
Redis高可用簡介
常見Redis部署方式有以下幾種:
- 單節點
- 主從
- Sentinel
- Cluster
- 代理(Twemproxy等)
下面只分析Sentinel、Cluster、代理的高可用
一、Sentinel
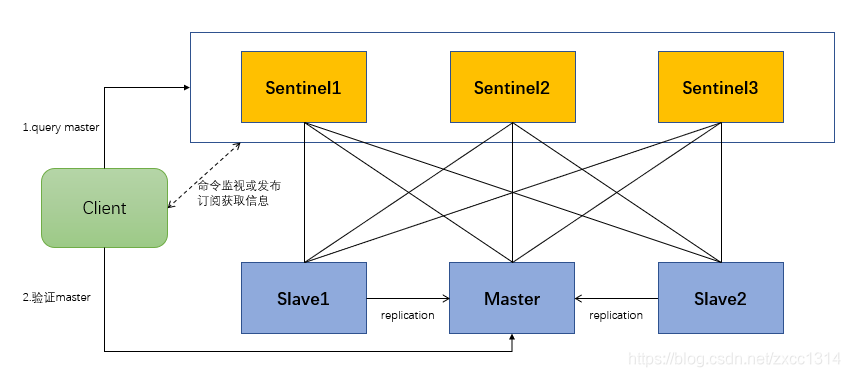
定時任務
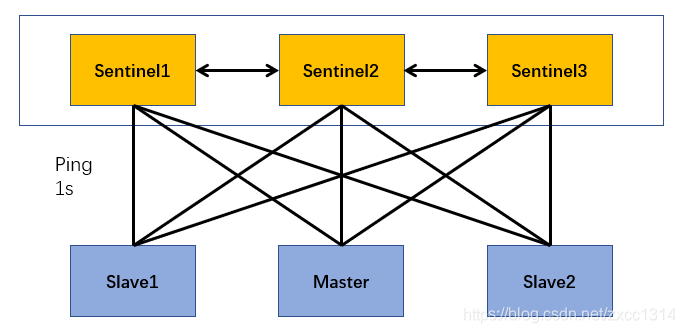
- 每個 Sentinel 以每秒鐘一次的頻率向它所知的主伺服器、從伺服器以及其他 Sentinel 例項傳送一個 PING 命令。 判斷是否客觀下線。
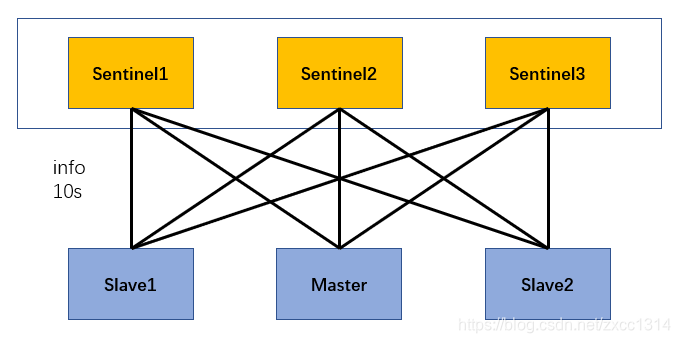
- 每個Sentinel 會以每 10 秒一次的頻率向它已知的所有主伺服器和從伺服器傳送 INFO 命令。用來發現slave節點、確認主從關係。
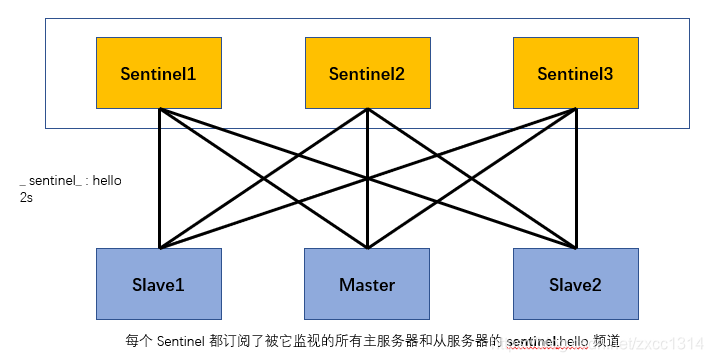
- 每個 Sentinel 會以每兩秒一次的頻率, 通過釋出與訂閱功能, 向被它監視的所有主伺服器和從伺服器的 sentinel:hello 頻道傳送一條資訊, 資訊中包含了 Sentinel 的 IP 地址、埠號和執行 ID (runid)。Sentinel 之間也通過該頻道互相交換資訊。
主觀下線和客觀下線
Redis 的 Sentinel 中關於下線(down)有兩個不同的概念:
- 主觀下線指的是單個 Sentinel 例項對伺服器做出的下線判斷。
- 客觀下線指的是多個 Sentinel 例項在對同一個伺服器做出SDOWN 判斷, 並且通過 SENTINEL is-master-down-by-addr 命令互相交流之後, 得出的伺服器下線判斷。最後當達成這一共識的sentinel個數達到前面說的quorum設定的這個值時,就會對該master節點下線進行故障轉移。quorum的值一般設定為sentinel個數的二分之一加1,例如3個sentinel就設定2
故障轉移
領導者選舉
選舉出一個sentinel節點去完成故障轉移
- 每個做主觀下線的sentinel節點向其他sentinel節點發送上面那條命令,要求將它設定為領導者。
- 收到命令的sentinel節點如果還沒有同意過其他的sentinel傳送的命令(還未投過票),那麼就會同意,否則拒絕。
- 如果該sentinel節點發現自己的票數已經過半且達到了quorum的值,就會成為領導者
- 如果這個過程出現多個sentinel成為領導者,則會等待一段時間重新選舉。
master轉移
- 選擇slave-priority(slave節點優先順序配置)最高的slave節點,(預設都是一樣的)例如:如果我們有兩臺slave在兩臺機器上,一臺配置較高,我們希望當master掛掉優先選配置高的,就可以配置該值為slave中最高的。如果存在最高則返回,不存在繼續
- 選擇複製偏移量最大的節點(複製得最完整,與master節點的資料一致性更高),如果存在則返回,不存在繼續
- 如果以上兩個條件都不滿足,選runId最小的(啟動最早的)。
轉移完成之後
sentinel通知客戶端變更節點資訊,客戶端連線新master。如果故障master重新上線,則成為slave節點。
二、Cluster
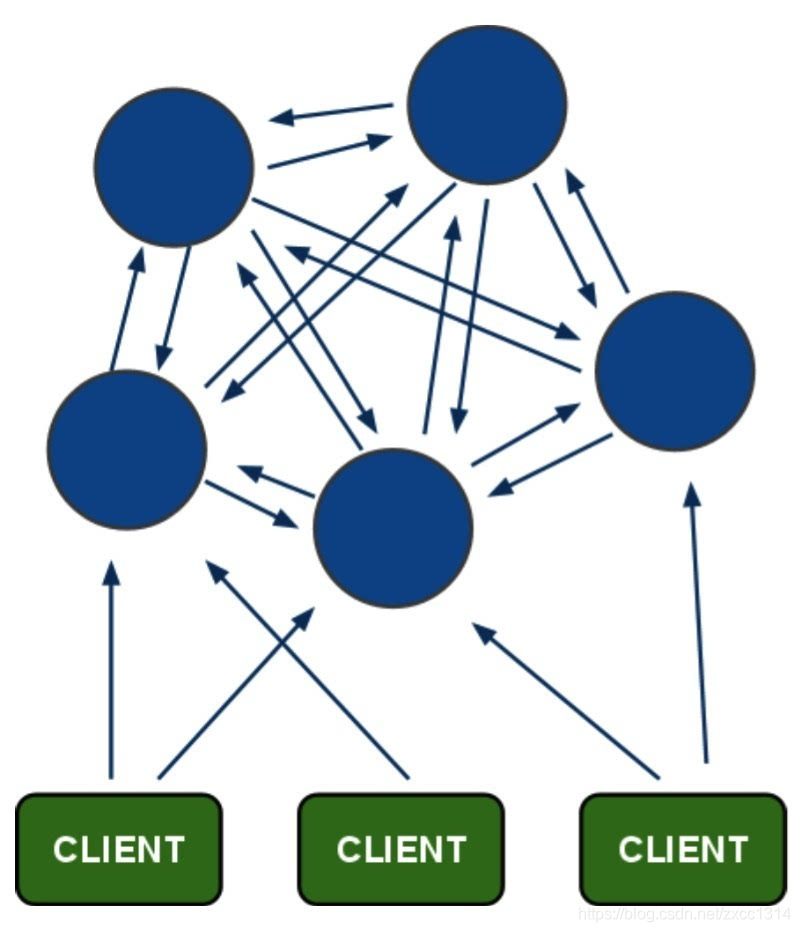
Redis-Cluster採用無中心結構,每個節點儲存資料和整個叢集狀態,每個節點都和其他所有節點連線,節點間使用 gossip 協議來傳播叢集的資訊。其redis-cluster架構圖如下:
雜湊槽演算法
HASH_SLOT = CRC16(key) mod 16384
鍵空間被分割為 16384 槽(slot),叢集的最大節點數量是 16384 個(然而建議最大節點數量設定在1000這個數量級上)。所有的主節點都負責 16384 個雜湊槽中的一部分。
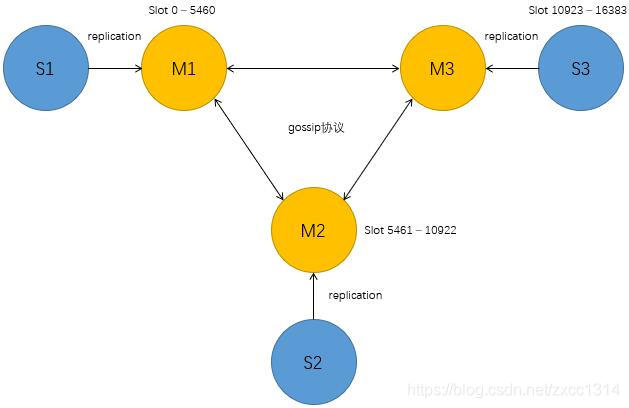
假設有三個節點,則每個節點槽區間為:
節點A覆蓋0-5460;
節點B覆蓋5461-10922;
節點C覆蓋10923-16383.
gossip 協議
gossip 協議廣播,叢集節點通過PING/PONG訊息實現節點通訊,傳播節點槽資訊。
每個節點都儲存其他節點的資訊:
- 節點的 IP 地址和 TCP 埠號。
- 各種標識。
- 節點使用的雜湊槽。
- 最近一次用叢集連線傳送 ping 包的時間。
- 最近一次在回覆中收到一個 pong 包的時間。
- 最近一次標識節點失效的時間。
- 該節點的從節點個數。
- 如果該節點是從節點,會有主節點ID資訊。
Redis Cluster主從模式
redis cluster 為了保證資料的高可用性,加入了主從模式,一個主節點對應一個或多個從節點,主節點提供資料存取,從節點則是從主節點拉取資料備份,當這個主節點掛掉後,就會有這個從節點選取一個來充當主節點,從而保證叢集不會掛掉。
其三主三從架構如下所示:
叢集部署
搭建叢集工作分為三步:
- 準備節點
- 節點握手 (MEET訊息)
- 分配槽(addslots)
手動MEET、addslots部署參考:https://blog.csdn.net/men_wen/article/details/72871618
Redis官方redis-trib.rb工具部署參考:https://www.cnblogs.com/wuxl360/p/5920330.html
叢集擴容與收縮
參考:https://blog.csdn.net/men_wen/article/details/72896682
增加或減少主節點時,叢集會將遷移部分槽。其餘主節點更新節點使用的雜湊槽情況。
MOVED 重定向
客戶端連線叢集中某個主節點,如果剛好這個節點就是對應這個雜湊槽,那麼這個查詢就直接被節點處理掉。否則這個節點會檢視它內部的 雜湊槽 -> 節點ID 對映,然後給客戶端返回一個 MOVED 錯誤。
ASK 重定向
ASK與MOVED類似,只不過ASK重定向發生在虛擬槽的遷移過程中。
故障檢測
Redis的gossip協議還可以通過PING/PONG訊息實現傳播主從狀態、節點故障資訊等。因此故障檢測也是就是通過訊息傳播機制實現的。
PFAIL 標識:
當一個節點在超過 NODE_TIMEOUT 時間後仍無法訪問某個節點,那麼它會用 PFAIL 來標識這個不可達的節點。無論節點型別是什麼,主節點和從節點都能標識其他的節點為 PFAIL。
FAIL 標識:
當下面的條件滿足的時候,會使用這個機制來讓 PFAIL 狀態升級為 FAIL 狀態:
- 某個節點,我們稱為節點 A,標記另一個節點 B 為 PFAIL。
- 節點 A 通過 gossip 欄位收集到叢集中大部分主節點標識的節點 B 的狀態資訊。
- 如果叢集中過半數的主節點都認為節點 B 標記為 PFAIL 狀態,或者在 NODE_TIMEOUT * FAIL_REPORT_VALIDITY_MULT 這個時間內是處於 PFAIL 狀態。
如果以上所有條件都滿足了,那麼節點 A 會:
- 標記節點 B 為 FAIL。
- 向所有可達節點發送一個FAIL 訊息。
FAIL 訊息會強制每個接收到這訊息的節點把節點 B 標記為 FAIL 狀態。
故障轉移
當一個節點從節點發現自己正在複製的主節點進入了已下線狀態時,從節點將開始對下線主節點進行故障轉移,以下是故障轉移的執行步驟:
- 複製下線主節點的所有從節點裡面,會有一個從節點被選中(選舉過程下文會給出介紹)。
- 被選中的從節點會執行SLAVEOF no one命令,成為新的主節點。
- 新的主節點會撤銷所有對已下線主節點的槽指派,並將這些槽全部指派給自己。
- 新的主節點向叢集廣播一條PONG訊息,這條PONG訊息可以讓叢集中的其他節點立即知道這個節點已經由從節點變成了主節點,並且這個主節點已經接管了原本由已下線節點負責處理的槽。
- 新的主節點開始接收和自己負責處理的槽有關的命令請求,故障轉移完成。
紀元(epoch):
-
配置紀元(config epoch):
configEpoch是類似於一個版本號的東西,是關於cluster slot的一個版本號。一般來說,每一個master節點的configEpoch都是不同的(假如存在相同的configEpoch,會有衝突處理演算法來保證每個節點的configEpoch不同),並且每一個節點的configEpoch不會輕易發生改變(節點改變的情況見下面)。由於configEpoch是單調遞增的,因此當某一個節點的configEpoch改變之後,其它節點就會更新對該節點所聲稱擁有的slots的認識。 -
當前紀元(current epoch):
configEpoch只是關於slots分佈的一個版本號,而currentEpoch才是真正的邏輯時鐘。通過gossip協議,叢集中的currentEpoch總是一致的(當然,特殊情況除外,如網路分割槽發生等)。currentEpoch越高,代表節點的配置或者操作越新。
config epoch的變化:
- 在叢集初始化的時候,通過讀取配置檔案nodes.conf中的configEpoch值,對每一個節點的configEpoch進行賦值
- 叢集重置(resetCluster)時,configEpoch被置為0
- 當一個槽遷移到某一個節點之後,尤其是叢集發生resharding的時候;當發生故障轉移(failover force)時,節點的configEpoch會被置為currentEpoch + 1
- 若兩個節點的configEpoch相同,並且當前節點的nodename更大,則當前節點的configEpoch=currentEpoch+1(configEpoch發生衝突時的處理)
- 當master發生fail的之後,slave獲得大多數master的投票時,設定slave的configEpoch為failover_auth_epoch
- cluster set-config-epoch命令強制設定configEpoch
- 當接受到其它節點發來的gossip訊息的時候,設定configEpoch為訊息中得configEpoch
選舉過程
從節點通過廣播一個 FAILOVER_AUTH_REQUEST 資料包給叢集裡的每個主節點來請求選票。然後從節點最大等待NODE_TIMEOUT*2的時間來回復(但總是至少2秒)。
一旦一個主節點給這個從節點投票,會回覆一個 FAILOVER_AUTH_ACK,並且在 NODE_TIMEOUT * 2 這段時間內不能再給同個主節點的其他從節點投票。這不是保證安全性所必需的,但對於防止多個從節點在大約同一時間被選中(即使使用不同的configEpoch)非常有用,這通常是不需要的。
從節點會忽視所有帶有的時期(epoch)引數比 currentEpoch 小的迴應(ACKs),這樣能避免把之前的投票的算為當前的合理投票。
一旦從節點接收到大於等於N/2+1個主節點的ACK,它就贏得了選舉。否則,如果在兩次NODE_TIMEOUT期間未達到多數(但總是至少2秒),則選舉將中止,並且在NODE_TIMEOUT * 4之後將再次嘗試選舉(並且始終至少4秒)。
三、Twemproxy
待補充
《Redis設計與實現》
https://redis.io/topics/sentinel
https://redis.io/topics/cluster-tutorial
https://redis.io/topics/cluster-spec
https://my.oschina.net/u/3371837/blog/1790026
https://blog.csdn.net/fengshizty/article/details/51368004/
https://blog.csdn.net/men_wen/article/category/6769467/1
https://blog.csdn.net/qq1137623160/article/details/79184686
https://www.cnblogs.com/wuxl360/p/5920330.html
https://www.jianshu.com/p/92183354183e