
《Java 7併發程式設計實戰手冊》第五章Fork/Join框架
感謝人民郵電大學授權併發網釋出此書樣章,新書已上市,購買請進噹噹網
本章內容包含:
- 建立Fork/Join執行緒池
- 合併任務的結果
- 非同步執行任務
- 在任務中丟擲異常
- 取消任務
5.1 簡介
通常,使用Java來開發一個簡單的併發應用程式時,會建立一些Runnable物件,然後建立對應的Thread 物件來控制程式中這些執行緒的建立、執行以及執行緒的狀態。自從Java 5開始引入了Executor和ExecutorService介面以及實現這兩個介面的類(比如ThreadPoolExecutor)之後,使得Java在併發支援上得到了進一步的提升。
執行器框架(Executor Framework)
Java 7則又更進了一步,它包括了ExecutorService介面的另一種實現,用來解決特殊型別的問題,它就是Fork/Join框架,有時也稱分解/合併框架。
Fork/Join框架是用來解決能夠通過分治技術(Divide and Conquer Technique)將問題拆分成小任務的問題。在一個任務中,先檢查將要解決的問題的大小,如果大於一個設定的大小,那就將問題拆分成可以通過框架來執行的小任務。如果問題的大小比設定的大小要小,就可以直接在任務裡解決這個問題,然後,根據需要返回任務的結果。下面的圖形總結了這個原理。
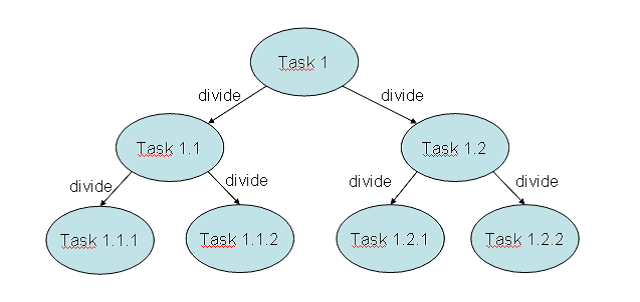
沒有固定的公式來決定問題的參考大小(Reference Size),從而決定一個任務是需要進行拆分或不需要拆分,拆分與否仍是依賴於任務本身的特性。可以使用在任務中將要處理的元素的數目和任務執行所需要的時間來決定參考大小。測試不同的參考大小來決定解決問題最好的一個方案,將ForkJoinPool類看作一個特殊的 Executor 執行器型別。這個框架基於以下兩種操作。
- 分解(Fork)操作:當需要將一個任務拆分成更小的多個任務時,在框架中執行這些任務;
- 合併(Join)操作:當一個主任務等待其建立的多個子任務的完成執行。
Fork/Join框架和執行器框架(Executor Framework)
為了達到這個目標,通過Fork/Join框架執行的任務有以下限制。
- 任務只能使用fork()和join() 操作當作同步機制。如果使用其他的同步機制,工作者執行緒就不能執行其他任務,當然這些任務是在同步操作裡時。比如,如果在Fork/Join 框架中將一個任務休眠,正在執行這個任務的工作者執行緒在休眠期內不能執行另一個任務。
- 任務不能執行I/O操作,比如檔案資料的讀取與寫入。
- 任務不能丟擲非執行時異常(Checked Exception),必須在程式碼中處理掉這些異常。
Fork/Join框架的核心是由下列兩個類組成的。
- ForkJoinPool:這個類實現了ExecutorService介面和工作竊取演算法(Work-Stealing Algorithm)。它管理工作者執行緒,並提供任務的狀態資訊,以及任務的執行資訊。
- ForkJoinTask:這個類是一個將在ForkJoinPool中執行的任務的基類。
Fork/Join框架提供了在一個任務裡執行fork()和join()操作的機制和控制任務狀態的方法。通常,為了實現Fork/Join任務,需要實現一個以下兩個類之一的子類。
- RecursiveAction:用於任務沒有返回結果的場景。
- RecursiveTask:用於任務有返回結果的場景。
本章接下來將展示如何利用Fork/Join框架高效地工作。
5.2 建立Fork/Join執行緒池
在本節,我們將學習如何使用Fork/Join框架的基本元素。它包括:
- 建立用來執行任務的ForkJoinPool物件;
- 建立即將線上程池中被執行的任務ForkJoinTask子類。
本範例中即將使用的Fork/Join框架的主要特性如下:
- 採用預設的構造器建立ForkJoinPool物件;
- 在任務中將使用JavaAPI文件推薦的結構。
if (problem size > default size){
tasks=divide(task);
execute(tasks);
} else {
resolve problem using another algorithm;
}
- 我們將以同步的方式執行任務。當一個主任務執行兩個或更多的子任務時,這個主任務將等待子任務的完成。用這種方法,執行主任務的執行緒,稱之為工作者執行緒(Worker Thread),它將尋找其他的子任務來執行,並在子任務執行的時間裡利用所有的執行緒優勢。
- 如果將要實現的任務沒有返回任何結果,那麼,採用RecursiveAction類作為實現任務的基類。
準備工作
本節的範例是在EclipseIDE裡完成的。無論你使用Eclipse還是其他的IDE(比如NetBeans),都可以開啟這個IDE並且建立一個新的Java工程。
範例實現
在本節,我們將實現一項更新產品價格的任務。最初的任務將負責更新列表中的所有元素。我們使用10來作為參考大小(ReferenceSize),如果一個任務需要更新大於10個元素,它會將這個列表分解成為兩部分,然後分別建立兩個任務用來更新各自部分的產品價格。
按照接下來的步驟實現本節的範例。
1.建立一個名為Product的類,用來儲存產品的名稱和價格。
public class Product {
2.宣告一個名為name的私有String屬性,一個名為price的私有double屬性。
private String name; private double price;
3.實現兩個屬性各自的設值與取值方法。
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
4.建立一個名為ProductListGenerator的類,用來生成一個隨機產品列表。
public class ProductListGenerator {
5.實現generate()方法。接收一個表示列表大小的int引數,並返回一個生成產品的List<Product>列表。
public List<Product> generate (int size) {
6.建立返回產品列表的物件ret。
List<Product> ret=new ArrayList<Product>();
7.生成產品列表,給所有的產品分配相同的價格,比如可以檢查程式是否執行良好的數字10。
for (int i=0; i<size; i++){
Product product=new Product();
product.setName("Product "+i);
product.setPrice(10);
ret.add(product);
}
return ret;
}
8.建立一個名為Task的類,並繼承RecursiveAction類。
public class Task extends RecursiveAction {
9.宣告這個類的serialVersionUID屬性。這個元素是必需的,因為RecursiveAction的父類ForkJoinTask實現了Serializable介面。
private static final long serialVersionUID = 1L;
10.宣告一個名為products私有的List<Product>屬性。
private List<Product> products;
11.宣告兩個私有的int屬性,分別命名為first和last。這兩個屬性將決定任務執行時對產品的分塊。
private int first; private int last;
12.宣告一個名為increment的私有double屬性,用來儲存產品價格的增加額。
private double increment;
13.實現類的構造器,用來初始化類的這些屬性。
public Task (List<Product> products, int first, int last, double
increment) {
this.products=products;
this.first=first;
this.last=last;
this.increment=increment;
}
14.實現compute()方法,實現任務的執行邏輯。
@Override
protected void compute() {
15.如果last和first屬性值的差異小於10(一個任務只能更新少於10件產品的價格),則呼叫updatePrices()方法增加這些產品的價格。
if (last-first<10) {
updatePrices();
16.如果last和first屬性值的差異大於或等於10,就建立兩個新的Task物件,一個處理前一半的產品,另一個處理後一半的產品,然後呼叫ForkJoinPool的invokeAll()方法來執行這兩個新的任務。
} else {
int middle=(last+first)/2;
System.out.printf("Task: Pending tasks:
%s\n",getQueuedTaskCount());
Task t1=new Task(products, first,middle+1, increment);
Task t2=new Task(products, middle+1,last, increment);
invokeAll(t1, t2);
}
17.實現updatePrices()方法。這個方法用來更新在產品列表中處於first和last屬性之間的產品。
private void updatePrices() {
for (int i=first; i<last; i++){
Product product=products.get(i);
product.setPrice(product.getPrice()*(1+increment));
}
}
18.實現範例的主類,建立Main主類,並實現main()方法。
public class Main {
public static void main(String[] args) {
19.使用ProductListGenerator類建立一個有10,000個產品的列表
ProductListGenerator generator=new ProductListGenerator(); List<Product> products=generator.generate(10000);
20.建立一個新的Task物件用來更新列表中的所有產品。引數first為0,引數last為產品列表的大小,即10,000。
Task task=new Task(products, 0, products.size(), 0.20);
21.通過無參的類構造器建立一個ForkJoinPool物件。
ForkJoinPool pool=new ForkJoinPool();
22.呼叫execute()方法執行任務。
pool.execute(task);
23.實現程式碼塊,顯示關於執行緒池演變的資訊,每5毫秒在控制檯上輸出執行緒池的一些引數值,直到任務執行結束。
do {
System.out.printf("Main: Thread Count: %d\n",pool.
getActiveThreadCount());
System.out.printf("Main: Thread Steal: %d\n",pool.
getStealCount());
System.out.printf("Main: Parallelism: %d\n",pool.
getParallelism());
try {
TimeUnit.MILLISECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
} while (!task.isDone());
24.呼叫shutdown()方法關閉執行緒池。
pool.shutdown();
25.呼叫isCompletedNormally()方法,檢查任務是否已經完成並且沒有錯誤,在這個示例中,在控制檯輸出資訊表示任務已經處理結束。
if (task.isCompletedNormally()){
System.out.printf("Main: The process has completed
normally.\n");
}
26.在增加之後,所有產品的期望價格是12元。在控制檯輸出所有產品的名稱和價格,如果產品的價格不是12元,就將產品資訊打印出來,以便確認所有的產品價格都正確地增加了。
for (int i=0; i<products.size(); i++){
Product product=products.get(i);
if (product.getPrice()!=12) {
System.out.printf("Product %s: %f\n",product.
getName(),product.getPrice());
}
}
27.在控制檯輸出資訊表示程式執行結束。
System.out.println("Main: End of the program.\n");
<b> </b>
工作原理
在這個範例中,我們建立了ForkJoinPool物件,和一個將線上程池中執行的ForkJoinTask的子類。使用了無參的類構造器建立了ForkJoinPool物件,因此它將執行預設的配置。建立一個執行緒數等於計算機CPU數目的執行緒池,建立好ForkJoinPool物件之後,那些執行緒也建立就緒了,線上程池中等待任務的到達,然後開始執行。
由於Task類繼承了RecursiveAction類,因此不返回結果。在本節,我們使用了推薦的結構來實現任務。如果任務需要更新大於10個產品,它將拆分這些元素為兩部分,建立兩個任務,並將拆分的部分相應地分配給新建立的任務。通過使用Task類的first和last屬性,來獲知任務將要更新的產品列表所在的位置範圍。我們已經使用first和last屬性,來操作產品列表中僅有的一份副本,而沒有為每一個任務去建立不同的產品列表。
呼叫invokeAll()方法來執行一個主任務所建立的多個子任務。這是一個同步呼叫,這個任務將等待子任務完成,然後繼續執行(也可能是結束)。當一個主任務等待它的子任務時,執行這個主任務的工作者執行緒接收另一個等待執行的任務並開始執行。正因為有了這個行為,所以說Fork/Join框架提供了一種比Runnable和Callable物件更加高效的任務管理機制。
ForkJoinTask類的invokeAll()方法是執行器框架(ExecutorFramework)和Fork/Join框架之間的主要差異之一。在執行器框架中,所有的任務必須傳送給執行器,然而,在這個示例中,執行緒池中包含了待執行方法的任務,任務的控制也是線上程池中進行的。我們在Task類中使用了invokeAll()方法,Task類繼承了RecursiveAction類,而RecursiveAction類則繼承了ForkJoinTask類。
我們已經發送一個唯一的任務到執行緒池中,通過使用execute()方法來更新所有產品的列表。在這個示例中,它是一個同步呼叫,主執行緒一直等待呼叫的執行。
我們已經使用了ForkJoinPool類的一些方法,來檢查正在執行的任務的狀態和演變情況。這個類包含更多的方法,可以用於任務狀態的檢測。參見8.5節介紹的這些方法的完整列表。
最後,像執行器框架一樣,必須呼叫shutdown()方法來結束ForkJoinPool的執行。
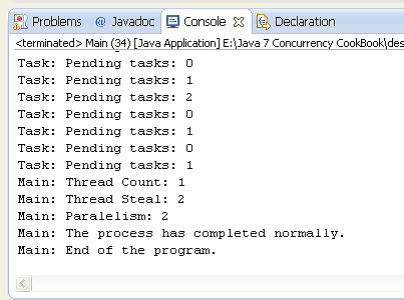
下面的截圖展示了這個範例執行的部分結果。
可以看到,任務執行結束,並且產品的價格已經更新了。
更多資訊
ForkJoinPool類還提供了以下方法用於執行任務。
- execute (Runnabletask):這是本範例中使用的execute()方法的另一種版本。這個方法傳送一個Runnable任務給ForkJoinPool類。需要注意的是,使用Runnable物件時ForkJoinPool類就不採用工作竊取演算法(Work-StealingAlgorithm),ForkJoinPool類僅在使用ForkJoinTask類時才採用工作竊取演算法。
- invoke(ForkJoinTask<T>task):正如範例所示,ForkJoinPool類的execute()方法是非同步呼叫的,而ForkJoinPool類的invoke()方法則是同步呼叫的。這個方法直到傳遞進來的任務執行結束後才會返回。
- 也可以使用在ExecutorService類中宣告的invokeAll()和invokeAny()方法,這些方法接收Callable物件作為引數。使用Callable物件時ForkJoinPool類就不採用工作竊取演算法(Work-StealingAlgorithm),因此,最好使用執行器來執行Callable物件。
ForkJoinTask類也包含了在範例中所使用的invokeAll()方法的其他版本,這些版本如下。
- invokeAll(ForkJoinTask<?>… tasks):這個版本的方法接收一個可變的引數列表,可以傳遞儘可能多的ForkJoinTask物件給這個方法作為引數。
- invokeAll(Collection<T>tasks):這個版本的方法接受一個泛型型別T的物件集合(比如,ArrayList物件、LinkedList物件或者TreeSet物件)。這個泛型型別T必須是ForkJoinTask類或者它的子類。
雖然ForkJoinPool類是設計用來執行ForkJoinTask物件的,但也可以直接用來執行Runnable和Callable物件。當然,也可以使用ForkJoinTask類的adapt()方法來接收一個Callable物件或者一個Runnable物件,然後將之轉化為一個ForkJoinTask物件,然後再去執行。
參見
- 參見8.5節。
5.3 合併任務的結果
Fork/Join框架提供了執行任務並返回結果的能力。這些型別的任務都是通過RecursiveTask類來實現的。RecursiveTask類繼承了ForkJoinTask類,並且實現了由執行器框架(Executor Framework)提供的Future介面。
在任務中,必須使用Java API文件推薦的如下結構:
if (problem size > size){
tasks=Divide(task);
execute(tasks);
groupResults()
return result;
} else {
resolve problem;
return result;
}
如果任務需要解決的問題大於預先定義的大小,那麼就要將這個問題拆分成多個子任務,並使用Fork/Join框架來執行這些子任務。執行完成後,原始任務獲取到由所有這些子任務產生的結果,合併這些結果,返回最終的結果。當原始任務線上程池中執行結束後,將高效地獲取到整個問題的最終結果。
在本節,我們將學習如何使用Fork/Join框架來解決這種問題,開發一個應用程式,在文件中查詢一個詞。我們將實現以下兩種任務:
- 一個文件任務,它將遍歷文件中的每一行來查詢這個詞;
- 一個行任務,它將在文件的一部分當中查詢這個詞。
所有這些任務將返回文件或行中所出現這個詞的次數。
準備工作
本節的範例是在EclipseIDE裡完成的。無論你使用Eclipse還是其他的IDE(比如NetBeans),都可以開啟這個IDE並且建立一個新的Java工程。
範例實現
按照接下來的步驟實現本節的範例。
1.建立一個名為DocumentMock的類。它將生成一個字串矩陣來模擬一個文件。
public class Document {
2.用一些詞來建立一個字串陣列。這個陣列將被用來生成字串矩陣。
private String words[]={"the","hello","goodbye","packt", "java","t
hread","pool","random","class","main"};
3.實現generateDocument()方法。它接收3個引數,分別是行數numLines,每一行詞的個數numWords,和準備查詢的詞word。然後返回一個字串矩陣。
public String[][] generateDocument(int numLines, int numWords,
String word){
4.建立用來生成文件所需要的物件:String矩陣,和用來生成隨機數的Random物件。
int counter=0; String document[][]=new String[numLines][numWords]; Random random=new Random();
5.為字串矩陣填上字串。通過隨機數取得陣列words中的某一字串,然後存入到字串矩陣document對應的位置上,同時計算生成的字串矩陣中將要查詢的詞出現的次數。這個值可以用來與後續程式執行查詢任務時統計的次數相比較,檢查兩個值是否相同。
for (int i=0; i<numLines; i++){
for (int j=0; j<numWords; j++) {
int index=random.nextInt(words.length);
document[i][j]=words[index];
if (document[i][j].equals(word)){
counter++;
}
}
}
6.在控制檯輸出這個詞出現的次數,並返回生成的矩陣document。
System.out.println("DocumentMock: The word appears "+
counter+" times in the document");
return document;
7.建立名為DocumentTask的類,並繼承RecursiveTask類,RecursiveTask類的泛型引數為Integer型別。這個DocumentTask類將實現一個任務,用來計算所要查詢的詞在行中出現的次數。
public class DocumentTask extends RecursiveTask<Integer> {
8.宣告一個名為document的私有String矩陣,以及兩個名為start和end的私有int屬性,並宣告一個名為word的私有String屬性。
private String document[][]; private int start, end; private String word;
9.實現類的構造器,用來初始化類的所有屬性。
public DocumentTask (String document[][], int start, int end,
String word){
this.document=document;
this.start=start;
this.end=end;
this.word=word;
}
10.實現compute()方法。如果end和start的差異小於10,則呼叫processLines()方法,來計算這兩個位置之間要查詢的詞出現的次數。
@Override
protected Integer compute() {
int result;
if (end-start<10){
result=processLines(document, start, end, word);
11.否則,拆分這些行成為兩個物件,並建立兩個新的DocumentTask物件來處理這兩個物件,然後呼叫invokeAll()方法線上程池裡執行它們。
} else {
int mid=(start+end)/2;
DocumentTask task1=new DocumentTask(document,start,mid,wo
rd);
DocumentTask task2=new DocumentTask(document,mid,end,word);
invokeAll(task1,task2);
12.採用groupResults()方法將這兩個任務返回的值相加。最後,返回任務計算的結果。
try {
result=groupResults(task1.get(),task2.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
return result;
13.實現processLines()方法。接收4個引數,一個字串document矩陣,start屬性,end屬性和任務將要查詢的詞word的屬性。
private Integer processLines(String[][] document, int start, int
end,String word) {
14.為任務所要處理的每一行,建立一個LineTask物件,然後儲存在任務列表裡。
List<LineTask> tasks=new ArrayList<LineTask>();
for (int i=start; i<end; i++){
LineTask task=new LineTask(document[i], 0, document[i].
length, word);
tasks.add(task);
}
15.呼叫invokeAll()方法執行列表中所有的任務。
invokeAll(tasks);
16.合計這些任務返回的值,並返回結果。
int result=0;
for (int i=0; i<tasks.size(); i++) {
LineTask task=tasks.get(i);
try {
result=result+task.get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
return new Integer(result);
17.實現groupResults()方法。它將兩個數字相加並返回結果。
private Integer groupResults(Integer number1, Integer number2) {
Integer result;
result=number1+number2;
return result;
}
18.建立名為LineTask的類,並繼承RecursiveTask類,RecursiveTask類的泛型引數為Integer型別。這個RecursiveTask類實現了一個任務,用來計算所要查詢的詞在一行中出現的次數。
public class LineTask extends RecursiveTask<Integer>{
19.宣告類的serialVersionUID屬性。這個元素是必需的,因為RecursiveTask的父類ForkJoinTask實現了Serializable介面。宣告一個名為line的私有String陣列屬性和兩個名為start和end的私有int屬性。最後,宣告一個名為word的私有String屬性。
private static final long serialVersionUID = 1L; private String line[]; private int start, end; private String word;
20.實現類的構造器,用來初始化它的屬性。
public LineTask(String line[], int start, int end, String word)
{
this.line=line;
this.start=start;
this.end=end;
this.word=word;
}
21.實現compute()方法。如果end和start屬性的差異小於100,那麼任務將採用count()方法,在由start與end屬性所決定的行的片斷中查詢詞。
@Override
protected Integer compute() {
Integer result=null;
if (end-start<100) {
result=count(line, start, end, word);
22.如果end和start屬性的差異不小於100,將這一組詞拆分成兩組,然後建立兩個新的LineTask物件來處理這兩個組,呼叫invokeAll()方法線上程池中執行它們。
} else {
int mid=(start+end)/2;
LineTask task1=new LineTask(line, start, mid, word);
LineTask task2=new LineTask(line, mid, end, word);
invokeAll(task1, task2);
23.呼叫groupResults()方法將兩個任務返回的值相加。最後返回任務計算的結果。
try {
result=groupResults(task1.get(),task2.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
return result;
24.實現count()方法。它接收4個引數,一個完整行字串line陣列,start屬性,end屬性和任務將要查詢的詞word的屬性。
private Integer count(String[] line, int start, int end, String
word) {
25.將儲存在start和end屬性值之間的詞與任務正在查詢的word屬性相比較。如果相同,那麼將計數器counter變數加1。
int counter;
counter=0;
for (int i=start; i<end; i++){
if (line[i].equals(word)){
counter++;
}
}
26.為了延緩範例的執行,將任務休眠10毫秒。
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
27.返回計數器counter變數的值。
return counter;
28.實現groupResults()方法。計算兩個數字之和並返回結果。.
private Integer groupResults(Integer number1, Integer number2) {
Integer result;
result=number1+number2;
return result;
}
29.實現範例的主類,建立Main主類,並實現main()方法。
public class Main{
public static void main(String[] args) {
30.建立Document物件,包含100行,每行1,000個詞。
DocumentMock mock=new DocumentMock(); String[][] document=mock.generateDocument(100, 1000, "the");
31.建立一個DocumentTask物件,用來更新整個文件。傳遞數字0給引數start,以及數字100給引數end。
DocumentTask task=new DocumentTask(document, 0, 100, "the");
32.採用無參的構造器建立一個ForkJoinPool物件,然後呼叫execute()方法線上程池裡執行這個任務。
ForkJoinPool pool=new ForkJoinPool(); pool.execute(task);
33.實現程式碼塊,顯示執行緒池的進展資訊,每秒鐘在控制檯輸出執行緒池的一些引數,直到任務執行結束。
do {
System.out.printf("*****************************************
*\n");
System.out.printf("Main: Parallelism: %d\n",pool.
getParallelism());
System.out.printf("Main: Active Threads: %d\n",pool.
getActiveThreadCount());
System.out.printf("Main: Task Count: %d\n",pool.
getQueuedTaskCount());
System.out.printf("Main: Steal Count: %d\n",pool.
getStealCount());
System.out.printf("*****************************************
*\n");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
} while (!task.isDone());
34.呼叫shutdown()方法關閉執行緒池。
pool.shutdown();
35.呼叫awaitTermination()等待任務執行結束。
try {
pool.awaitTermination(1, TimeUnit.DAYS);
} catch (InterruptedException e) {
e.printStackTrace();
}
36.在控制檯輸出文件中出現要查詢的詞的次數。檢驗這個數字與DocumentMock類輸出的數字是否一致。
try {
System.out.printf("Main: The word appears %d in the
document",task.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
工作原理
在這個範例中,我們實現了兩個不同的任務。
- DocumentTask類:這個類的任務需要處理由start和end屬性決定的文件行。如果這些行數小於10,那麼,就每行建立一個LineTask物件,然後在任務執行結束後,合計返回的結果,並返回總數。如果任務要處理的行數大於10,那麼,將任務拆分成兩組,並建立兩個DocumentTask物件來處理這兩組物件。當這些任務執行結束後,同樣合計返回的結果,並返回總數。
- LineTask類:這個類的任務需要處理文件中一行的某一組詞。如果一組詞的個數小100,那麼任務將直接在這一組詞裡搜尋特定詞,然後返回查詢詞在這一組詞中出現的次數。否則,任務將拆分這些詞為兩組,並建立兩個LineTask物件來處理這兩組詞。當這些任務執行完成後,合計返回的結果,並返回總數。
在Main主類中,我們通過預設的構造器建立了ForkJoinPool物件,然後執行DocumentTask類,來處理一個共有100行,每行1,000字的文件。這個任務將問題拆分成DocumentTask物件和LineTask物件,然後當所有的任務執行完成後,使用原始的任務來獲取整個文件中所要查詢的詞出現的次數。由於任務繼承了RecursiveTask類,因此能夠返回結果。
呼叫get()方法來獲得Task返回的結果。這個方法宣告在Future接口裡,並由RecursiveTask類實現。
執行程式時,在控制檯上,我們可以比較第一行與最後一行的輸出資訊。第一行是文件生成時被查詢的詞出現的次數,最後一行則是通過Fork/Join任務計算而來的被查詢的詞出現的次數,而且這兩個數字相同。
更多資訊
ForkJoinTask類提供了另一個complete()方法來結束任務的執行並返回結果。這個方法接收一個物件,物件的型別就是RecursiveTask類的泛型引數,然後在任務呼叫join()方法後返回這個物件作為結果。這一過程採用了推薦的非同步任務來返回任務的結果。
由於RecursiveTask類實現了Future介面,因此還有get()方法呼叫的其他版本:
- get(long timeout, TimeUnit unit):這個版本中,如果任務的結果未準備好,將等待指定的時間。如果等待時間超出,而結果仍未準備好,那方法就會返回null值。
TimeUnit是一個列舉類,有如下的常量:DAYS、HOURS、MICROSECONDS、MILLISECONDS、MINUTES、NANOSECONDS和SECONDS。
參見
- 參見5.2節。
- 參見8.5節。
5.4 非同步執行任務
在ForkJoinPool中執行 ForkJoinTask時,可以採用同步或非同步方式。當採用同步方式執行時,傳送任務給Fork/Join執行緒池的方法直到任務執行完成後才會返回結果。而採用非同步方式執行時,傳送任務給執行器的方法將立即返回結果,但是任務仍能夠繼續執行。
需要明白這兩種方式在執行任務時的一個很大的區別。當採用同步方式,呼叫這些方法(比如,invokeAll()方法)時,任務被掛起,直到任務被髮送到Fork/Join執行緒池中執行完成。這種方式允許ForkJoinPool類採用工作竊取演算法(Work-StealingAlgorithm)來分配一個新任務給在執行休眠任務的工作者執行緒(WorkerThread)。相反,當採用非同步方法(比如,fork()方法)時,任務將繼續執行,因此ForkJoinPool類無法使用工作竊取演算法來提升應用程式的效能。在這個示例中,只有呼叫join()或get()方法來等待任務的結束時,ForkJoinPool類才可以使用工作竊取演算法。
本節將學習如何使用ForkJoinPool和ForkJoinTask類所提供的非同步方法來管理任務。我們將實現一個程式:在一個資料夾及其子資料夾中來搜尋帶有指定副檔名的檔案。ForkJoinTask類將實現處理這個資料夾的內容。而對於這個資料夾中的每一個子檔案,任務將以非同步的方式傳送一個新的任務給ForkJoinPool類。對於每個資料夾中的檔案,任務將檢查任務檔案的副檔名,如果符合條件就將其增加到結果列表中。
準備工作
本節的範例是在EclipseIDE裡完成的。無論你使用Eclipse還是其他的IDE(比如NetBeans),都可以開啟這個IDE並且建立一個新的Java工程。
範例實現
按照接下來的步驟實現本節的範例。
1.建立名為FolderProcessor的類,並繼承RecursiveTask類,RecursiveTask類的泛型引數為List<String>型別。
public class FolderProcessor extends RecursiveTask<List<String>> {
2.宣告類的serialVersionUID屬性。這個元素是必需的,因為RecursiveTask類的父類ForkJoinTask實現了Serializable介面。
private static final long serialVersionUID = 1L;
3.宣告一個名為path的私有String屬性,用來儲存任務將要處理的資料夾的完整路徑。
private String path;
4.宣告一個名為extension的私有String屬性,用來儲存任務將要查詢的檔案的副檔名。
private String extension;
5.實現類的構造器,用來初始化這些屬性。
public FolderProcessor (String path, String extension) {
this.path=path;
this.extension=extension;
}
6.實現compute()方法。既然指定了RecursiveTask類泛型引數為List<String>型別,那麼,這個方法必須返回一個同樣型別的物件。
@Override
protected List<String> compute() {
7.宣告一個名為list的String物件列表,用來儲存資料夾中檔案的名稱。
List<String> list=new ArrayList<>();
8.宣告一個名為tasks的FolderProcessor任務列表,用來儲存子任務,這些子任務將處理資料夾中的子資料夾。
List<FolderProcessor> tasks=new ArrayList<>();
9.獲取資料夾的內容。
File file=new File(path); File content[] = file.listFiles();
10.對於資料夾中的每一個元素,如果它是子資料夾,就建立一個新的FolderProcessor物件,然後呼叫fork()方法採用非同步方式來執行它。
if (content != null) {
for (int i = 0; i < content.length; i++) {
if (content[i].isDirectory()) {
FolderProcessor task=new FolderProcessor(content[i].
getAbsolutePath(), extension);
task.fork();
tasks.add(task);
11.否則,呼叫checkFile()方法來比較檔案的副檔名。如果檔案的副檔名與將要搜尋的副檔名相同,就將檔案的完整路徑儲存到第7步宣告的列表中。
} else {
if (checkFile(content[i].getName())){
list.add(content[i].getAbsolutePath());
}
}
}
12.如果FolderProcessor子任務列表超過50個元素,那麼就在控制檯輸出一條資訊表示這種情景。
if (tasks.size()>50) {
System.out.printf("%s: %d tasks ran.\n",file.
getAbsolutePath(),tasks.size());
}
13.呼叫addResultsFromTask()輔助方法。它把通過這個任務而啟動的子任務返回的結果增加到檔案列表中。傳遞兩個引數給這個方法,一個是字串列表list,一個是FolderProcessor子任務列表tasks。
addResultsFromTasks(list,tasks);
14.返回字串列表。
return list;
15.實現addResultsFromTasks()方法。遍歷任務列表中儲存的每一個任務,呼叫join()方法等待任務執行結束,並且返回任務的結果。然後,呼叫addAll()方法將任務的結果增加到字串列表中。
private void addResultsFromTasks(List<String> list,
List<FolderProcessor> tasks) {
for (FolderProcessor item: tasks) {
list.addAll(item.join());
}
}
16.實現checkFile()方法。這個方法檢查作為引數而傳遞進來的檔名,如果是以正在搜尋的副檔名為結尾,那麼方法就返回true,否則就返回false。
private boolean checkFile(String name) {
return name.endsWith(extension);
}
17.實現範例的主類,建立Main主類,並實現main()方法。
public class Main {
public static void main(String[] args) {
18.通過預設的構造器建立ForkJoinPool執行緒池。
ForkJoinPool pool=new ForkJoinPool();
19.建立3個FolderProcessor任務,並使用不同的資料夾路徑來初始化這些任務。
FolderProcessor system=new FolderProcessor("C:\\Windows",
"log");
FolderProcessor apps=new
FolderProcessor("C:\\Program Files","log");
FolderProcessor documents=new FolderProcessor("C:\\Documents
And Settings","log");
20.呼叫execute()方法執行執行緒池裡的3個任務。
pool.execute(system); pool.execute(apps); pool.execute(documents);
21.在控制檯上每隔1秒鐘輸出執行緒池的狀態資訊,直到這3個任務執行結束。
do {
System.out.printf("*****************************************
*\n");
System.out.printf("Main: Parallelism: %d\n",pool.
getParallelism());
System.out.printf("Main: Active Threads: %d\n",pool.
getActiveThreadCount());
System.out.printf("Main: Task Count: %d\n",pool.
getQueuedTaskCount());
System.out.printf("Main: Steal Count: %d\n",pool.
getStealCount());
System.out.printf("*****************************************
*\n");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
} while ((!system.isDone())||(!apps.isDone())||(!documents.
isDone()));
22.呼叫shutdown()方法關閉ForkJoinPool執行緒池。
pool.shutdown();
23.在控制檯輸出每一個任務產生的結果的大小。
List<String> results;
results=system.join();
System.out.printf("System: %d files found.\n",results.size());
results=apps.join();
System.out.printf("Apps: %d files found.\n",results.size());
results=documents.join();
System.out.printf("Documents: %d files found.\n",results.
size());
工作原理
下面的截圖顯示了範例的部分執行結果。
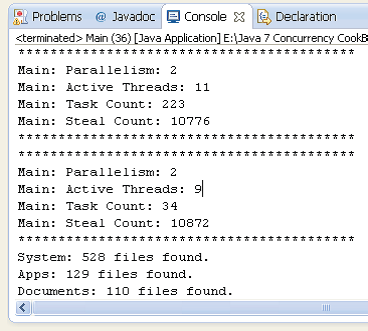
這個範例的重點在於FolderProcessor類。每一個任務處理一個資料夾中的內容。資料夾中的內容有以下兩種型別的元素:
- 檔案;
- 其他資料夾。
如果主任務發現一個資料夾,它將建立另一個Task物件來處理這個資料夾,呼叫fork()方法把這個新物件傳送到執行緒池中。fork()方法傳送任務到執行緒池時,如果執行緒池中有空閒的工作者執行緒(WorkerThread)或者將建立一個新的執行緒,那麼開始執行這個任務,fork()方法會立即返回,因此,主任務可以繼續處理資料夾裡的其他內容。對於每一個檔案,任務開始比較它的副檔名,如果與要搜尋的副檔名相同,那麼將檔案的完整路徑增加到結果列表中。
一旦主任務處理完指定資料夾裡的所有內容,它將呼叫join()方法等待發送到執行緒池中的所有子任務執行完成。join()方法在主任務中被呼叫,然後等待任務執行結束,並通過compute()方法返回值。主任務將所有的子任務結果進行合併,這些子任務傳送到執行緒池中時帶有自己的結果列表,然後通過呼叫compute()方法返回這個列表並作為主任務的返回值。
ForkJoinPool類也允許以非同步的方式執行任務。呼叫execute()方法傳送3個初始任務到執行緒池中。在Main主類中,呼叫shutdown()方法結束執行緒池,並在控制檯輸出執行緒池中任務的狀態及其變化的過程。ForkJoinPool類包含了多個方法可以實現這個目的。參考8.5節來查閱這些方法的詳細列表。
更多資訊
本範例使用join()方法來等待任務的結束,然後獲取它們的結果。也可以使用get()方法以下的兩個版本來完成這個目的。
- get():如果ForkJoinTask類執行結束,或者一直等到結束,那麼get()方法的這個版本則返回由compute()方法返回的結果。
- get(long timeout, TimeUnit unit):如果任務的結果未準備好,那麼get()方法的 這個版本將等待指定的時間。如果超過指定的時間了,任務的結果仍未準備好,那麼這 個方法將返回 null值。TimeUnit是一個列舉類,有如下的常量:DAYS、HOURS、MICROSECONDS、MILLISECONDS、MINUTES、NANOSECONDS和SECONDS。
get()方法和join()方法還存在兩個主要的區別:
- join()方法不能被中斷,如果中斷呼叫join()方法的執行緒,方法將丟擲InterruptedException異常;
- 如果任務丟擲任何執行時異常,那麼 get()方法將返回ExecutionException異常,但是join()方法將返回RuntimeException異常。
參見
- 參考5.2節。
- 參考8.5節。
5.5 在任務中丟擲異常
Java有兩種型別的異常。
- 非執行時異常(Checked Exception):這些異常必須在方法上通過throws子句丟擲,或者在方法體內通過try{…}catch{…}方式進行捕捉處理。比如IOException或ClassNotFoundException異常。
- 執行時異常(Unchecked Exception):這些異常不需要在方法上通過throws子句丟擲,也不需要在方法體內通過try{…}catch{…}方式進行捕捉處理。比如NumberFormatException異常。
不能在ForkJoinTask類的compute()方法中丟擲任務非執行時異常,因為這個方法的實現沒有包含任何throws宣告。因此,需要包含必需的程式碼來處理相關的異常。另一方面,compute()方法可以丟擲執行時異常(它可以是任何方法或者方法內的物件丟擲的異常)。ForkJoinTask類和ForkJoinPool類的行為與我們期待的可能不同。在控制檯上,程式沒有結束執行,不能看到任務異常資訊。如果異常不被丟擲,那麼它只是簡單地將異常吞噬掉。然而,我們能夠利用ForkJoinTask類的一些方法來獲知任務是否有異常丟擲,以及丟擲哪一種型別的異常。在本節,我們將學習如何獲取這些異常資訊。
準備工作
本節的範例是在Eclipse IDE裡完成的。無論你使用Eclipse還是其他的IDE(比如NetBeans),都可以開啟這個IDE並且建立一個新的Java工程。
範例實現
按照接下來的步驟實現本節的範例。
1.建立名為Task的類,並繼承RecursiveTask類,RecursiveTask類的泛型引數為Integer 型別。
public class Task extends RecursiveTask<Integer> {
2.宣告一個名為array的私有int陣列。用來模擬在這個範例中即將處理的資料陣列。
private int array[];
3.宣告兩個分別名為start和end的私有int屬性。這些屬性將決定任務要處理的陣列元素。
private int start, end;
4.實現類的構造器,用來初始化類的屬性。
public Task(int array[], int start, int end){
this.array=array;
this.start=start;
this.end=end;
}
5.實現任務的compute()方法。由於指定了Integer型別作為RecursiveTask的泛型型別,因此這個方法必須返回一個Integer物件。在控制檯輸出start和end屬性。
@Override
protected Integer compute() {
System.out.printf("Task: Start from %d to %d\n",start,end);
6.如果由start和end屬性所決定的元素塊規模小於10,那麼直接檢查元素,當碰到元素塊的第4個元素(索引位為3)時,就丟擲RuntimeException異常。然後將任務休眠1秒鐘。
if (end-start<10) {
if ((3>start)&&(3<end)){
throw new RuntimeException("This task throws an"+
"Exception: Task from "+start+" to "+end);
}
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
7.如果要處理的元素塊規模大於或等於10,就拆分這個元素塊為兩部分,並建立 兩個Task物件來處理這兩部分,然後呼叫invokeAll()方法線上程池中執行這兩個Task物件。
} else {
int mid=(end+start)/2;
Task task1=new Task(array,start,mid);
Task task2=new Task(array,mid,end);
invokeAll(task1, task2);
}
8.在控制檯輸出資訊,表示任務結束,並輸出start和end屬性值。
System.out.printf("Task: End form %d to %d\n",start,end);
9.返回數字0作為任務的結果。
return 0;
10.實現範例的主類,建立Main主類,並實現main()方法。
public class Main {
public static void main(String[] args) {
11.建立一個名為array並能容納100個整數的int陣列。
int array[]=new int[100];
12.建立一個Task物件來處理這個陣列。
Task task=new Task(array,0,100);
13.通過預設的構造器建立ForkJoinPool物件。
ForkJoinPool pool=new ForkJoinPool();
14.呼叫execute()方法線上程池中執行任務。
pool.execute(task);
15.呼叫shutdown()方法關閉執行緒池。
pool.shutdown();
16. 呼叫awaitTermination()方法等待任務執行結束。如果想一直等待到任務執行完成,那就傳遞值1和TimeUnit.DAYS作為引數給這個方法。
try {
pool.awaitTermination(1, TimeUnit.DAYS);
} catch (InterruptedException e) {
e.printStackTrace();
}
17. 呼叫isCompletedAbnormally()方法來檢查主任務或者它的子任務之一是否丟擲了異常。在這個示例中,在控制檯輸出資訊就表示有異常丟擲。呼叫ForkJoinTask類的getException()方法來獲取異常資訊。
if (task.isCompletedAbnormally()) {
System.out.printf("Main: An exception has ocurred\n");
System.out.printf("Main: %s\n",task.getException());
}
System.out.printf("Main: Result: %d",task.join());
工作原理
在本節,我們實現的Task類用來處理一個數字陣列。它檢查要處理的數字塊規模是否包含有10個或更多個元素。在這個情況下,Task類拆分這個數字塊為兩部分,然後建立兩個新的Task物件用來處理這兩部分。否則,它將尋找位於陣列中第4個位置(索引位為3)的元素。如果這個元素位於任務處理塊中,它將丟擲一個RuntimeException異常。
雖然執行這個程式時將丟擲異常,但是程式不會停止。在Main主類中,呼叫原始任務ForkJoinTask類的isCompletedAbnormally()方法,如果主任務或者它的子任務之一丟擲了異常,這個方法將返回true。也可以使用getException()方法來獲得丟擲的Exception物件。
當任務丟擲執行時異常時,會影響它的父任務(傳送到ForkJoinPool類的任務),以及父任務的父任務,以此類推。查閱程式的輸出結果,將會發現有一些任務沒有結束的資訊。那些任務的開始資訊如下:
Task: Starting form 0 to 100 Task: Starting form 0 to 50 Task: Starting form 0 to 25 Task: Starting form 0 to 12 Task: Starting form 0 to 6
這些任務是那些丟擲異常的任務和它的父任務。所有這些任務都是異常結束的。記住一點:在用ForkJoinPool物件和ForkJoinTask物件開發一個程式時,它們是會丟擲異常的,如果不想要這種行為,就得采用其他方式。
下面的截圖展示了這個範例執行的部分結果。
感謝人民郵電大學授權併發網釋出此書樣章,新書已上市,購買請進噹噹網
本章內容包含:
建立Fork/Join執行緒池
合併任務的結果
非同步執行任務
在任務中丟擲異常
取消任務
5.1 簡介
通常,使用Java來開發一個簡單的併發應用程式時,會建立一些Runnable物件,然後建立對應的Th
由人民郵電出版社出版的《Java 7併發程式設計實戰手冊》終於出版了,譯者是俞黎敏和申紹勇,該書將於近期上架。之前併發程式設計網組織翻譯過此書,由於郵電出版社在併發網聯絡他們之前就找到了譯者,所以沒有采用併發網的譯稿,但郵電出版社將於併發網展開合作,釋出該書的樣章(樣章由併發網挑選,你也可以
感謝人民郵電大學授權併發網釋出此書樣章,新書購買傳送門=》噹噹網
本章將介紹下列內容:
建立執行緒執行器
建立固定大小的執行緒執行器
在執行器中執行任務並返回結果
執行多個任務並處理第一個結果
執行多個任務並處理所有結果
在執行器中延時執行任務
在執行器中週期性執行任務
在執行器中取消任務
synchronized的兩個作用:原子性和記憶體可見性。
在沒有同步的情況下,編譯器、處理器以及執行時等都可能對操作的執行順序進行一些意想不到的調整(重排序)。
失效資料
非原子的64位操作
加鎖的含義不僅僅侷限於互斥行為,還包括記憶體可見性,為了確保所有
1.編寫一個程式,查詢指定域名為www.taobao.com的所以可能的ip地址。public class Tb {
public static void main(String[] args) {
try {
In
1.編寫一個程式,查詢指定域名為www.taobao.com的所有可能地址。import java.io.IOException;
import java.net.InetAddress;
import java.net.Socket;
public class TestT blank sortedset 方法 width lists 讀書 run 生產者消費者模式 ear
一、同步容器類
1. 同步容器類的問題
線程容器類都是線程安全的。可是當在其上進行符合操作則須要而外加鎖保護其安全性。
常見符合操作包括:
. 叠代
. 跳轉(
一個系統中的執行緒相對於其所要處理的任務而言,是一種非常有限的資源。執行緒不僅在執行任務時需要消耗CPU時間和記憶體等資源,執行緒物件(Thread例項)本身以及執行緒所需的呼叫棧(Call Stack)也佔用記憶體,並且Java中建立一個執行緒往往意味著JVM會建立相應的依賴於宿主機作業系
Active Object模式是一種非同步程式設計模式。(跟Promise模式有什麼區別呢?) 通過對方法的呼叫與方法的執行進行解耦來提高併發性。
類圖
當Active Object模式對外暴露的非同步方法被呼叫時,與該方法呼叫相關的上下文資訊,包括被呼叫的非同步方法名、引數等,會被
Producer-Consumer模式的核心是通過通道對資料(或任務)的生產者和消費者進行解耦,從而使二者的處理速率相對來說互不影響。
類圖
BlockingQueueChannel:
當佇列滿時,將當前執行緒掛起直到佇列非滿
當佇列為空時,將當前執行緒掛起直到佇列
Promise模式是一種非同步程式設計模式。 開始一個任務的執行,並得到一個用於獲取該任務執行結果的憑據物件,而不必等待該任務執行完畢就可以繼續執行其他操作。 等到需要該任務的執行結果時,再呼叫憑據物件的相關方法來獲取。
類圖
獲取執行結果時,可能由於非同步任務尚未執行完畢而阻塞。
Two-phase Termination模式通過將停止執行緒分解為準備階段和執行階段兩個階段,提供了一種通用的優雅停止執行緒的方法。 準備階段:通知目標執行緒準備進行停止。
設定標誌變數。
呼叫目標執行緒的interrupt方法。
對於能夠對interrupt方法呼
一個執行緒等待另一個執行緒完成一定的操作,才能繼續執行。 核心思想是如果某個執行緒執行特定的操作前需要滿足一定的條件,則在該條件未滿足時將該執行緒暫停執行(waiting)。
類圖
如果頻繁出現保護方法被呼叫時保護條件不成立,那麼保護方法的執行執行緒就會頻繁地被暫掛和喚醒,而導致頻繁
通過使用對外可見的狀態不可變的物件,無需額外的同步訪問控制。既保證了資料一致性,又避免了同步訪問控制所產生的額外開銷和問題,也簡化了程式設計。 狀態不可變的物件:物件一經建立,其對外可見的狀態就保持不變,如String和Integer。 Immutable Object模式:將現實世界中狀態
設計模式與三十六計
多執行緒設計模式簡介
不使用鎖的情況下保證執行緒安全
Immutable Object(不可變物件)模式
Thread Specific Storage(執行緒特有儲存)模式
Serial Thread Confinement(序列執行緒封
Java執行緒:
守護執行緒——不影響JVM的正常停止,常用於執行一些重要性不太高的任務
使用者執行緒——
建立一個Thread例項與建立其他類例項的區別: JVM為Thread例項分配兩個呼叫棧所需的儲存空間:
跟蹤Java程式碼間的呼叫關係
Thread Specific Storage模式:不共享變數,不使用鎖。 不同執行緒使用統一的訪問接入點可以獲取執行緒特有的例項。
弊端:
隱藏了系統結構,隱藏了應用中各個物件之間的關係,從而使應用更加難於理解。
鼓勵使用全域性物件。
常見使用場景
原文連結 作者: Javier Fernández González 譯者:鄭玉婷,許巧輝 校對:方騰飛,歐振聰
申明:本書由併發程式設計網組織翻譯,只供研究和學習之用,禁止任何人用於商業用途。
當你用計算機工作的時候,你在同時做多樣事情。你可以邊聽音樂邊寫文件邊讀取郵件。可以這樣做的
文章作者:郝林(《Go併發程式設計實戰 (第2版)》作者)
終於來了!經過出版社的各位編輯、校對、排版夥伴與我的N輪PK和共同努力,《Go併發程式設計實戰》第2版的所有內容終於完全確定,並於2017年3月24日交付印刷!當然,印刷也經歷了若干流程,以儘量把出錯
1 怎麼理解發布和逸出?
轉自別人的回答講的很詳細
點選這裡
還有這裡
2.如何構造一個安全的物件?
不可變的物件一定是執行緒安全的
在多執行緒訪問這個不可變的物件時,物件的例項域都是固定不變的,也就不存在多執行緒 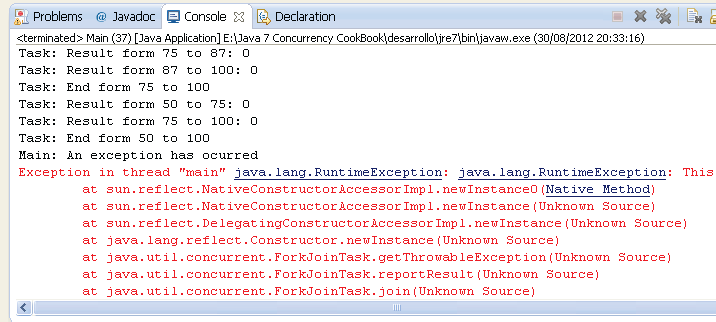
相關推薦
《Java 7併發程式設計實戰手冊》第五章Fork/Join框架
《Java 7併發程式設計實戰手冊》第六章併發集合
《Java 7併發程式設計實戰手冊》第四章執行緒執行器
《Java併發程式設計實戰》—— 第三章 物件的共享
java高階特性與實戰專案 ——第五章: 網路程式設計
java高階特性與實戰專案——第五章-課後作業
《Java並發編程實戰》第五章 同步容器類 讀書筆記
《Java多執行緒程式設計實戰》—— 第9章 Thread Pool(執行緒池)模式
《Java多執行緒程式設計實戰》—— 第8章 Active Object(主動物件)模式
《Java多執行緒程式設計實戰》——第七章Producer-Consumer(生產者/消費者)模式
《Java多執行緒程式設計實戰》——第6章 Promise(承諾)模式
《Java多執行緒程式設計實戰》——第5章 Two-phase Termination(兩階段終止)模式
《Java多執行緒程式設計實戰》——第4章 Guarded Suspension(保護性暫掛)模式
《Java多執行緒程式設計實戰》——第3章 Immutable Object(不可變物件)模式
《Java多執行緒程式設計實戰》——第2章 設計模式及其作用
《Java多執行緒程式設計實戰》——第1章 Java多執行緒程式設計實戰基礎
《Java多執行緒程式設計實戰》—— 第10章 Thread Specific Storage(執行緒特有儲存)模式
Java 7 併發程式設計指南中文版
《Go併發程式設計實戰》第2版 緊跟Go的1.8版本
《JAVA併發程式設計實踐》第三章物件的共享