【翻譯】 TensorFlow如何工作
學習TensorFlow過程中讀的一篇文章,索性就翻譯出來,雖然收穫感覺不是很大。
原文地址:How TensorFlow Works
介紹
Google在2015年11越開源了TensorFlow系統。從那時起,TensorFlow成為了Github上Star數量最多的機器學習專案。
為什麼選擇TensorFlow?TensorFlow的流行有很多原因,最主要是因為計算圖(computational graph)的概念、自動微分(automatic differentiation)以及TensorFlow 基於python的api結構的可適配性。這些特性使得廣大程式設計師可以方便的使用TensorFlow解決現實中的問題。
Google的TensorFlow引擎採用了一種獨特的解決問題的方式。該方式使得解決機器學習的問題非常高效。我們將通過一些基礎的步驟來理解TensorFlow是如何工作的。理解TensorFlow的工作原理對於理解本書的餘下部分十分必要。
TensorFlow如何執行
首先,TensorFlow中的計算看起來都不是複雜難懂。這是由於TensorFlow處理計算的方式使得開發複雜的演算法變得簡單。本文將會通過虛擬碼教會你TensorFlow中的演算法是如何工作的。
TensorFlow目前相容三大主流作業系統(Windows、Linux和Mac)。本書僅會介紹TensorFlow中封裝的Python庫。本書使用Python3.X(https://www.python.org)和TensorFlow0.12+(https://www.tensorflow.org)。TensorFlow可以執行在CPU上,當然在GPU上執行更快,相容NVidia Compute Capability 3.0+顯示卡。如果想跑在GPU上,你需要下載安裝NVidia Cuda工具包(https://developer.nvidia.com/cuda-downloads)。一些特性依賴於當前安裝的Python包如:Scipy、Numpy和Scikit-Learn等。
TensorFlow演算法總覽
現在我們開始介紹Tensorflow演算法的一般流程。大多數遵循下述流程。 1、匯入或生成資料
所有的機器學習演算法都依賴於資料。在本書中,我們既會生成資料也會使用外部資料。有時使用生成的資料更佳,因為我 們想要可預知的結果。其他情況下,我們會訪問公共資料,第8部分會介紹這部分內容。
2、轉換並標準化資料
原始資料通常都不處在TensorFlow需要的正確的維度或型別下。因此,在使用前需要進行轉換。大多數演算法還會需要標準化資料,我們也會在此時做這些事情。TensorFlow中有內建的函式可以幫助我們標準化資料。
data = tf.nn.batch_norm_with_global_normalization 3、設定演算法引數
我們演算法通常會含有一組需要我們在程式中設定的引數。例如,迭代的次數,學習的速率或是其他我們選擇的確定的引數。最好是一起初始化這些引數以便使用者可以輕易的發現他們。
learning_rate = 0.01 iterations = 1000
4、初始化變數和佔位符
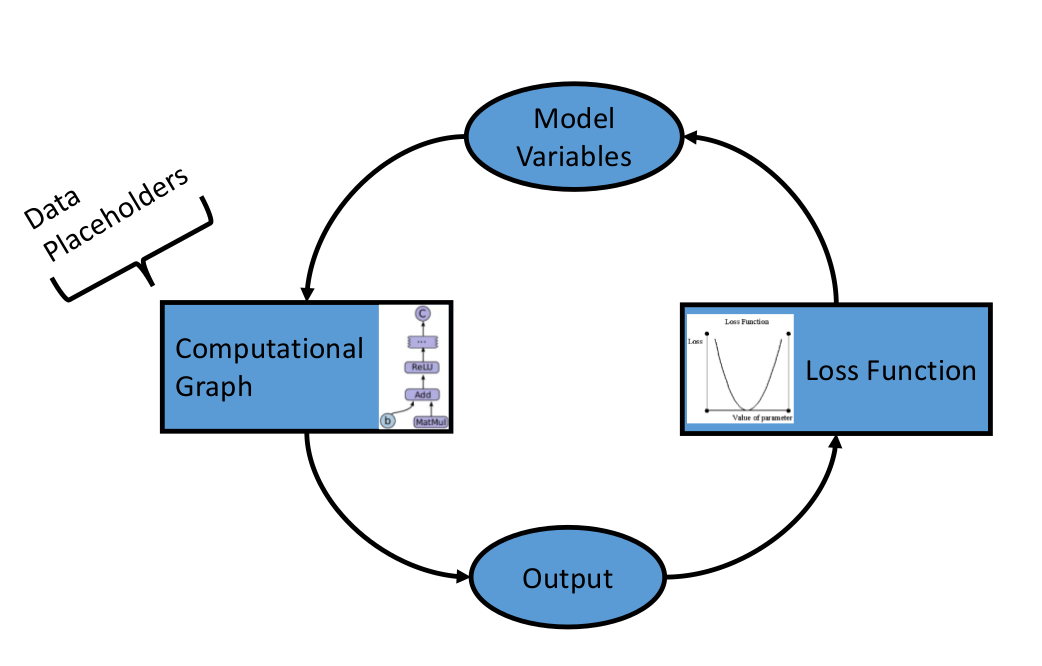
TensorFlow依賴於我們告訴它什麼可以修改什麼不可以修改。TensorFlow會在優化時修改變數,以最小化損耗函式。為了實現該目標,我們通過佔位符提供資料。我們需要同時初始化變數和佔位符的大小和型別,從而讓TensorFlow知道預期的結果。
5、定義模型結構
在有了資料、初始化了變數和佔位符之後,我們需要定義模型。這可以通過構造計算圖來實現。我們告訴TensorFlow需要在變數和佔位符上執行什麼操作以達到模型的預期。
y_pred = tf.add(tf.mul(x_input, weight_matrix), b_matrix)
[ ]
6、宣告損耗函式
定義模型後,我們必須評估輸出。因此,我們需要宣告損耗函式。損耗函式可以告訴我們預期結果和實際結果之間的差距。第二張第五部分會介紹不同型別的損耗函式。
loss = tf.reduce_mean(tf.square(y_actual – y_pred))
7、 初始化並訓練模型
現在我們一切就緒,我們建立了一個例項或圖並且通過佔位符傳入資料,然後讓TensorFlow改變變數的值以更好的預測和訓練資料。這裡有一個初始化計算圖的方式。
with tf.Session(graph=graph) as session:
...
session.run(...)
...
注意,我們也可以通過下面方式初始化圖
session = tf.Session(graph=graph) session.run(…)
8、(可選)評價模型 當我們構建並訓練模型之後,我們需要通過輸入新的資料來評價模型在某些特殊場景下的執行情況。
9、(可選)預測新的輸出 知道如何預期新的、從未見過的資料的產出同樣重要。我們可以通過已訓練的模型來進行預測。
總結
在TensorFlow中,我們需要在進行訓練和改變變數前設定資料,變數,佔位符和模型以提高預測的準確性。TensorFlow通過計算圖完成此過程。我們令其最小化損耗函式,TensorFlow通過修改模型中的變數達到此效果。TensorFlow可以追蹤模型的計算過程並且可以自動計算每個變數的漸變性,因此它知曉如何修改變數。也正是因為如此,我們可以發現在不同資料集上切換時非常簡單。
總而言之,TensorFlow上的演算法是被設計成可迴圈的。我們定義這種迴圈為計算圖。(1)通過佔位符傳遞資料,(2)計算計算圖的輸出,(3)通過損耗函式比較預期和實際輸出的差距,(4)參考後臺的自動迭代修改模型變數的值,最後(5)重複該過程直到達到結束條件。