
基於Kubernetes的容器雲在萬達的落地_Kubernetes中文社群

圖片來源網路,與本文無關
本文是DockOne微信群分享內容,作者:陳強,萬達網路資深工程師,畢業於華東師範大學。目前在萬達網路科技集團雲公司基礎架構部負責Kubernetes與Docker的落地與實踐工作。曾先後就職於Intel、IBM和愛奇藝。在雲端計算領域長年搬磚,對Mesos/Kubernetes/Docker等有較深入的研究。
【編者的話】容器生態是現在非常火熱的技術生態之一,個人認為它主要囊括著四個方面的技術棧:一是容器核心技術棧(包括 Docker、rkt 及第三方公司自主研發的容器 Engine 等);二是容器基礎技術棧(包括容器網路、儲存、安全及服務發現等);三是容器編排技術棧(包括
萬達容器雲平臺支援快速部署、彈性伸縮、負載均衡、灰度釋出、高效運維及微服務等特性。使用者可以基於 Dashboard 簡單方便地上線和管理著各自業務。目前在我們的容器雲平臺上,平穩高效執行著近 400 款包括支付、酒店等核心業務,管理著公司上萬個容器。經歷住了雙旦、618 及雙 11 等大型活動的考驗。
一、容器雲的平臺高可用架構與部署
“經濟基礎決定上層建築”,對於整個容器雲平臺來說,Kubernetes 平臺就是我們的“經濟基礎”,所以在建設之初我們為了保證平臺的穩定、高可用還是做了不少工作。先來看看 Kubernetes 平臺的建設涉及到的幾個技術點:
- 元件的高可用性如何保證?
- 元件以何種方式部署安裝?
- 叢集以何種方式快速擴縮容?
- 如何實現環境的批量配置及元件的批量升級?
為了較好的描述這些,我畫了一張我們容器雲中 Kubernetes 各元件高可用架構與部署圖,請見:
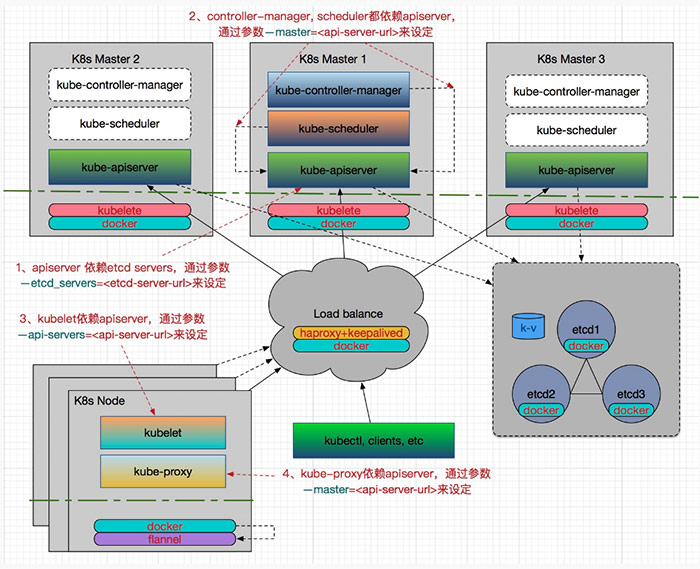

Kubernetes 所有元件都容器化了,而不採用二進位制安裝的方式。這樣對於元件的部署、配置更新和升級等都比較容易,只需要先安裝好 Docker,提前做好映象,然後直接 docker run –restart=always –name xxx_component xxx_component_image:xxx_version就可以了,這裡 –restart=always 非常重要,用來保證主機重啟後或由於突發狀況引起的非錯誤性退出後元件服務自動恢復。
注意在升級過程中,為了減少元件服務的宕機時間,需要提前下載好新制作的映象版本,因為如果映象挺大的話,在 docker restart 進行更新前會耗費一些時間在 docker pull 上面。
在批量部署方面,我們採用 Ansible 工具。由於 Kubernetes 叢集部署的文件網上蠻多的,所以這裡就簡要介紹一下元件的高可用部分。我們都知道 Kubernetes 實現了應用的高可用,而針對 Kubernetes 自身的 HA,主要還是在 Etcd 和 Kubernetes Master 元件上面。
1、 Etcd 的高可用性部署
Etcd 使用的是 V3(3.0.3)的版本,比 V2 版本效能強很多。Etcd 元件作為一個高可用強一致性的服務發現儲存倉庫,它的 HA 體現在兩方面:一方面是 Etcd 叢集自身需要以叢集方式部署,以實現 Etcd 資料儲存的冗餘、備份與高可用;另一方面是 Etcd 儲存的資料需要考慮使用可靠的儲存裝置。
為了展示一下元件容器化在部署方面帶來的一些便利效果,以 Etcd 的部署為例,先在 Ansible inventory檔案中規劃好 Etcd 的分組資訊,一般是採用 3 臺做為叢集即可。例如:
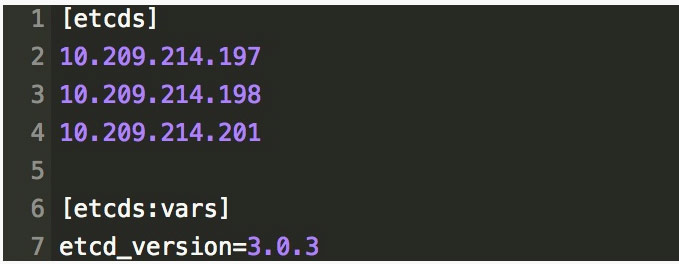
然後編寫好類似如下的 template 檔案,就可以用 Ansible Playbook 實現一鍵秒級的部署 Etcd 叢集了,注意我這裡使用了主機 IP 作為 Etcd 的名字。
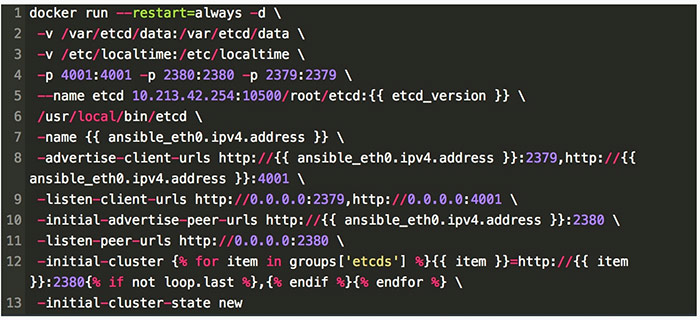
如果需要升級則只需要修改一下 etcd_version 並提前拉取新版本映象,重新跑一下 ansible-playbook –limit=etcds -i hosts/cd-prod k8s.yaml –tags etcd 即可完成秒級升級,這樣一般顯得簡潔易用。當然 Etcd 在升級過程中還涉及到資料的遷移備份等,這個可以參考官方文件進行。
2、Kubernetes Master 的高可用性部署
Kubernetes 的版本我們更新的不頻繁,目前使用的是 V1.6.6。Master 的三個元件是以 Static Pod 的形式啟動並由 kubelet 進行監控和自動重啟的,而 kubelet 自身也以容器的方式執行。
對於 kube-apiserver 的 HA,我們會配置一個 VIP,通過 haproxy 和 keepalived 來實現,其中 haproxy 用於負載均衡,而 keepalived 負責對 haproxy 做監控以保證它的高可用性。後面就可以通過 VIP:Port 來訪問 apiserver。
對於 kube-controller-manager 和 kube-scheduler 的 HA,由於它們會修改叢集的狀態,所以對於這兩個元件,高可用不僅要保證有多個例項,還需要保證在多個例項間實現 leader 的選舉,因此在啟動引數中需要分別設定 –leader-elect=true。
對於 Kubernetes 叢集的擴縮容,只需要採用 Ansible 進行批量操作或者 kubectl 命令(一般需要用到 drain, cordon , uncordon 等)完成即可。另外我們還需要注意一下圖中標註的各元件啟動時依賴的引數配置,這些比較容易搞混。
二、容器雲的技術架構介紹
目前使用的容器雲架構方案如圖所示,我將其分為四個部分,每個部分包含對應的容器技術棧,下面對於主流的技術介紹如下:
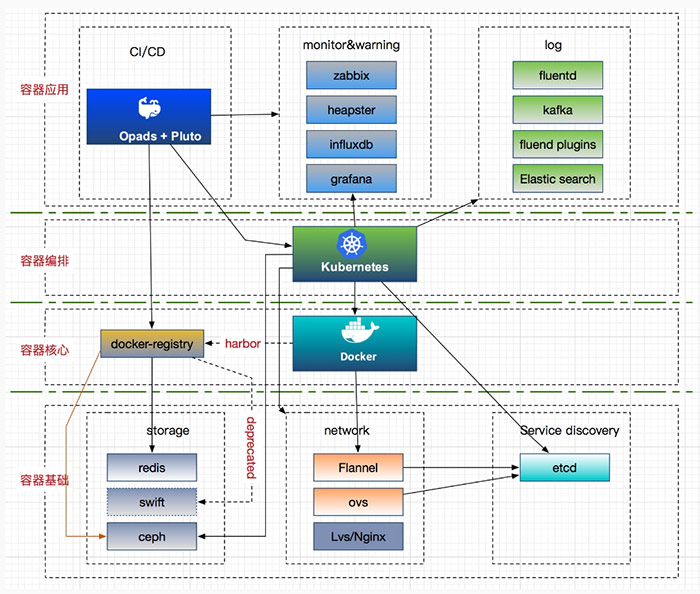
1、儲存方案
後端儲存主要採用 ceph 驅動,這裡主要介紹它在有狀態服務和 docker-registry 兩方面的應用。
有狀態是應用程式的高階需求,它們需要在 Pod 掛了特別是飄移到其他 Node 後,可以持續的訪問後端儲存。因此,Kubernetes 通過網路儲存提供了豐富的 Persistent Volume 支援,比如:GCE 的 pd,AWS 的 ebs,還有 GlusterFS,Ceph 等先進的分散式檔案系統。我們目前使用了 Ceph 的 rbd 來支援有狀態服務。Kubernetes 叢集環境中,由於所有的元件採用容器化部署,因此除了在主機上安裝 ceph-common 之外,還需要在 kubelet、kube-controller-manager 容器中安裝它,而且在啟動時掛載如下三個 volume,其他的與二進位制方式差不多:

rbd 支援動態供應,支援單節點讀寫,多節點讀,但不支援多節點寫。如果有業務需要多節點寫的話,rbd 就比較受限制。目前由於只有 GlusterFS 既允許動態供應,又支援單節點和多節點讀寫,所以我們也正在調研其相關使用。
docker-registry 做為容器的核心部分,起初我們採用 Swift 作為後端儲存,為了提高 push/pull 的效率,採用 Redis 作為 Metadata 快取,然後直接以容器的方式執行官方提供的映象,比如:

具體的 config.yml 配置,詳見:docker-registry 官方配置。但後來為了保證 docker-registry 的高可用,我們採用 Harbor 做 HA,並以 pod 的形式執行在 Kubernetes 叢集上,映象資料以及 Harbor-db全部通過 Ceph 的 PV 來掛載,這樣就保證在 Harbor 主機掛了或者 Pod 故障後,Harbor 也可以 HA 了,同時我們也不需要額外維護 Swift 了。
另外注意一個問題,由於 PV,StorageClass 都侷限於單個 Namespace 下,所以對於想通過 Namespace 來區分多租戶使用動態儲存的情況目前是不滿足的。
2、網路方案
底層容器網路我們最初使用的是官方推薦的 Flannel,現在部分叢集已經由 Flannel 切換成了 OVS 。 Flannel 可以很容易的實現 Pod 跨主機通訊,但不能實現多租戶隔離,也不能很好的限制 Pod 網路流量,所以我們網路同事開發了 K8S-OVS 元件來滿足這些需求。它是一個使用 Open VSwitch 為 Kubernetes 提供 SDN 功能的元件。該元件基於 OpenShift SDN 的原理進行開發。由於 OpenShift 的 SDN 網路方案和 OpenShift 自身的程式碼耦合在一起,無法像 Flannel 和 Calico 等網路方案以外掛的方式獨立的為 Kubernetes 提供服務,所以開發了 K8S-OVS 外掛,它擁有 OpenShift 優秀的 SDN 功能,又可以獨立為 Kubernetes 提供服務。
K8S-OVS 支援單租戶模式和多租戶模式,主要實現瞭如下功能:
- 單租戶模式直接使用 Openvswitch+Vxlan 將 Kubernetes 的 Pod 網路組成一個大二層,所有 Pod 可以互通。
- 多租戶模式也使用 Open vSwitch+Vxlan 來組建 Kubernetes 的 Pod 網路,但是它可以基於 Kubernetes 中的 Namespace 來分配虛擬網路從而形成一個網路獨立的租戶,一個 Namespace 中的 Pod 無法訪問其他 Namespace 中的 Pod 和 Service。
- 多租戶模式下可以對一些 Namespace 進行設定,使這些 Namespace 中的 Pod 可以和其他所有 Namespace 中的 Pods 和 Services 進行互訪。
- 多租戶模式下可以合併某兩個 Namespace 的虛擬網路,讓他們的 Pods 和 Services 可以互訪。
- 多租戶模式下也可以將上面合併的 Namespace 虛擬網路進行分離。
- 單租戶和多租戶模式下都支援 Pod 的流量限制功能,這樣可以保證同一臺主機上的 Pod 相對公平的分享網絡卡頻寬,而不會出現一個 Pod 因為流量過大佔滿了網絡卡導致其他 Pod 無法正常工作的情況。
- 單租戶和多租戶模式下都支援外聯負載均衡。
下面舉例解釋一下:
合併是指兩個不同租戶的網路變成一個虛擬網路從而使這兩個租戶中的所有 Pod 和 Service 能夠互通;分離是指標對合並的兩個租戶,如果使用者希望這兩個租戶不再互通了則可以將他們進行分離;全網化是指有一些特殊的服務需要能夠和其他所有的租戶互通,那麼通過將這種特殊的租戶進行全網化操作就可以實現。
不同租戶的網路隔離是通過為每個 Kubernetes 名稱空間分配一個 VNI(VXLAN 中的概念)來實現的,在 VXLAN 中不同的 VNI 可以隔離不同的網路空間。K8S-OVS 將具體的 Kubernetes 名稱空間和 VNI 的對應關係儲存在 Etcd 中,如下:
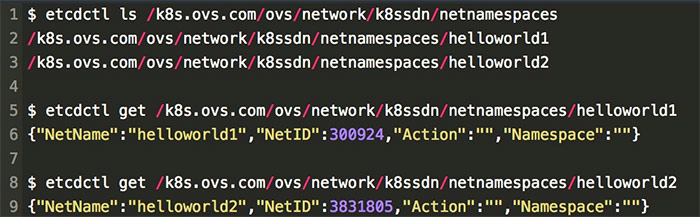
這是在我們通過 Kubernetes 建立 Namespace 時,K8S-OVS 自動檢測併為我們建立的。其中 NetName 是指租戶的 Kubernetes 名稱空間;NetID 是指為該租戶分配的VNI;Action 是指可以對該租戶網路進行的操作,它包括 join :合併, isolate :分離, global :全網化,其中 join 需要指定上面的第四個引數 Namespace,用於表示需要和哪個租戶進行合併,其他兩個操作則不需要設定 Namespace。
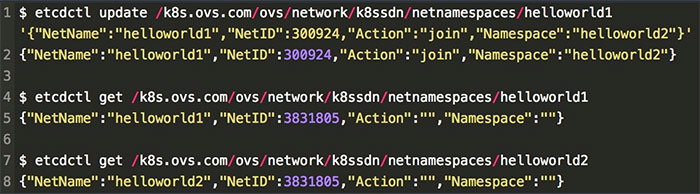
合併之後觀察 helloworld1 和 helloworld2 ,發現兩個租戶的 NetID 變為相同的了。這樣兩個網路的 Pod 和 Service 就可以相互訪問了。其他場景一樣,通過 etcdctl update 來控制 Action 從而改變 NetID 來實現租戶的隔離與互通。這裡不過多演示。
在應用方面,我們實現了 LVS 的四層,Ingress(基於 Nginx+Ingress Controller) 的七層負載均衡,各 Kubernetes 叢集環境中陸續棄用了 Kubernetes 自帶的 kube-proxy 及 Service 方案。
3、CI/CD 方案
CI/CD(持續整合與部署)模組肩負著 DevOps 的重任,是開發與運維人員的橋樑,它實現了業務(應用)從程式碼到服務的自動上線,滿足了開發過程中一鍵的持續整合與部署的需求。
我們採用了前端基於 Opads(一個比較成熟的線上打包平臺)和後端 Pluto(一個將 Kubernetes APIServer 的介面進行封裝,並提供 RestfulAPI 服務的庫專案)的方案。目前通過該平臺上線的業務有近 400 款。其架構圖大致如下:
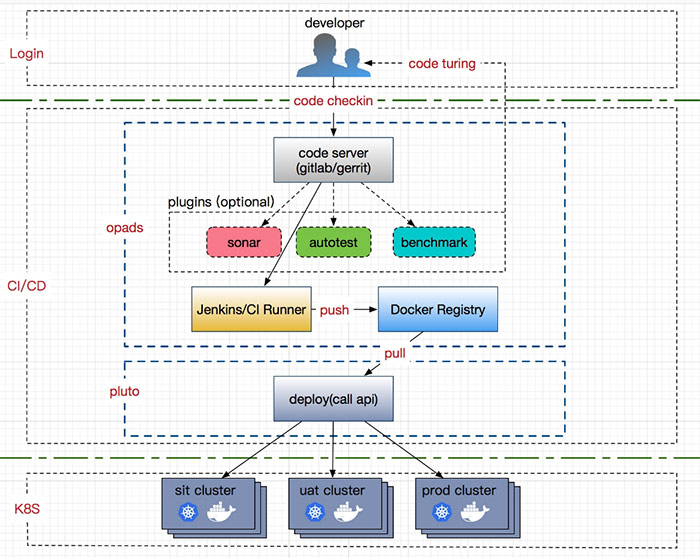

業務程式碼從公司內部的 GitLab/Gerrit 中拉取後,使用者選擇不同的分支版本(比如:sit/uat/prod)經過 Jenkins 構建後,生成相應的映象並 Push 到相應的映象倉庫中,底層 CD 模組從相應的倉庫上線到相應的 Kubernetes 叢集(sit/uat/prod)中,而不需要 care 底層平臺實現。
在整個 CI/CD 過程中,基礎映象的製作比較關鍵,我們按不同的業務分類提前製作不同的應用映象(如:Tomcat、PHP、Java、NodeJS等)並打上所需的版本號,後面原始碼既可以 mount 到相應的容器目錄,也可以利用在 Dockerfile 的 ONBUILD 命令完成業務程式碼的載入。掛載的方式優點是比較靈活,也不需要重複構建,上線效率高;缺點是對於基礎映象環境的依賴較高,如果一個業務的基礎映象一直未改動,但程式碼中又有了對新元件庫的呼叫或者依賴,則很容易失敗。onbuild 的方式和 mount 方式恰好相反,它每次都進行 build,解決了環境的依賴,後面版本回滾也方便,缺點是需要每次進行映象構建,效率低。這些看業務自己的選擇。
我們提供的基礎映象版本在業務上線的時候,業務開發者可以提前搜尋確定基礎映象是否存在,如果不存在需要提 Jira 單子後,交由我們進行製作,部分截圖如下:

之後,業務可以通過選擇程式碼分支、版本等上線服務。之後就可以看到上線的業務詳情了,包括 Pod 副本個數,存活時間,名字,建立時間,所在的 Kubernetes 節點及 node selector 等。也可以通過基於 Gotty 實現的 Web console 登入檢視業務容器,如圖所示。
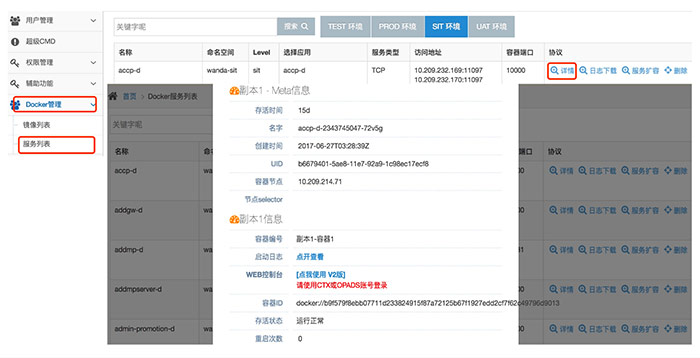

我們還實現了服務擴縮容,彈性伸縮(HPA)、負載均衡、灰度釋出等,也加入了程式碼質量檢查(Sonar)、自動化測試及效能測試外掛等,這些都是 CI/CD PaaS 平臺的重要組成部分。
4、容器監控與告警方案
容器監控的物件主要包括 Kubernetes 叢集(各元件)、應用服務、Pod、容器及網路等。這些物件主要表現為以下三個方面:
- Kubernetes 叢集自身健康狀態監控(5 個基礎元件、Docker、Etcd、Flannel/OVS 等)
- 系統性能的監控,比如:CPU、記憶體、磁碟、網路、filesystem 及 processes 等;
- 業務資源狀態監控,主要包括:rc/rs/deployment、Pod、Service 等;
Kubernetes 元件相關的監控,我們寫了相關的 shell 指令碼,通過 crond 開啟後監控各元件狀態。
容器相關的監控,我們採用傳統的 Heapster+InfluxDB+Grafana 方案:
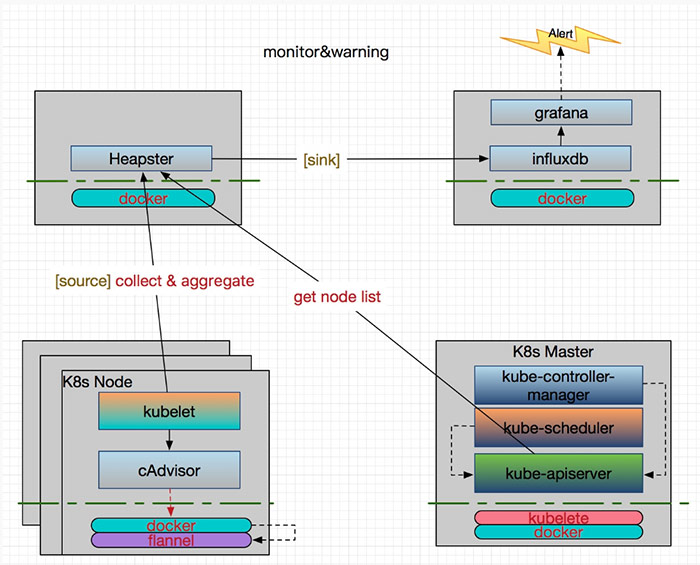

Heapster 首先從 Kubernetes Master 獲取叢集中所有 Node 的資訊,每個 Node 通過 kubelet 呼叫 cAdvisor API 來採集所有容器的資料資訊(資源使用率和效能特徵等)。這樣既拿到了 Node 級別的資源使用狀況資訊,又拿到了容器級別的資訊,它可以通過標籤來分組這些資訊,之後聚合所有監控資料,一起 sink到 Heapster 配置的後端儲存中(Influxdb),通過 Grafana 來支援資料的視覺化。所以需要為 Heapster 設定幾個重要的啟動引數,一個是 –source 用來指定 Master 的 URL 作為資料來源,一個是 –sink 用來指定使用的後端儲存系統(InfluxDB),還有就是 –metric_resolution 來指定效能指標的精度,比如:30s 表示將過去 30 秒的資料進行聚合並存儲。
這裡說一下 Heapster 的後端儲存,它有兩個,一個是 metricSink,另一個是 influxdbSink。metricSink 是存放在本地記憶體中的 metrics 資料池,會預設建立,當叢集比較大的時候,記憶體消耗會很大。Heapster API 獲取到的資料都是從它那獲取的。而 influxdbSink 接的是我們真正的資料儲存後端,在新版本中支援多後端資料儲存,比如可以指定多個不同的 influxDB 。
通過 Grafana, 使用者可以使用各種正則表示式或者選項檢視自己的業務監控詳情,還可以按系統性能(CPU、記憶體、磁碟、網路、filesystem)進行排序檢視等等。
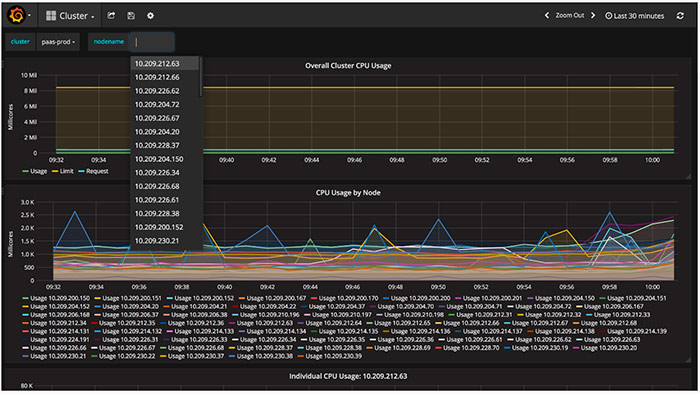

當監控到一定的數量級,超過某個閾值時,將產生告警。雖然 Grafana 目前支援郵件進行一些簡單的告警,但我們還是通過制定一些監控點、告警機制、告警等級等,然後接入公司內部現有 Zabbix 平臺來進行告警。
郵件告警示例如下:

5、日誌方案:
容器平臺的日誌系統一般包括:Kubernetes 元件的日誌,資源的事件日誌及容器所執行的應用的日誌。所以一個好的日誌系統至少需要 cover 到這幾塊。
日誌這塊一直是我們頭痛的地方,之前我們主要關心容器中的業務日誌,所以是直接將其日誌對接到公司的統一日誌平臺(Hippo)中。他們需要我們採用 Flume 來進行日誌採集,每個業務以 Pod 的方式執行 Flume ,在 Flume 中配置好 source, channel 和 sink 引數。source 用來指定業務掛載的日誌目錄,然後通過 channel 進行輸送,最後 sink 到後端的 Hippo 所使用的 Kafka 中。業務需要檢視日誌,則需要登入到 Hippo 平臺中。
這個方案有一些不如意的地方,比如:每個業務需要單獨額外執行一個 Flume 的 Pod,浪費資源;業務需要登入到另一個系統檢視,由於不是對接到我們的平臺中,不方便;另外由於 Hippo 是針對公司的統一的日誌平臺,不是容器雲專用的,經常會在高峰期響應慢,很難處理過來。所以我們決定設計一個全新的平臺,採用的方案是 Kubernetes 官方推薦的(Fluentd+Kafka+ES+ 自定義介面),具體架構如下:
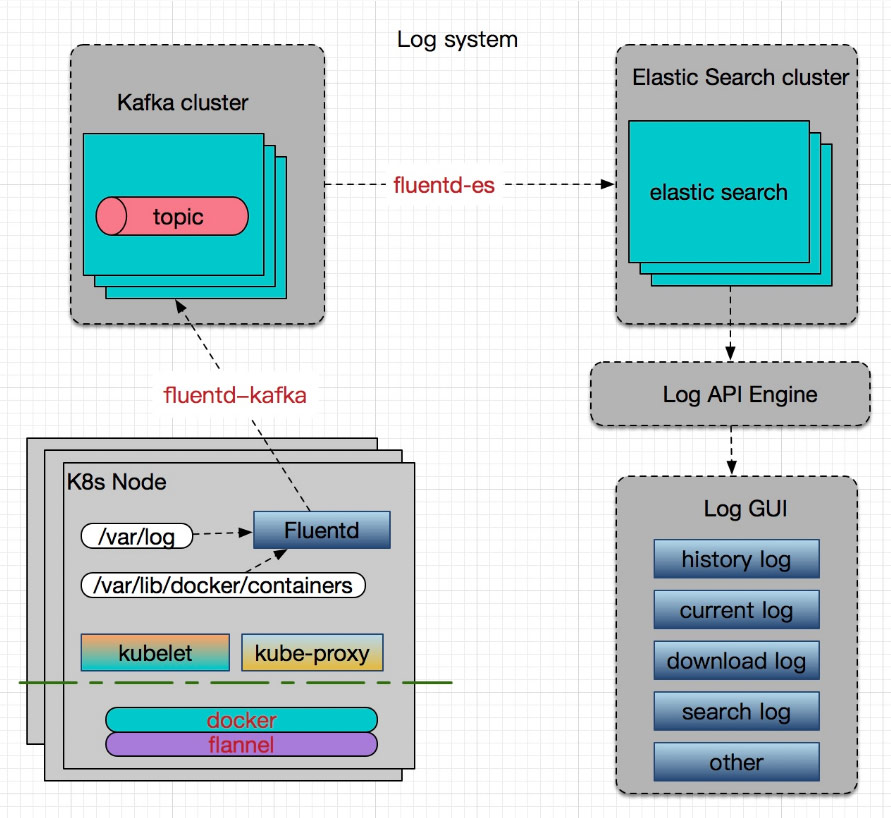
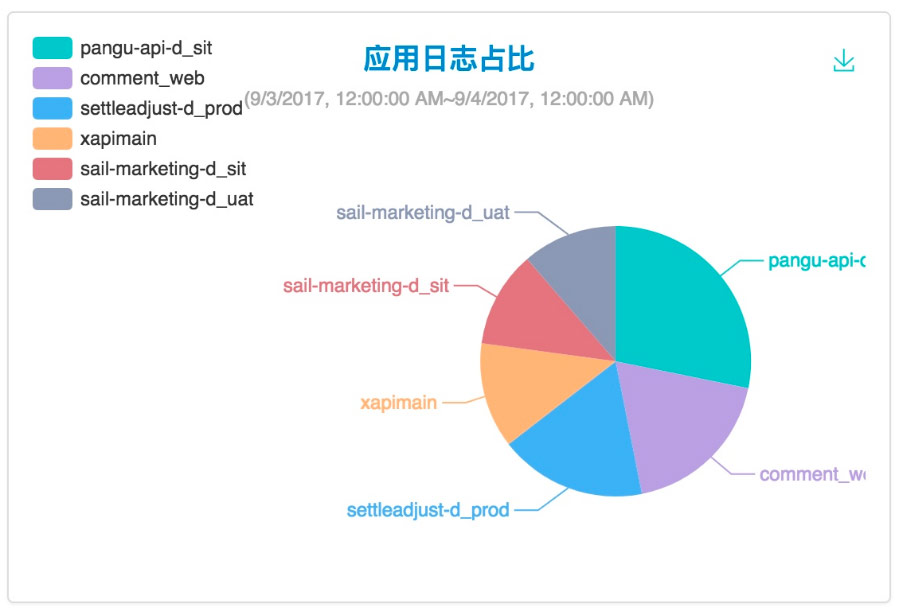
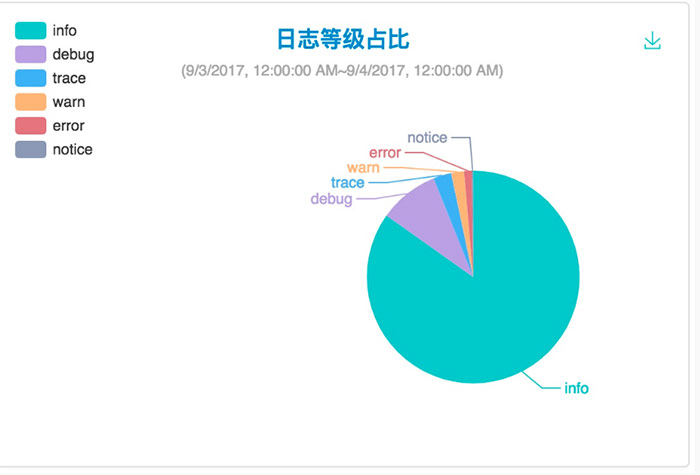
容器中輸出的日誌都會以 *-json.log 的命名方式儲存在 /var/lib/docker/containers/ 中,系統日誌都在 /var/log 中。Fluentd 以 Daemon Set 運行於所有的 Node 中進行資料採集,為了保證效能,引進了 Kafka 作為訊息佇列及日誌轉發,由於不想維護多個元件,中間轉發不用 Logstash ,所以需要引入了兩個 Fluentd 的外掛 fluentd-kafka 及 fluentd-es,前者用於推送資料到 Kafka,後者用於將資料推到 ElasticSearch 中。最後實現一個 Log API Engine 用於供上層 Log GUI 呼叫。這個 Engine 封裝了實時日誌、歷史日誌下載和查詢、應用日誌佔比、日誌等級佔比等 Restful API。下面是我們的部分截圖:
三、容器雲的填坑實踐
下面挑幾個坑說一下,並分享一下解決方法。
Docker 相關
早期由於混合使用了 Deployment 和 RC,此時如果使用了同名 Pod label 則會產生衝突,RC 會刪除 Deployment 後建立的 Pod,造成 Pod 的反覆建立與刪除,最終導致 Node 上的 Docker daemon 掛僵掉。原因是 Docker device mapper 互鎖而觸發 Linux kernel bug(特別是有大量的 outbound traffic 時),解決方法是升級核心到 3.10.0-327.22.2,或者新增核心補丁。
Kubernetes 相關
業務應用在升級過程中,如果 Docker 刪除出錯, 偶偶會導致 device mapper busy,則會顯示 Pod 一直在銷燬,但其實它的 Deployment 已經被刪除了,這種我們沒有找到很好的處理方法,現有 workaround 是先重啟 docker daemon,如果不能解決,再 reboot 主機。一般的做法是先 drain 掉所有的 pod,然後待重啟解決後,再 uncordon 回來。
在使用容器的方式部署 kubelet 時,我們發現刪除 Pod 時,在 apiserver log 中一直會出現 UnmountVolume TearDown secrect 資源失敗的錯誤。其中是當時在掛載 /var/lib/kubelet 時採用了 rw 的方式,這個問題困擾我們很久了,解決方法是加上 shared 即 –volume=/var/lib/kubelet:/var/lib/kubelet:rw,shared。
儲存相關
當某一 Pod 掛載 Ceph rbd 的 Volume 時,如果刪除 Pod,再重新建立,由於 PVC 被 lock 導致無法掛載,會出現 volume 死鎖問題。由於我們的 kubelet 是容器部署,而 ceph 元件是以掛載的方式開啟的,所以猜測可能是由於 kubelet 容器部署引起,但後面改用二進位制方式部署後也還是會出現 ceph lock。當時的版本是 V1.5.2,解決方法是升級到 V1.6.6 版本。
網路相關
在業務上線過程中,一定要進行規範化約束,比如,當時將 Flannel 升級到 K8S-OVS 網路升級過程中出現有些業務採用 Service 進行負載均衡的情況,這種依賴於 kube-dns,由於 Flannel 和 OVS 的網段不一樣,Service 層又沒有打通,導致以 Service 執行並通過 kube-dns 解析時會出問題,且網路不通,本可以採用新建一個以 OVS 同網段的 kube-dns 來完成不同網段的相容,但最後面發現該業務是根本不使用 Service,而是直接利用了 Pod,這樣非規範化上線的業務很容易導致升級相關的故障出現,猜測可能當時平臺建設初期手動上過業務,其實這方面我們也可以加些監控。
網路不穩定的時候,偶偶發現業務訪問突然就慢起來了,然後發現其 TIME_WAIT 會出現過高,這個是沒有對網路核心進行優化處理,此時需要設定 net.ipv4.tcp_tw_recycle = 1 和 net.ipv4.tcp_tw_reuse = 1 ,前者表示開啟 TCP 連線中 TIME-WAIT Sockets 的快速回收,後者表示允許將 TIME-WAIT Sockets 重新用於新的 TCP 連線。當然還有其他網路核心優化。
告警相關
CPU load 是通過每個核的 running queue(待執行程序佇列)計算出來的,某些情況下 running queue 會變成 -1 也就是 4294967295。由於在 cpu 過載的時候,我們設定了告警,所以會被觸發,但其實這時的 CPU 負載是正常的。此時,如果通過 sar -q ,top,w,uptime 等看到的 running queue 都是有問題後的值,只有用 vmstat 檢視才是真實的。解決方法是重啟 Node,因為這個值只有在重啟後才會重置為零,或者升級核心補丁。