
[InnoDB]性別欄位為什麼不適合加索引
阿新 • • 發佈:2018-12-23
表結構與資料
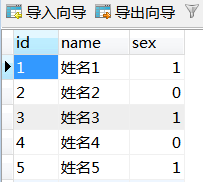
id為主鍵,id為奇數sex=1,id為偶數sex=0
sex=0,50000條資料;sex=1,50000條資料
CREATE TABLE `people` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`sex` tinyint(1) unsigned DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=100001 DEFAULT CHARSET=utf8;
CREATE 新增的索引型別
測試結果:
SELECT * FROM people WHERE sex = 0;
SELECT * FROM people WHERE sex = 1;
| 無sex索引 | 有sex索引 | |
|---|---|---|
| sex=0 |  |
 |
| sex=1 |  |
 |
可以看到相同的sql,加索引之後比不加索引慢許多。
原因
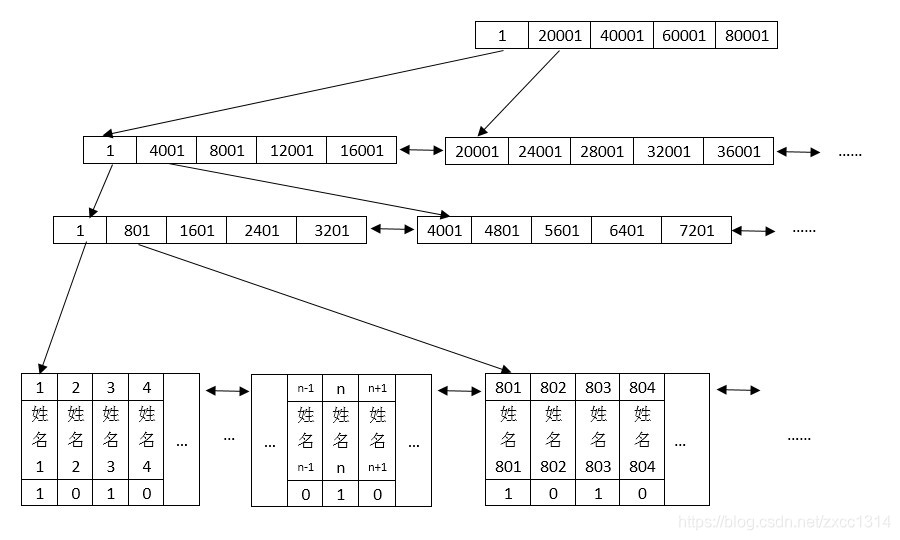
在InnoDB中每一個表都會有聚集索引,如果表定義了主鍵,則主鍵就是聚集索引。一個表只有一個聚集索引,其餘為普通索引。
索引的結構是B+樹,非葉子節點儲存key,葉子節點儲存value。
- 聚集索引,葉子節點儲存行記錄,InnoDB索引和記錄是儲存在一起的。
- 普通索引,葉子節點儲存了主鍵的值。
以上表的索引結構示例如下(PS:索引結構僅供參考)
聚集索引
sex列普通索引
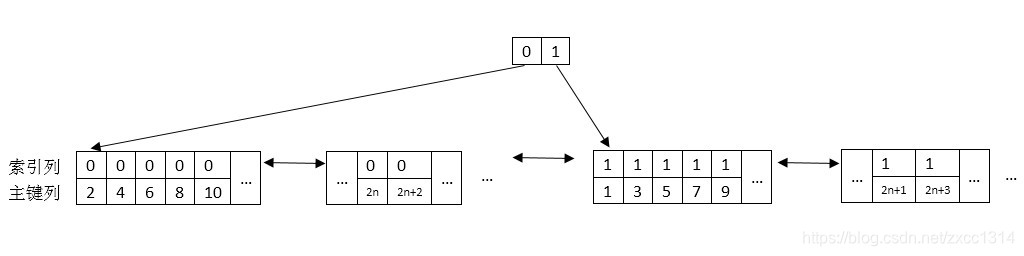
在使用普通索引查詢時,會先載入普通索引,通過普通索引查詢到實際行的主鍵。再使用主鍵通過聚集索引查詢相應的行。以此迴圈查詢所有的行。
若直接全量搜尋聚集索引,則不需要在普通索引和聚集索引中來回切換。
相比兩種操作的總開銷可能掃描全表效率更高。
感謝:
https://mp.weixin.qq.com/s/tmkRAmc1M_Y23ynduBeP3Q
https://blog.jcole.us/innodb/
https://blog.csdn.net/u012978884/article/details/52416997?utm_source=blogxgwz0
https://draveness.me/mysql-innodb