yarn遇到的幾個問題
添加 shuffle tasks pil 生產 當前 lis file 被拒 1 概述 Spark的on Yarn模式。其資源分配是交給Yarn的ResourceManager來進行管理的。可是眼下的Spark版本號,Application日誌的查看,僅僅